
What is Anannas ?
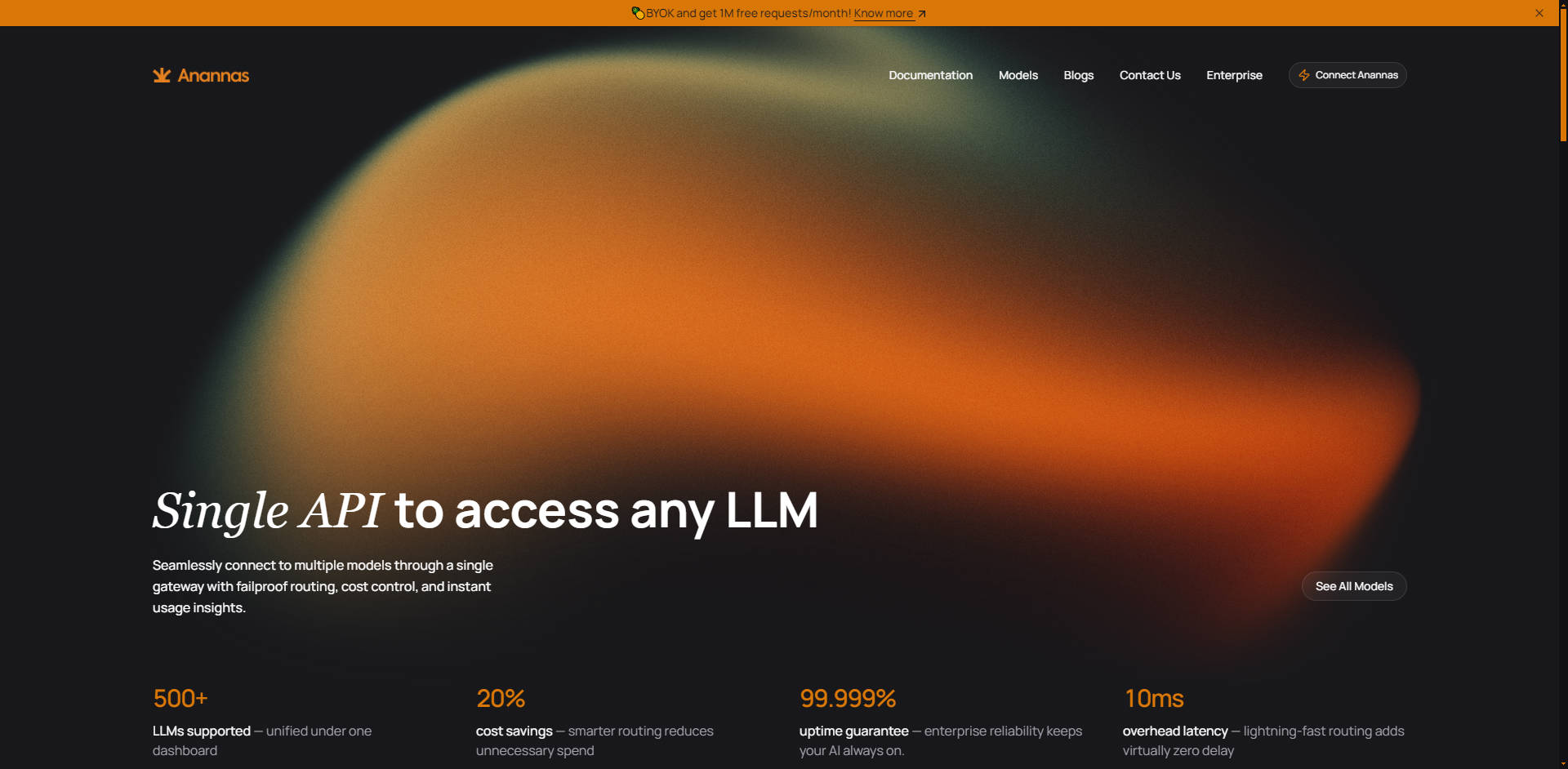
Anannas es la pasarela API unificada diseñada para simplificar y optimizar la interacción de desarrolladores y equipos empresariales con el ecosistema de Modelos de Lenguaje Grandes (LLM) en rápida evolución. Al consolidar el acceso a más de 500 modelos de diversos proveedores —incluidos OpenAI, Anthropic y Google— en una única interfaz de alto rendimiento, Anannas elimina la complejidad de la integración, garantiza la fiabilidad y reduce drásticamente los costes operativos mediante una orquestación inteligente. Si su equipo necesita acceso sin interrupciones, enrutamiento a prueba de fallos y control de costes en tiempo real en múltiples proveedores de LLM, Anannas proporciona la base optimizada que necesita para escalar la IA con confianza.
Características Clave
Anannas ofrece las herramientas esenciales para gestionar despliegues de LLM de múltiples proveedores, centrándose en el rendimiento, la eficiencia de costes y la productividad del desarrollador.
🧠 Enrutamiento Inteligente y Conmutación por Error (Failover): Logre la máxima disponibilidad y eficiencia mediante el balanceo de carga automático y la selección de proveedores. Anannas enruta las solicitudes según sus criterios —ya sea el precio más bajo, la latencia más rápida o el rendimiento más alto— e incluye soporte de respaldo integrado. Si un proveedor preferido falla, el sistema cambia automáticamente a una alternativa saludable sin tiempo de inactividad.
🔗 API Unificada y Compatible con OpenAI: Acceda a más de 500 LLM a través de un único endpoint estandarizado (
/v1/chat/completions) utilizando formatos de autenticación y respuesta consistentes. Esta implementación única reduce drásticamente el tiempo de desarrollo y le permite intercambiar o probar nuevos modelos sin reescribir su código de integración principal.⚙️ Llamada a Herramientas Estandarizada y Salidas Estructuradas: Diseñado para entornos de producción robustos, Anannas estandariza la interfaz de Llamada a Herramientas (function calling) en proveedores como OpenAI y Anthropic, permitiendo una única implementación para múltiples LLM. Además, imponga una validación estricta de esquema JSON en modelos compatibles para garantizar salidas consistentes y seguras en cuanto a tipos, eliminando errores de análisis y mejorando la fiabilidad de la integración posterior.
🚀 Mínima Sobrecarga y Fiabilidad Empresarial: Despliegue con confianza, respaldado por una excepcional garantía de tiempo de actividad del 99.999%. Anannas está diseñado para la velocidad, añadiendo prácticamente cero retraso a sus solicitudes con una latencia de sobrecarga medida de solo 10ms, asegurando que sus aplicaciones de IA permanezcan ultrarrápidas.
🖼️ Soporte Multimodal Continuo: Integre entradas complejas como imágenes, PDFs y audio en sus flujos de trabajo utilizando el mismo endpoint unificado
/chat/completions. Esta capacidad simplifica el desarrollo multimodal, permitiéndole enviar solicitudes de visión (imágenes, PDFs) o utilizar el procesamiento de audio (a través de modelos compatibles como OpenAI) sin necesidad de gestionar APIs separadas.
Casos de Uso
Anannas está específicamente diseñado para resolver los desafíos de complejidad y coste asociados con el despliegue de aplicaciones de IA de misión crítica en entornos dinámicos.
1. Garantizar Salidas Consistentes y Listas para Producción
En escenarios como la extracción automatizada de datos, las comprobaciones de cumplimiento normativo o los flujos complejos de atención al cliente, la inconsistencia es un punto crítico de fallo. Al aprovechar las Salidas Estructuradas, los desarrolladores pueden imponer un esquema JSON estricto, garantizando que cada respuesta del LLM sea legible por máquina y analizable de forma fiable. Esto elimina la necesidad de una lógica de postprocesamiento extensa y mejora enormemente la fiabilidad de las canalizaciones automatizadas.
2. Optimización Dinámica de Costes y Rendimiento
Para aplicaciones de alto volumen, el control de costes es fundamental. Puede configurar el Enrutamiento Inteligente de Anannas para priorizar al proveedor más rentable para una tarea dada, mientras que simultáneamente establece un enrutamiento basado en la latencia para consultas sensibles al tiempo. Esta doble estrategia asegura que reduzca automáticamente el gasto hasta en un 20% en tareas rutinarias, al tiempo que garantiza tiempos de respuesta rápidos para interacciones críticas con el usuario.
3. Agilización del Desarrollo de Aplicaciones Multimodales
Si está construyendo aplicaciones que requieren tanto procesamiento de texto como visual —como el análisis de recibos cargados (PDFs/Imágenes) o la provisión de preguntas y respuestas visuales— Anannas simplifica la integración. En lugar de gestionar APIs separadas para modelos de visión, utiliza un único endpoint unificado, pasando archivos basados en URL o codificados en base64. Esto reduce drásticamente la complejidad de manejar diferentes tipos de datos y formatos específicos de cada proveedor.
Anannas aporta simplicidad, control y rendimiento al complejo mundo del despliegue de múltiples LLM. Al unificar el acceso, garantizar una alta disponibilidad y proporcionar sofisticadas herramientas de optimización de costes, Anannas permite a desarrolladores y equipos centrarse en la creación de aplicaciones de IA innovadoras en lugar de gestionar infraestructuras complejas.
¿Listo para simplificar sus operaciones con LLM? Empiece a integrar con la única pasarela API construida para el futuro de la IA empresarial.
More information on Anannas
Launched
2025-09
Pricing Model
Free Trial
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Anannas was manually vetted by our editorial team and was first featured on 2025-10-29.
Anannas Alternativas
Más Alternativas-

Helicone AI Gateway: Unifica y optimiza tus APIs de LLM para producción. Potencia el rendimiento, reduce costes y garantiza la fiabilidad con enrutamiento inteligente y almacenamiento en caché.
-
TaskingAI aporta la simplicidad de Firebase al desarrollo de aplicaciones nativas de IA. Inicia tu proyecto seleccionando un modelo LLM, desarrolla un asistente responsivo respaldado por APIs con estado, y potencia sus capacidades con memoria gestionada, integraciones de herramientas y un sistema de generación aumentada.
-

-
LLM Gateway: Unifica y optimiza las APIs de LLM de múltiples proveedores. Enruta de forma inteligente, monitoriza los costes y potencia el rendimiento para OpenAI, Anthropic y más. De código abierto.
-
