
What is Turbopuffer?
turbopuffer est un moteur de recherche haute performance conçu pour les charges de travail de données d'entreprise modernes qui exigent une mise à l'échelle massive sans coûts d'infrastructure prohibitifs. En s'appuyant de manière unique sur un stockage objet à faible coût comme seule dépendance d'état, turbopuffer combine efficacement les capacités de recherche vectorielle et de texte intégral, résolvant le défi majeur du maintien d'indices à l'échelle du pétaoctet de manière économique. Conçue spécifiquement pour les clients B2B et les entreprises, cette plateforme offre une latence "à chaud" fiable, inférieure à 10 ms, et prend en charge une isolation robuste des données pour les environnements multi-locataires.
Principales Fonctionnalités
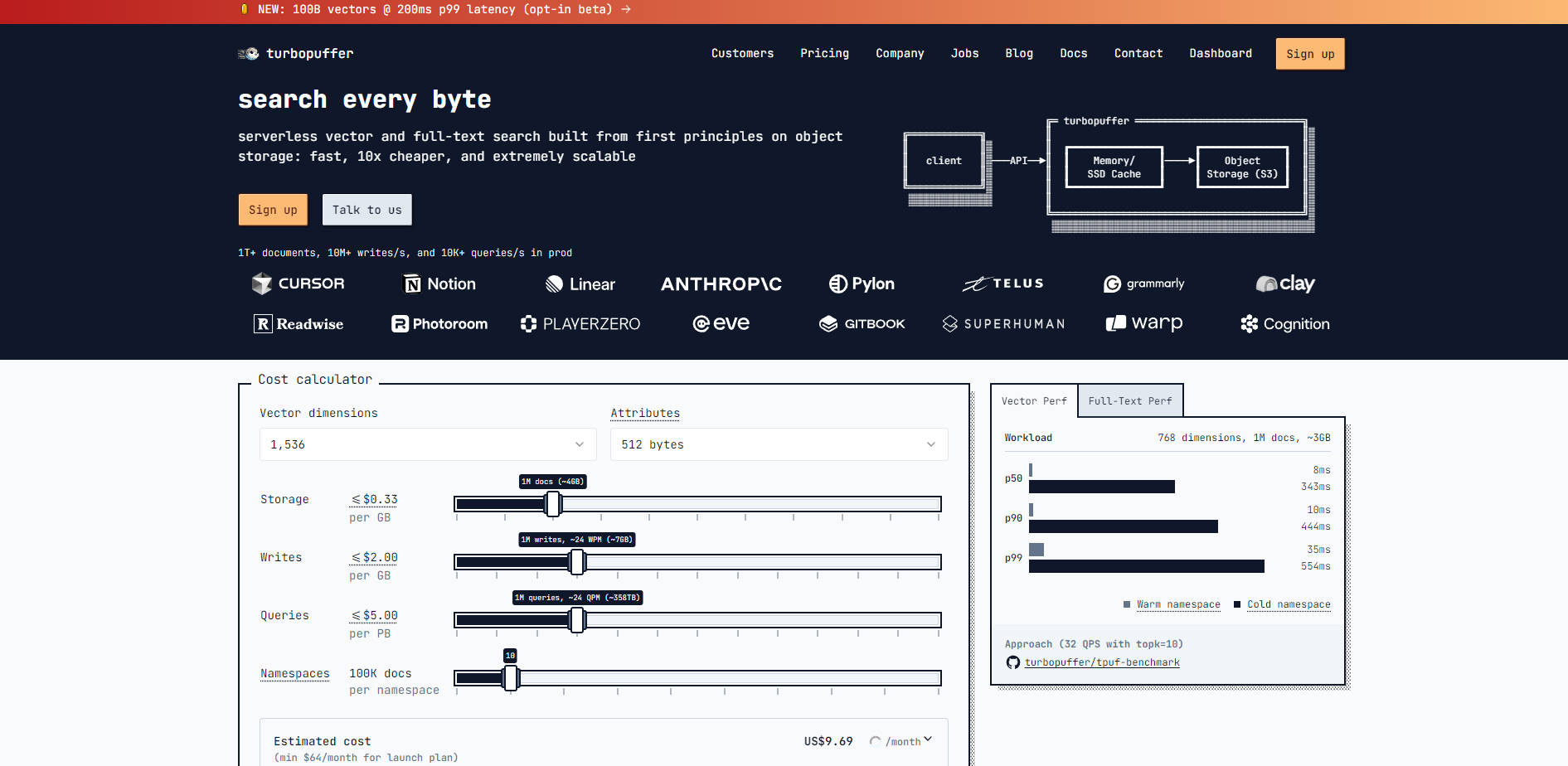
turbopuffer est conçu pour offrir à la fois performance et efficacité en séparant le calcul (NVMe SSD et cache mémoire) de l'état (stockage objet). Cette architecture vous permet de gérer des milliards de documents tout en maîtrisant les coûts.
🔍 Recherche Vectorielle et Texte Intégral Unifiée
Vous bénéficiez de la puissance de la recherche hybride moderne en un seul appel d'API. turbopuffer utilise un index ANN (Approximate Nearest Neighbour) basé sur les centroïdes (SPFresh) pour les plongements vectoriels et un index inversé BM25 pour la recherche par mots-clés. Cette combinaison garantit un rappel élevé et vous permet de générer des ensembles de candidats robustes pour les processus d'affinage ultérieurs, offrant une pertinence supérieure dès la première utilisation.
☁️ Architecture Native du Stockage Objet
L'état est géré exclusivement dans un stockage objet à faible coût (comme S3 ou GCS), permettant au système de s'étendre horizontalement à des billions de documents. Les nœuds de calcul utilisent un NVMe SSD et un cache mémoire, ne mettant en cache que les données activement recherchées. Cette approche réduit considérablement les coûts de stockage par rapport aux systèmes de disques répliqués traditionnels, même pour les espaces de noms fréquemment accédés.
✅ Forte Cohérence et Durabilité (ACD)
L'intégrité et la fiabilité des données sont primordiales. turbopuffer offre les propriétés d'Atomicité, de Cohérence et de Durabilité (ACD). Les écritures sont immédiatement validées dans un journal de pré-écriture (WAL) et sont durables dès le retour de l'API. Par défaut, les requêtes suivantes voient l'écriture immédiatement, assurant une forte cohérence essentielle pour les applications fiables.
🛡️ Isolation et Sécurité de Niveau Entreprise
Conçu pour la multi-location B2B, turbopuffer isole les données de chaque client dans son propre préfixe d'espace de noms sur le stockage objet. Pour les besoins d'entreprise à haute conformité, nous prenons en charge l'isolation via des clusters mono-locataires, le déploiement Bring Your Own Cloud (BYOC) dans votre VPC, et les clés de chiffrement gérées par le client (CMEK), vous garantissant de garder un contrôle total sur vos clés de chiffrement de données.
Cas d'Utilisation
turbopuffer excelle dans les scénarios nécessitant un débit élevé, une mise à l'échelle massive et une isolation stricte des données tout en minimisant le coût total de possession (CTP).
1. Récupération Efficace de Première Étape
Lorsque vous traitez des millions ou des milliards de documents, vous devez rapidement affiner la portée. Utilisez la recherche hybride de turbopuffer pour générer efficacement un ensemble de candidats de dizaines ou de centaines de résultats pertinents. Cette capacité est cruciale pour les applications à grande échelle qui s'appuient sur une deuxième étape de re-classement ou d'affinage, garantissant que la recherche initiale est à la fois rapide et exhaustive.
2. Gestion des Charges de Travail avec une Latence Inférieure à 10 ms
Pour les applications destinées aux utilisateurs, où la vitesse de recherche a un impact direct sur l'expérience utilisateur, turbopuffer vous permet de tirer parti de ses performances de requête "à chaud" impressionnantes (p50=8ms). Vous pouvez mettre en œuvre une stratégie de "pré-chauffage" des espaces de noms critiques ou de segments de données utilisateur spécifiques avec une requête de pré-vol, garantissant que les interactions utilisateur ultérieures ne connaissent que la faible latence "à chaud".
3. Stockage et Recherche de Données en Contexte de Haute Conformité
Les entreprises traitant des informations sensibles, telles que les informations de santé protégées (PHI), bénéficient de la pile de sécurité de turbopuffer. Nous prenons en charge les clés de chiffrement gérées par le client (CMEK) et sommes soumis à des audits SOC 2 Type 2. Les clients exigeant la conformité HIPAA peuvent demander un accord de partenariat commercial (BAA), fournissant le cadre nécessaire pour un hébergement de données sécurisé et conforme dans la région que vous sélectionnez.
Pourquoi Choisir turbopuffer ?
L'architecture unique de turbopuffer offre des avantages opérationnels et financiers distincts par rapport aux bases de données de recherche et vectorielles traditionnelles.
Performance Optimale à Coût Maîtrisé
turbopuffer est conçu pour être aussi rapide que les moteurs de recherche en mémoire lorsque les données sont mises en cache (latence "à chaud" p50 de 8 ms), mais beaucoup moins coûteux à exploiter. En stockant la grande majorité de vos données d'index dans un stockage objet à faible coût plutôt que dans des systèmes de disques répliqués coûteux, vous réduisez drastiquement votre empreinte de stockage globale et vos dépenses d'infrastructure.
Optimisé pour l'Efficacité du Stockage Objet
Nos stratégies d'indexation sont fondamentalement optimisées pour l'économie du stockage cloud. L'index SPFresh basé sur les centroïdes minimise le nombre d'allers-retours aléatoires et l'amplification d'écriture requis lors de l'indexation et de l'interrogation, qui sont des goulots d'étranglement courants pour les index basés sur des graphes (comme HNSW ou DiskANN) lorsqu'ils interagissent avec un stockage objet à haute latence. Cette optimisation se traduit par des démarrages "à froid" plus rapides et des coûts opérationnels réduits.
Opérations Simplifiées et Fiabilité Accrue
Le stockage objet étant la seule dépendance d'état, les opérations et la maintenance du système sont considérablement simplifiées. Cette architecture améliore la fiabilité et la haute disponibilité (HA), car tout nœud de requête peut instantanément servir des données pour n'importe quel espace de noms. De plus, le système est conçu pour gérer des écritures lourdes (ajouts, mises à jour et suppressions) avec un débit élevé (~10 000+ vecteurs/sec), garantissant que votre index reste à jour et cohérent.
Conclusion
turbopuffer offre la vitesse et la scalabilité exigées par les applications de recherche d'entreprise les plus intensives tout en réduisant fondamentalement le coût total de possession grâce à sa conception centrée sur le stockage objet. Si vous avez besoin d'une recherche hybride robuste, d'une forte cohérence et d'une scalabilité massive pour des données multi-locataires, turbopuffer vous offre la fondation fiable et rentable dont vous avez besoin.
More information on Turbopuffer
Launched
2023-05
Pricing Model
Paid
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Turbopuffer was manually vetted by our editorial team and was first featured on 2025-11-02.
Turbopuffer Alternatives
Plus Alternatives-

-
-

Turso est une plateforme de base de données qui exploite le moteur de base de données embarqué libSQL et l'adapte pour les applications distribuées de niveau production. Elle intègre des fonctionnalités telles que la réplication, la gestion des branches, la récupération à un instant précis, la recherche vectorielle native et la gestion programmatique via une API, tout en conservant l'expérience développeur familière de SQLite.
-

-

TurboSeek est un moteur de recherche alimenté par l'IA, s'appuyant sur l'API Bing et des modèles avancés. Il offre une compréhension du langage naturel, des résultats avancés, de la vitesse, des questions connexes et une collaboration open source. Idéal pour la recherche, la résolution de problèmes techniques et la création de contenu.