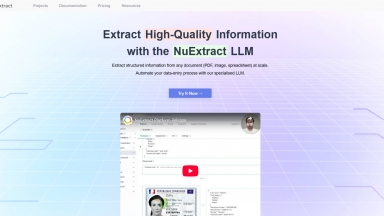
 NuExtract
NuExtract
 Unstract
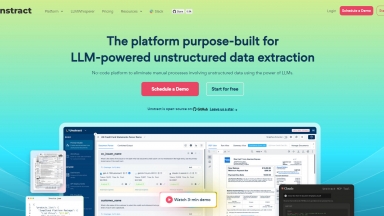
Unstract
NuExtract
| Launched | 2025-01 |
| Pricing Model | |
| Starting Price | |
| Tech used | |
| Tag |
Unstract
| Launched | 2023-08 |
| Pricing Model | Freemium |
| Starting Price | |
| Tech used | WordPress,Elementor,Bootstrap,animate.css,Clipboard.js,Font Awesome,Google Analytics,Google Font API,Google Tag Manager,HubSpot Analytics,Linkedin Insight Tag,Prism,Slick,Swiper Slider,jQuery,jQuery Migrate |
| Tag | Data Extraction,Workflow Automation,Data Integration |
NuExtract Rank/Visit
| Global Rank | |
| Country | India |
| Month Visit | 186 |
Top 5 Countries
Traffic Sources
Unstract Rank/Visit
| Global Rank | 451302 |
| Country | United States |
| Month Visit | 74544 |
Top 5 Countries
Traffic Sources
Estimated traffic data from Similarweb
What are some alternatives?
LangExtract - LangExtract : Bibliothèque Python pour l'extraction vérifiable de données de LLM. Convertissez le texte non structuré en données structurées, précises, ancrées dans leur source et dignes de confiance.
Parse Extract - Parse Extract : Extraction de données avancée et OCR pour les pipelines de LLM. Transformez des documents complexes et des données web en un texte épuré et optimisé pour les LLM. Rentable et sécurisé.
Extractor API - Extractor API : Obtenez des données propres et structurées depuis n'importe quelle page web, PDF ou source d'actualités, grâce à l'IA. Automatisez le web scraping complexe et tirez parti des LLMs pour des analyses approfondies.
DocExtractor - DocExtractor utilise l'IA pour extraire des données de documents non structurés de manière précise et rapide, ce qui permet de gagner du temps, de réduire les erreurs et de prendre des décisions basées sur les données. Il traite divers formats, s'intègre facilement et offre de nombreux cas d'utilisation dans différents secteurs.