
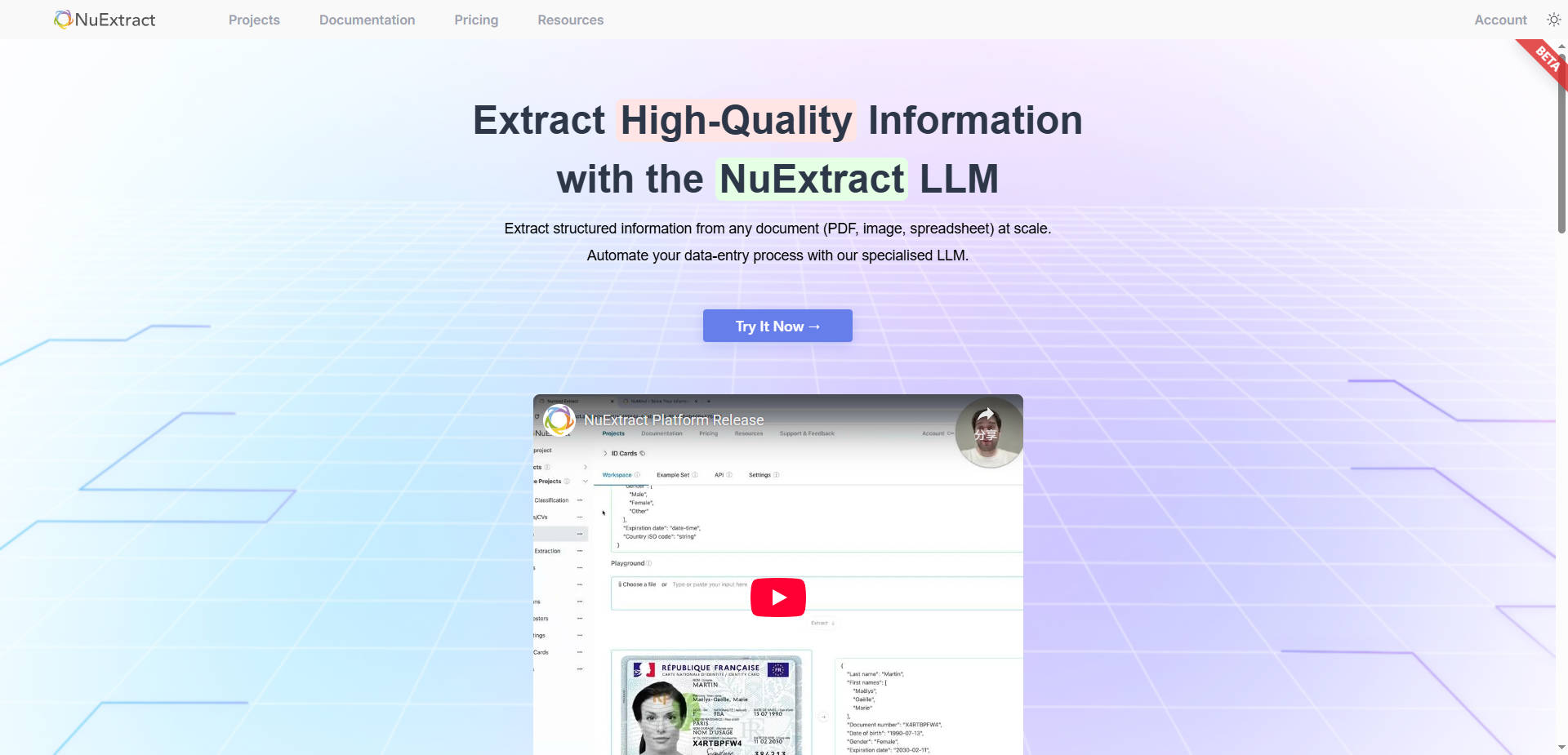
What is NuExtract?
NuExtract es una familia especializada de Grandes Modelos de Lenguaje (LLM) diseñada específicamente para la extracción de información estructurada de documentos con alta precisión. Aborda directamente el costoso desafío manual de procesar datos no estructurados y semiestructurados, automatizando la clasificación, el resumen y la captura de entidades y relaciones complejas de documentos a gran escala. Diseñado para empresas de todos los sectores, NuExtract ofrece la fiabilidad necesaria para automatizar flujos de trabajo críticos de entrada de datos y toma de decisiones.
Características Clave
NuExtract combina una arquitectura de IA avanzada con un manejo robusto de datos para garantizar resultados precisos y accionables a partir de materiales de origen complejos.
📄 Procesamiento de Documentos Multimodal y Versátil NuExtract procesa prácticamente cualquier tipo de documento, incluyendo texto sin formato, imágenes escaneadas y archivos formateados como PDFs, hojas de cálculo y PowerPoints. Para garantizar la fidelidad, los documentos formateados se convierten internamente en imágenes, conservando la información espacial crucial necesaria para analizar con precisión tablas, encabezados y puntos de datos dependientes del diseño.
⚙️ Salida Estructurada Basada en Plantillas Usted define exactamente qué información extraer utilizando una plantilla personalizable, que dicta las entidades, relaciones y estructura de salida requeridas. La información extraída siempre se devuelve en un formato JSON fiable, y cuando se utiliza a través de la plataforma NuExtract, la verificación programática garantiza que la salida se adhiera estrictamente a la plantilla definida.
🛡️ Entrenamiento Especializado para Baja Alucinación A diferencia de los LLM genéricos, NuExtract está específicamente entrenado para la extracción de información, lo que resulta en una fiabilidad superior. Crucialmente, el modelo está diseñado para reconocer la incertidumbre y devolver explícitamente un "valor nulo" o "no lo sé" cuando la información está genuinamente ausente del documento, minimizando drásticamente el riesgo de fabricar (alucinar) datos.
⚡ Mejora Rápida del Rendimiento mediante Ejemplos Logre una precisión lista para producción más rápido proporcionando ejemplos personalizados. El rendimiento de la extracción puede mejorarse sustancialmente suministrando incluso un solo ejemplo de entrada-salida de una extracción correcta, lo que le permite adaptar rápidamente el modelo a los matices de sus tipos de documentos específicos y requisitos de datos.
Casos de Uso
NuExtract permite a las organizaciones transformar procesos complejos basados en documentos en flujos de trabajo totalmente automatizados, reduciendo los costos operativos y acelerando la toma de decisiones.
Relleno de Bases de Datos y Extracción de Entidades
Automatice el tedioso proceso de poblar bases de datos internas. Utilice NuExtract para analizar grandes volúmenes de documentos —como contratos comerciales, facturas o informes de mantenimiento— para extraer entidades específicas (por ejemplo, precios de artículos, cantidades, términos de cláusulas, fechas) y relaciones, asegurando que los datos estructurados estén inmediatamente listos para su almacenamiento y análisis sin intervención manual.
Cumplimiento Normativo y Verificación de Identidad (KYC/KYB)
En industrias reguladas como la Banca y Finanzas, NuExtract procesa rápidamente documentos de identidad, estados financieros y formularios complejos. Puede extraer y verificar información específica de tarjetas de identificación escaneadas o informes financieros, acelerando drásticamente los procesos de Verificación de Identidad (KYC/KYB) mientras mantiene una estricta integridad de los datos y rastros de auditoría.
Clasificación y Triaje de Documentos Empresariales
Agilice las operaciones internas clasificando automáticamente los documentos entrantes, como correos electrónicos de clientes, expedientes legales o reclamaciones de seguros. NuExtract puede categorizar inmediatamente los documentos según su contenido e intención, asegurando que se dirijan al departamento correcto o que activen la acción automática apropiada, mejorando significativamente los tiempos de respuesta y la eficiencia operativa.
Ventajas Únicas
NuExtract no es un LLM de propósito general; es una herramienta especializada construida para la fiabilidad y el rendimiento de la extracción, ofreciendo ventajas distintivas sobre las soluciones genéricas.
Rendimiento de Extracción Superior: NuExtract supera consistentemente a los LLM de vanguardia en los benchmarks de extracción de información. Nuestro entrenamiento especializado asegura una comprensión más profunda y fiable de la estructura y el contenido de los documentos.
Fiabilidad Comprobada: El modelo NuExtract 2.0 PRO ha demostrado superar a GPT-4.1 por más de 9 puntos F-Score en benchmarks de extracción que cubren documentos de texto e imagen, demostrando una ventaja verificable en precisión y recall.
Adherencia Estructurada Garantizada: A través de la plataforma NuExtract, la estructura de salida es verificada y corregida programáticamente contra su plantilla, asegurando que el JSON que recibe sea siempre utilizable para sistemas posteriores, una característica de fiabilidad crítica que a menudo falta en los modelos de propósito general.
Conclusión
NuExtract ofrece la inteligencia especializada y la robusta fiabilidad necesarias para la automatización de documentos de alto riesgo. Al centrarse exclusivamente en la extracción estructurada y ofrecer ventajas de rendimiento verificables, empoderamos a su organización para desbloquear datos críticos atrapados en documentos a gran escala.
More information on NuExtract
Launched
2025-01
Pricing Model
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Top 5 Countries
100%
India
Traffic Sources
100%
direct
Source: Similarweb (Oct 29, 2025)
NuExtract was manually vetted by our editorial team and was first featured on 2025-10-29.
NuExtract Alternativas
Más Alternativas-

LangExtract: biblioteca de Python para la extracción verificable de datos de LLM. Convierte texto no estructurado en datos estructurados, precisos y con fundamento en el origen, en los que puedes confiar.
-

-

Parse Extract: Extracción de datos avanzada y OCR para pipelines de LLM. Transforma documentos complejos y datos web en texto limpio, listo para LLM. Rentable y seguro.
-

Extractor API: Obtén datos limpios y estructurados de cualquier página web, PDF o noticia con IA. Automatiza el web scraping complejo y aprovecha los LLMs para generar perspectivas profundas.
-

DocExtractor utiliza IA para extraer datos de documentos no estructurados de forma precisa y rápida, ahorrando tiempo, minimizando errores y permitiendo tomar decisiones basadas en datos. Procesa diversos formatos, se integra fácilmente y tiene múltiples casos de uso en diferentes industrias.