
What is NuExtract?
NuExtract est une famille spécialisée de Grands Modèles Linguistiques (LLM) conçue spécifiquement pour l'extraction d'informations structurées de haute précision à partir de documents. Elle répond directement au défi coûteux et manuel du traitement des données non structurées et semi-structurées en automatisant la classification, la synthèse et la capture d'entités et de relations complexes à partir de documents, et ce, à grande échelle. Conçu pour les entreprises de tous les secteurs d'activité, NuExtract offre la fiabilité nécessaire pour automatiser les flux de travail critiques liés à la saisie de données et à la prise de décision.
Fonctionnalités Clés
NuExtract combine une architecture d'IA avancée avec une gestion robuste des données afin de garantir une production précise et exploitable à partir de matériaux sources complexes.
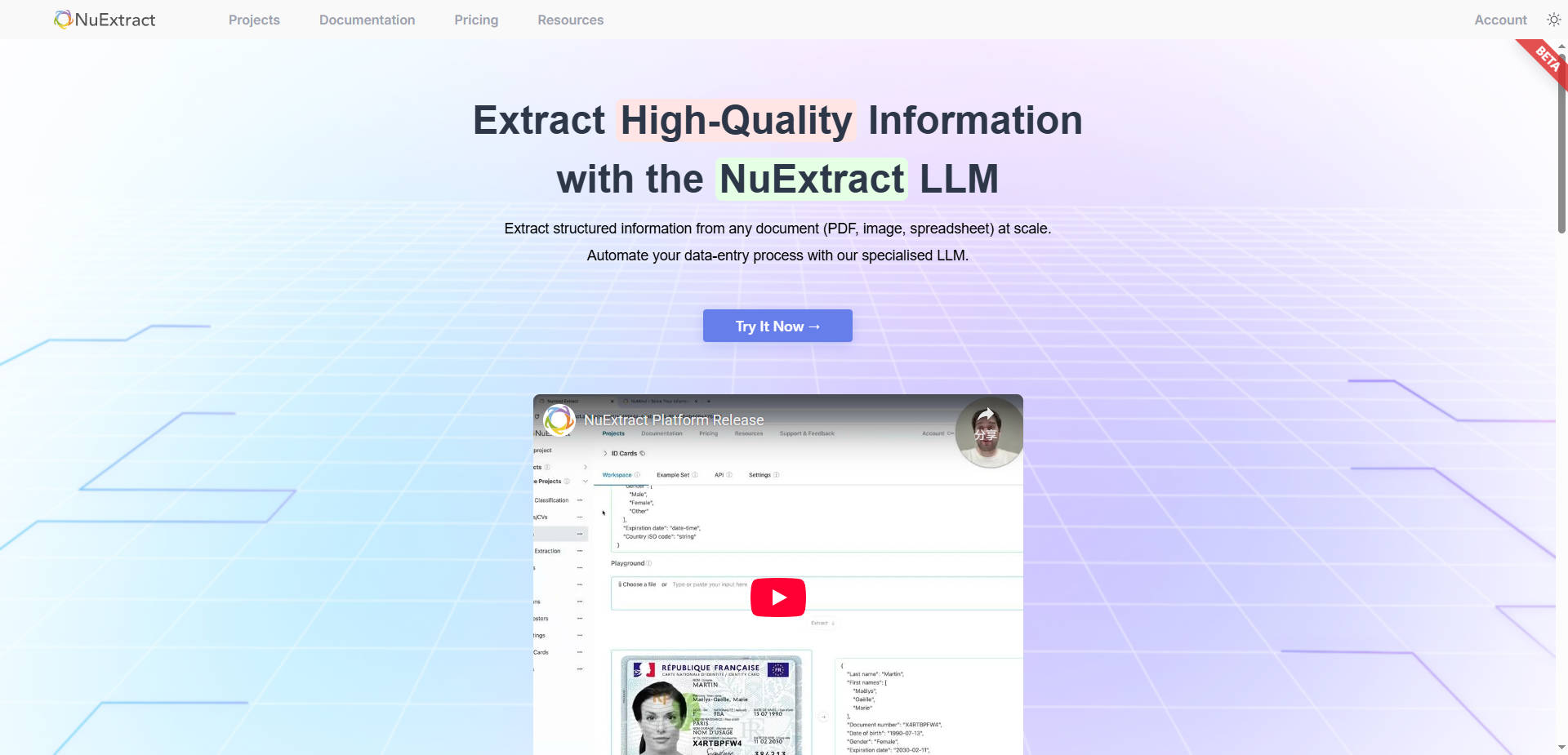
📄 Traitement Multimodal et Polyvalent des Documents NuExtract traite pratiquement tout type de document, y compris le texte brut, les images numérisées et les fichiers formatés tels que les PDF, les feuilles de calcul et les PowerPoints. Afin de garantir la fidélité, les documents formatés sont convertis en images en interne, conservant ainsi les informations spatiales cruciales nécessaires à l'analyse précise des tableaux, des en-têtes et des points de données dépendants de la mise en page.
⚙️ Sortie Structurée Basée sur des Modèles Vous définissez précisément les informations à extraire à l'aide d'un modèle personnalisable, qui dicte les entités, les relations et la structure de sortie requises. Les informations extraites sont toujours renvoyées dans un format JSON fiable, et lorsqu'elles sont utilisées via la plateforme NuExtract, une vérification programmatique garantit que la sortie adhère strictement au modèle défini.
🛡️ Formation Spécialisée pour une Faible Hallucination Contrairement aux LLM génériques, NuExtract est spécifiquement entraîné pour l'extraction d'informations, ce qui se traduit par une fiabilité supérieure. De manière cruciale, le modèle est conçu pour reconnaître l'incertitude et renvoyer explicitement une "valeur nulle" ou "Je ne sais pas" lorsque l'information est réellement absente du document, minimisant ainsi considérablement le risque de fabriquer (halluciner) des données.
⚡ Amélioration Rapide des Performances par l'Exemple Atteignez plus rapidement une précision prête pour la production en fournissant des exemples personnalisés. Les performances d'extraction peuvent être considérablement améliorées en fournissant ne serait-ce qu'un seul exemple d'entrée-sortie d'une extraction correcte, vous permettant d'adapter rapidement le modèle aux nuances de vos types de documents et exigences de données spécifiques.
Cas d'Utilisation
NuExtract permet aux organisations de transformer des processus complexes et axés sur les documents en flux de travail entièrement automatisés, réduisant les coûts opérationnels et accélérant la prise de décision.
Remplissage de Bases de Données et Extraction d'Entités
Automatisez le processus fastidieux de remplissage des bases de données internes. Utilisez NuExtract pour analyser de grands volumes de documents — tels que des contrats commerciaux, des factures ou des rapports de maintenance — afin d'extraire des entités spécifiques (par exemple, prix des articles, quantités, termes de clauses, dates) et des relations, garantissant que les données structurées sont immédiatement prêtes pour le stockage et l'analyse, sans saisie manuelle.
Conformité Réglementaire et Vérification d'Identité (KYC/KYB)
Dans les secteurs réglementés tels que la Banque et la Finance, NuExtract traite rapidement les documents d'identité, les états financiers et les formulaires complexes. Il peut extraire et vérifier des informations spécifiques à partir de cartes d'identité numérisées ou de rapports financiers, accélérant considérablement les processus de vérification d'identité (KYC/KYB) tout en maintenant une intégrité stricte des données et des pistes d'audit.
Triage et Classification de Documents d'Entreprise
Rationalisez les opérations internes en classifiant automatiquement les documents entrants, tels que les e-mails clients, les dossiers juridiques ou les demandes d'assurance. NuExtract peut immédiatement catégoriser les documents en fonction de leur contenu et de leur intention, garantissant qu'ils sont acheminés vers le bon service ou qu'ils déclenchent l'action automatique appropriée, améliorant ainsi considérablement les temps de réponse et l'efficacité opérationnelle.
Avantages Distinctifs
NuExtract n'est pas un LLM à usage général ; c'est un outil spécialisé conçu pour la fiabilité et la performance de l'extraction, offrant des avantages distincts par rapport aux solutions génériques.
Performances d'Extraction Supérieures : NuExtract surpasse constamment les LLM de pointe lors des bancs d'essai d'extraction d'informations. Notre formation spécialisée garantit une compréhension plus approfondie et plus fiable de la structure et du contenu des documents.
Fiabilité Avérée : Le modèle NuExtract 2.0 PRO a démontré des performances supérieures à celles de GPT-4.1 de plus de 9 points F-Score lors de bancs d'essai d'extraction couvrant des documents texte et image, prouvant ainsi une avance vérifiable en matière de précision et de rappel.
Adhérence Structurelle Garantie : Grâce à la plateforme NuExtract, la structure de sortie est vérifiée et corrigée de manière programmatique par rapport à votre modèle, garantissant que le JSON que vous recevez est toujours utilisable par les systèmes en aval — une fonctionnalité de fiabilité essentielle souvent absente des modèles à usage général.
Conclusion
NuExtract offre l'intelligence spécialisée et la fiabilité robuste nécessaires à l'automatisation des documents à enjeux élevés. En se concentrant exclusivement sur l'extraction structurée et en offrant des avantages de performance vérifiables, nous permettons à votre organisation de déverrouiller des données critiques piégées dans les documents, et ce, à grande échelle.
More information on NuExtract
Launched
2025-01
Pricing Model
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Top 5 Countries
100%
India
Traffic Sources
100%
direct
Source: Similarweb (Oct 29, 2025)
NuExtract was manually vetted by our editorial team and was first featured on 2025-10-29.
NuExtract Alternatives
Plus Alternatives-

LangExtract : Bibliothèque Python pour l'extraction vérifiable de données de LLM. Convertissez le texte non structuré en données structurées, précises, ancrées dans leur source et dignes de confiance.
-

-

Parse Extract : Extraction de données avancée et OCR pour les pipelines de LLM. Transformez des documents complexes et des données web en un texte épuré et optimisé pour les LLM. Rentable et sécurisé.
-

Extractor API : Obtenez des données propres et structurées depuis n'importe quelle page web, PDF ou source d'actualités, grâce à l'IA. Automatisez le web scraping complexe et tirez parti des LLMs pour des analyses approfondies.
-

DocExtractor utilise l'IA pour extraire des données de documents non structurés de manière précise et rapide, ce qui permet de gagner du temps, de réduire les erreurs et de prendre des décisions basées sur les données. Il traite divers formats, s'intègre facilement et offre de nombreux cas d'utilisation dans différents secteurs.