
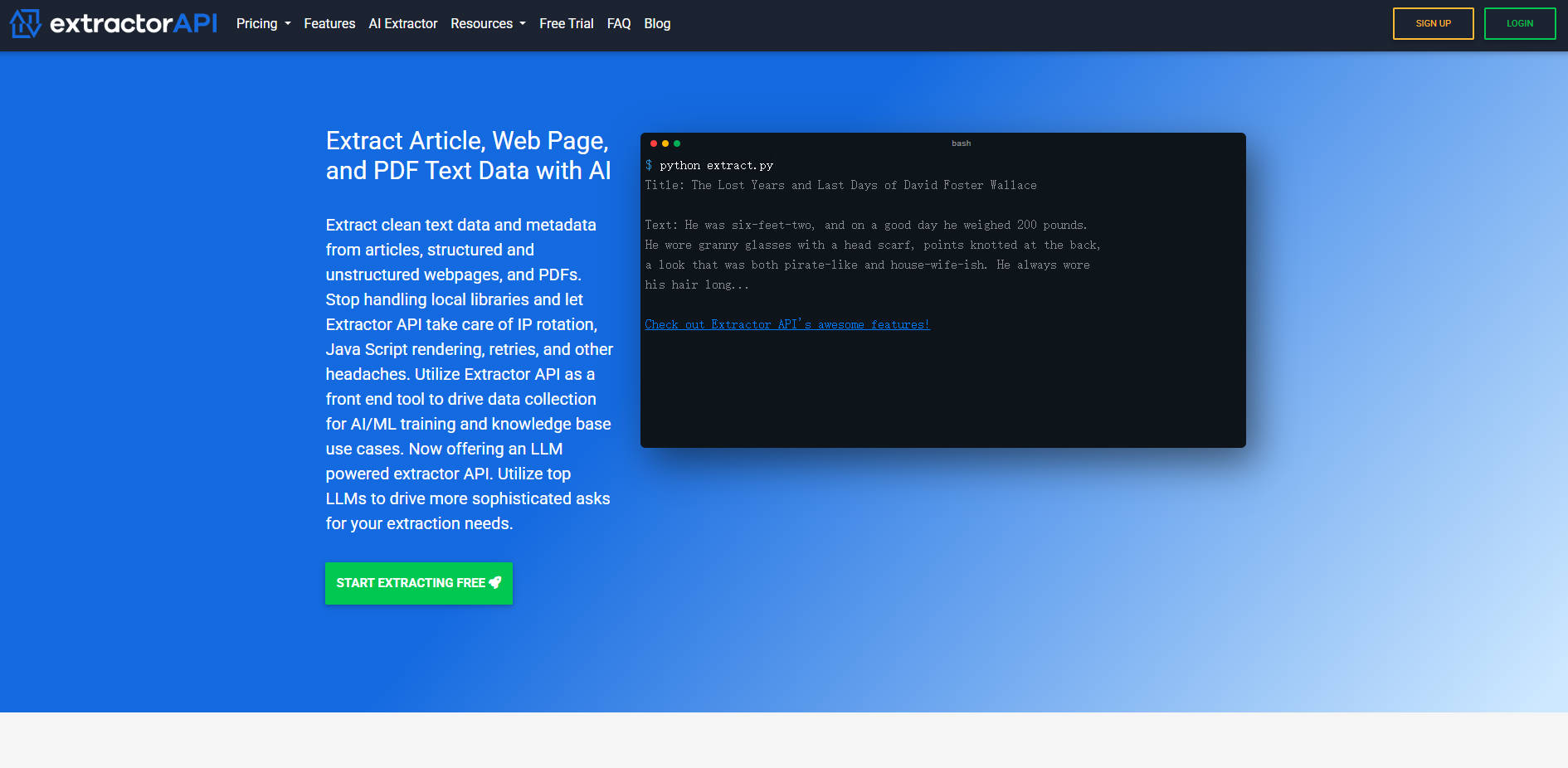
What is Extractor API?
La Extractor API es una plataforma de extracción de texto integral y de alto rendimiento, diseñada para simplificar la recopilación de datos a gran escala. Aborda las complejidades técnicas inherentes al web scraping —como la gestión de la rotación de IP, los reintentos y la representación dinámica de JavaScript— para ofrecer texto limpio y estructurado, así como metadatos valiosos, a partir de artículos, páginas web estructuradas/no estructuradas y documentos PDF. Los equipos de datos, los ingenieros de IA/ML y los creadores de bases de conocimiento pueden confiar en Extractor API para acceder a información previamente inaccesible de manera eficiente y rentable.
Características Clave
🔌 Resistencia Técnica Impecable
Ya no necesita gestionar infraestructuras complejas ni bibliotecas locales. La Extractor API gestiona automáticamente los puntos críticos habituales de la extracción, incluyendo reintentos robustos, rotación continua de IP y la representación necesaria de JavaScript (disponible en los niveles de pago). Esto garantiza una alta fiabilidad y disponibilidad, permitiendo a su equipo concentrarse exclusivamente en la salida de datos, y no en la mecánica de la extracción.
🧠 Extracción Sofisticada Impulsada por LLM
Aproveche el poder de modelos líderes, incluidos OpenAI y Google LLMs, a través de la Extractor API dedicada impulsada por LLM. Esta capacidad va más allá del simple análisis de texto, permitiendo requisitos de extracción sofisticados, una mayor precisión en diversos formatos de páginas web y la capacidad única de "conversar" con las páginas web mediante prompts específicos para extraer información matizada.
📄 Extracción Automatizada de Datos de PDF
Integre fácilmente flujos de trabajo de extracción tanto para documentos locales propietarios como para documentos de acceso público. Esta función automatiza el proceso de extracción de conjuntos de datos clave y texto limpio de PDFs no estructurados, asegurando que la información valiosa oculta en formatos de documentos complejos pueda convertirse rápidamente en datos utilizables.
🔎 API de Búsqueda Global de Noticias
Acceda al panorama mundial de noticias con una única llamada a la API dedicada. La función News Search devuelve hasta 100 resultados relevantes por solicitud, completos con metadatos esenciales, proporcionando una fuente rápida y eficiente para flujos de datos en tiempo real o históricos, cruciales para la inteligencia de mercado y el análisis de tendencias.
🖼️ Herramienta de Extracción Visual para Despliegue Rápido
Para análisis rápidos o flujos de trabajo sin API, la plataforma ofrece una herramienta visual en línea intuitiva. Los usuarios pueden pegar o cargar hasta 1.000 URLs a la vez para una extracción de texto inmediata, guardando los datos limpios resultantes en una página persistente de Jobs para su posterior recuperación en formato CSV o JSON.
Casos de Uso
1. Impulsando Datos de Entrenamiento de IA/ML de Alta Calidad
Los equipos de datos utilizan Extractor API como el primer paso crítico en la construcción de pipelines de datos fiables. Al recopilar texto limpio y estructurado, junto con metadatos, de miles de fuentes, usted garantiza que sus data warehouses y data lakes posteriores reciban material de origen de alta calidad, lo que impulsa un entrenamiento más preciso y un mejor rendimiento para sus modelos de aprendizaje automático.
2. Construyendo Bases de Conocimiento Dinámicas
Ingiera de forma rápida y automática información externa para construir bases de conocimiento exhaustivas. Utilice la función de Extracción de Datos de PDF para extraer hechos y cifras clave de white papers técnicos, informes públicos o documentación, asegurando que sus sistemas de conocimiento internos estén perpetuamente actualizados sin necesidad de entrada manual de datos.
3. QA de Datos Dirigida y Sofisticada
Cuando la extracción estándar falla en páginas complejas y altamente estructuradas (como especificaciones detalladas de productos o resúmenes de investigación), el extractor impulsado por LLM ofrece la solución. Al elegir un LLM deseado y redactar un prompt preciso, puede interactuar con el contenido de la página web de forma programática, asegurando que extrae solo la información exacta y altamente específica requerida, incluso de estructuras de página complicadas.
Conclusión
Extractor API ofrece la robustez y sofisticación necesarias para transformar datos complejos de la web y documentos en inteligencia limpia y accionable. Al gestionar los requisitos técnicos previos y ofrecer herramientas de IA de vanguardia, asegura que sus pipelines de datos sean fiables, eficientes y estén listos para aplicaciones avanzadas.
More information on Extractor API
Launched
2020-03
Pricing Model
Freemium
Starting Price
$33/ month
Global Rank
12055209
Follow
Month Visit
<5k
Tech used
Top 5 Countries
44.64%
36.93%
18.42%
India
France
United States
Traffic Sources
5.75%
1.47%
0.17%
9.98%
53.25%
29.08%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Extractor API was manually vetted by our editorial team and was first featured on 2025-10-31.
Extractor API Alternativas
Más Alternativas-

Parse Extract: Extracción de datos avanzada y OCR para pipelines de LLM. Transforma documentos complejos y datos web en texto limpio, listo para LLM. Rentable y seguro.
-

Extrae sin esfuerzo datos web estructurados de cualquier sitio web utilizando IA. ¡No hace falta código! Define con precisión lo que necesitas mediante prompts y esquemas.
-

Parsera, una plataforma de extracción de datos web impulsada por LLM, le permite extraer todos los datos visibles de cualquier URL mediante instrucciones de lenguaje natural, las cuales luego puede transformar en un script de extracción reutilizable con un solo clic para aplicarlo a miles de páginas con la misma estructura.
-

Extrae datos de cualquier documento no estructurado usando Extracta.ai. Analiza automáticamente documentos escaneados y recupera la información que necesitas.
-
