
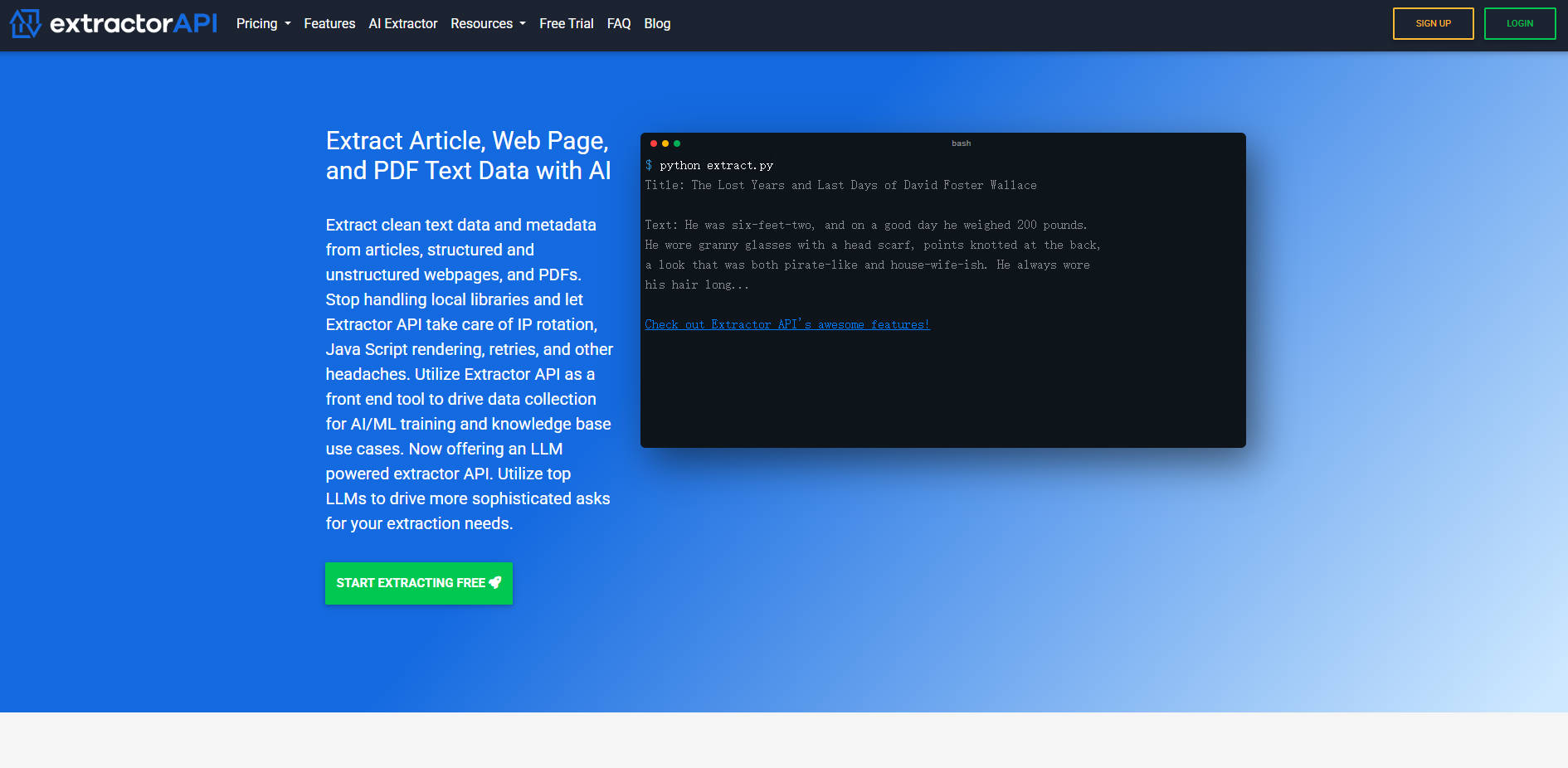
What is Extractor API?
L' Extractor API est une plateforme d'extraction de texte complète et hautement performante, conçue pour simplifier la collecte de données à grande échelle. Elle s'attaque aux complexités techniques inhérentes au web scraping — telles que la gestion de la rotation des adresses IP, les tentatives de reconnexion et le rendu dynamique de JavaScript — pour fournir un texte propre et structuré, ainsi que des métadonnées précieuses issues d'articles, de pages web structurées/non structurées et de PDF. Les équipes de données, les ingénieurs en IA/ML et les créateurs de bases de connaissances peuvent compter sur Extractor API pour accéder à des informations auparavant inaccessibles, de manière efficace et économique.
Fonctionnalités Clés
🔌 Résilience Technique Sans Faille
Vous n'avez plus besoin de gérer d'infrastructures complexes ou de bibliothèques locales. L' Extractor API gère automatiquement les problématiques courantes de l'extraction, y compris les tentatives de reconnexion robustes, la rotation continue des adresses IP et le rendu JavaScript nécessaire (disponible sur les offres payantes). Cela garantit une fiabilité et une disponibilité élevées, permettant à votre équipe de se concentrer uniquement sur les données extraites, et non sur les mécanismes d'extraction.
🧠 Extraction Sophistiquée Pilotée par les LLM
Exploitez la puissance des modèles de pointe, y compris les LLM d'OpenAI et de Google, grâce à l' Extractor API dédiée et alimentée par des LLM. Cette capacité dépasse la simple analyse syntaxique de texte, permettant des exigences d'extraction sophistiquées, une précision accrue sur divers formats de pages web, et la capacité unique d'interagir avec les pages web via des invites ciblées pour extraire des informations nuancées.
📄 Extraction Automatisée de Données PDF
Intégrez facilement des flux de travail d'extraction pour les documents locaux propriétaires et les documents accessibles au public. Cette fonctionnalité automatise le processus d'extraction de jeux de données clés et de texte propre à partir de PDF non structurés, garantissant que les informations précieuses contenues dans des formats de documents complexes peuvent être rapidement converties en données utilisables.
🔎 API de Recherche Mondiale News Search
Accédez au paysage mondial de l'actualité avec un seul appel API dédié. La fonction News Search renvoie jusqu'à 100 résultats pertinents par requête, avec des métadonnées essentielles, offrant une source rapide et efficace pour les flux de données en temps réel ou historiques, cruciaux pour la veille concurrentielle et l'analyse des tendances.
🖼️ Outil d'Extraction Visuel pour un Déploiement Rapide
Pour une analyse rapide ou des flux de travail non basés sur des API, la plateforme propose un outil visuel en ligne intuitif. Les utilisateurs peuvent coller ou télécharger jusqu'à 1 000 URL à la fois pour une extraction de texte immédiate, enregistrant les données propres obtenues sur une page Jobs persistante pour une récupération ultérieure au format CSV ou JSON.
Cas d'Utilisation
1. Alimenter les Données d'Entraînement IA/ML de Haute Qualité
Les équipes de données utilisent Extractor API comme première étape cruciale dans la construction de pipelines de données fiables. En collectant du texte propre et structuré ainsi que des métadonnées provenant de milliers de sources, vous assurez que vos entrepôts de données (data warehouses) et vos lacs de données (data lakes) reçoivent des matériaux sources de haute qualité, ce qui favorise une formation plus précise et une meilleure performance de vos modèles d'apprentissage automatique.
2. Construire des Bases de Connaissances Dynamiques
Ingérez rapidement et automatiquement des informations externes pour construire des bases de connaissances complètes. Utilisez la fonction PDF Data Extraction pour extraire des faits et chiffres clés de livres blancs techniques, de rapports publics ou de documentation, garantissant que vos systèmes de connaissances internes sont perpétuellement à jour sans saisie manuelle de données.
3. Assurance Qualité des Données Ciblée et Sophistiquée
Lorsque l'extraction standard échoue sur des pages complexes et hautement structurées (comme des spécifications de produits détaillées ou des résumés de recherche), l'extracteur alimenté par les LLM offre la solution. En choisissant le LLM souhaité et en rédigeant une invite précise, vous pouvez interagir avec le contenu de la page web de manière programmatique, vous assurant de n'extraire que les informations exactes et très spécifiques requises, même à partir de structures de pages complexes.
Conclusion
L' Extractor API offre la robustesse et la sophistication nécessaires pour transformer des données web et documentaires complexes en une intelligence propre et exploitable. En gérant les prérequis techniques et en proposant des outils d'IA de pointe, elle garantit que vos pipelines de données sont fiables, efficaces et prêts pour les applications avancées.
More information on Extractor API
Launched
2020-03
Pricing Model
Freemium
Starting Price
$33/ month
Global Rank
12055209
Follow
Month Visit
<5k
Tech used
Top 5 Countries
44.64%
36.93%
18.42%
India
France
United States
Traffic Sources
5.75%
1.47%
0.17%
9.98%
53.25%
29.08%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Extractor API was manually vetted by our editorial team and was first featured on 2025-10-31.
Extractor API Alternatives
Plus Alternatives-

Parse Extract : Extraction de données avancée et OCR pour les pipelines de LLM. Transformez des documents complexes et des données web en un texte épuré et optimisé pour les LLM. Rentable et sécurisé.
-

Extrayez les données web structurées de n'importe quel site en toute simplicité, grâce à l'IA. Aucun code requis ! Définissez précisément vos besoins à l'aide de prompts et de schémas.
-

Parsera, une plateforme d'extraction de données web propulsée par un LLM, vous permet d'extraire toutes les données visibles de n'importe quelle URL en utilisant des instructions en langage naturel. Ensuite, d'un simple clic, vous pouvez transformer ces instructions en un script de scraping réutilisable pour l'appliquer à des milliers de pages de structure identique.
-

Avec Extracta.ai, extrayez des données depuis n'importe quel document non structuré. Analysez automatiquement les documents numérisés et récupérez les informations dont vous avez besoin.
-
