
What is Turbopuffer?
turbopuffer es un motor de búsqueda de alto rendimiento diseñado para cargas de trabajo de datos empresariales modernas que exigen una escalabilidad masiva sin incurrir en costos de infraestructura prohibitivos. Al depender exclusivamente del almacenamiento de objetos de bajo costo como su única dependencia con estado, turbopuffer combina eficientemente las capacidades de búsqueda vectorial y de texto completo, resolviendo el desafío central de mantener índices a escala de petabytes de forma económica. Diseñada específicamente para clientes B2B y empresariales, esta plataforma ofrece una latencia 'warm' fiable inferior a 10 ms y soporta un robusto aislamiento de datos para entornos multi-inquilino.
Características Clave
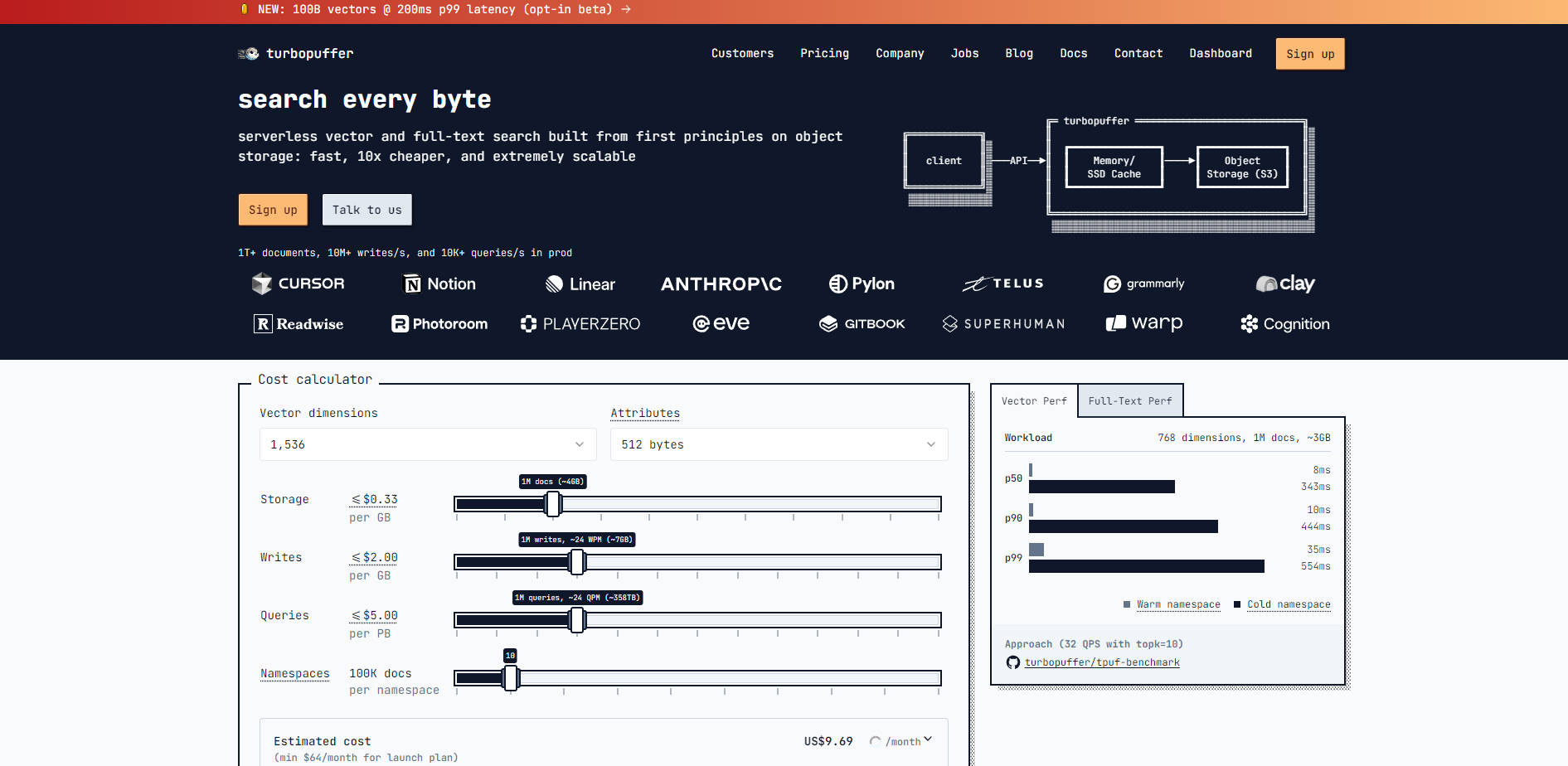
turbopuffer está diseñado para ofrecer tanto rendimiento como eficiencia al separar el cómputo (NVMe SSD y caché de memoria) del estado (almacenamiento de objetos). Esta arquitectura le permite manejar miles de millones de documentos manteniendo los costos bajo control.
🔍 Búsqueda Vectorial y de Texto Completo Unificada
Usted obtiene el poder de la búsqueda híbrida moderna en una única llamada a la API. turbopuffer utiliza un índice de Vecinos Más Cercanos Aproximados (ANN) basado en centroides (SPFresh) para incrustaciones vectoriales y un índice BM25 invertido para la búsqueda por palabras clave. Esta combinación asegura una alta capacidad de recuperación y le permite generar conjuntos robustos de candidatos para procesos de refinamiento posteriores, ofreciendo una relevancia superior de forma inmediata.
☁️ Arquitectura Nativa de Almacenamiento de Objetos
El estado se gestiona exclusivamente en almacenamiento de objetos de bajo costo (como S3 o GCS), permitiendo que el sistema escale horizontalmente a billones de documentos. Los nodos de cómputo utilizan NVMe SSD y caché de memoria, almacenando en caché solo los datos activamente buscados. Este enfoque reduce significativamente los costos de almacenamiento en comparación con los sistemas de disco replicados tradicionales, incluso para espacios de nombres de acceso frecuente.
✅ Fuerte Consistencia y Durabilidad (ACD)
La integridad y fiabilidad de los datos son primordiales. turbopuffer ofrece las propiedades de Atomicidad, Consistencia y Durabilidad (ACD). Las escrituras se confirman inmediatamente en un Write-Ahead Log (WAL) y son duraderas al retornar la API. Por defecto, las consultas posteriores ven la escritura inmediatamente, asegurando una fuerte consistencia, esencial para aplicaciones fiables.
🛡️ Aislamiento y Seguridad de Nivel Empresarial
Diseñado para entornos multi-inquilino B2B, turbopuffer aísla los datos de cada cliente dentro de su propio prefijo de espacio de nombres en el almacenamiento de objetos. Para necesidades empresariales de alta conformidad, soportamos el aislamiento a través de clústeres de un solo inquilino, despliegues Bring Your Own Cloud (BYOC) en su VPC, y Customer Managed Encryption Keys (CMEK), asegurando que usted mantenga el control total sobre sus claves de cifrado de datos.
Casos de Uso
turbopuffer sobresale en escenarios que requieren alto rendimiento, escala masiva y estricto aislamiento de datos, minimizando al mismo tiempo el costo total de propiedad (TCO).
1. Recuperación Eficiente en Primera Etapa
Cuando se trabaja con millones o miles de millones de documentos, es necesario reducir rápidamente el alcance. Utilice la búsqueda híbrida de turbopuffer para generar eficientemente un conjunto de candidatos de decenas o cientos de resultados relevantes. Esta capacidad es crucial para aplicaciones de alta escala que dependen de una segunda etapa de reordenamiento o refinamiento, asegurando que la búsqueda inicial sea rápida y exhaustiva.
2. Gestión de Cargas de Trabajo con Latencia Inferior a 10 ms
Para aplicaciones orientadas al usuario donde la velocidad de búsqueda impacta directamente la experiencia del usuario, turbopuffer le permite aprovechar su impresionante rendimiento en consultas 'warm' (p50=8ms). Puede implementar una estrategia de "precalentamiento" de espacios de nombres críticos o segmentos específicos de datos de usuario con una consulta previa, asegurando que las interacciones de usuario posteriores solo experimenten la baja latencia 'warm'.
3. Almacenamiento y Búsqueda de Datos de Alta Conformidad
Las empresas que manejan información sensible, como la Información de Salud Protegida (PHI), se benefician de la pila de seguridad de turbopuffer. Soportamos Customer Managed Encryption Keys (CMEK) y nos sometemos a auditorías SOC 2 Type 2. Los clientes que requieren cumplimiento HIPAA pueden solicitar un Acuerdo de Asociado Comercial (BAA), proporcionando el marco necesario para un alojamiento de datos seguro y conforme en la región que seleccione.
¿Por Qué Elegir turbopuffer?
La arquitectura única de turbopuffer ofrece distintas ventajas operativas y financieras sobre las bases de datos vectoriales y de búsqueda tradicionales.
Rendimiento Superior y Rentable
turbopuffer está diseñado para ser tan rápido como los motores de búsqueda en memoria cuando los datos están en caché (latencia 'warm' p50 de 8 ms), pero mucho más barato de operar. Al almacenar la mayor parte de sus datos de índice en almacenamiento de objetos de bajo costo en lugar de costosos sistemas de disco replicados, usted reduce drásticamente su huella de almacenamiento general y el gasto en infraestructura.
Optimizado para la Eficiencia del Almacenamiento de Objetos
Nuestras estrategias de indexación están fundamentalmente optimizadas para la economía del almacenamiento en la nube. El índice SPFresh basado en centroides minimiza el número de viajes de ida y vuelta aleatorios y la amplificación de escritura requeridos durante la indexación y la consulta, que son cuellos de botella comunes para los índices basados en grafos (como HNSW o DiskANN) al interactuar con el almacenamiento de objetos de alta latencia. Esta optimización se traduce en arranques en frío más rápidos y menores costos operativos.
Operaciones Simplificadas y Fiabilidad
Al ser el almacenamiento de objetos la única dependencia con estado, las operaciones y el mantenimiento del sistema se simplifican significativamente. Esta arquitectura mejora la fiabilidad y la alta disponibilidad (HA), ya que cualquier nodo de consulta puede servir datos instantáneamente para cualquier espacio de nombres. Además, el sistema está diseñado para manejar escrituras pesadas (adiciones, actualizaciones y eliminaciones) con un alto rendimiento (~10,000+ vectores/seg), asegurando que su índice permanezca actualizado y consistente.
Conclusión
turbopuffer ofrece la velocidad y escalabilidad exigidas por las aplicaciones de búsqueda empresarial más intensivas, reduciendo fundamentalmente el costo total de propiedad gracias a su diseño centrado en el almacenamiento de objetos. Si necesita una búsqueda híbrida robusta, fuerte consistencia y escalabilidad masiva para datos multi-inquilino, turbopuffer le proporciona la base fiable y rentable que necesita.
More information on Turbopuffer
Launched
2023-05
Pricing Model
Paid
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Turbopuffer was manually vetted by our editorial team and was first featured on 2025-11-02.
Turbopuffer Alternativas
Más Alternativas-

-
-

Turso es una plataforma de bases de datos que toma el motor de base de datos incrustado libSQL y lo adapta para aplicaciones distribuidas a escala de producción. Añade capacidades como replicación, ramificación, recuperación en un punto específico del tiempo, búsqueda vectorial nativa y gestión programática a través de una API, al tiempo que conserva la familiar experiencia de desarrollador de SQLite.
-

-

TurboSeek es un motor de búsqueda impulsado por IA, que aprovecha la API de Bing y modelos avanzados. Ofrece comprensión del lenguaje natural, resultados avanzados, velocidad, preguntas relacionadas y colaboración de código abierto. Ideal para investigación, resolución de problemas técnicos y creación de contenido.