
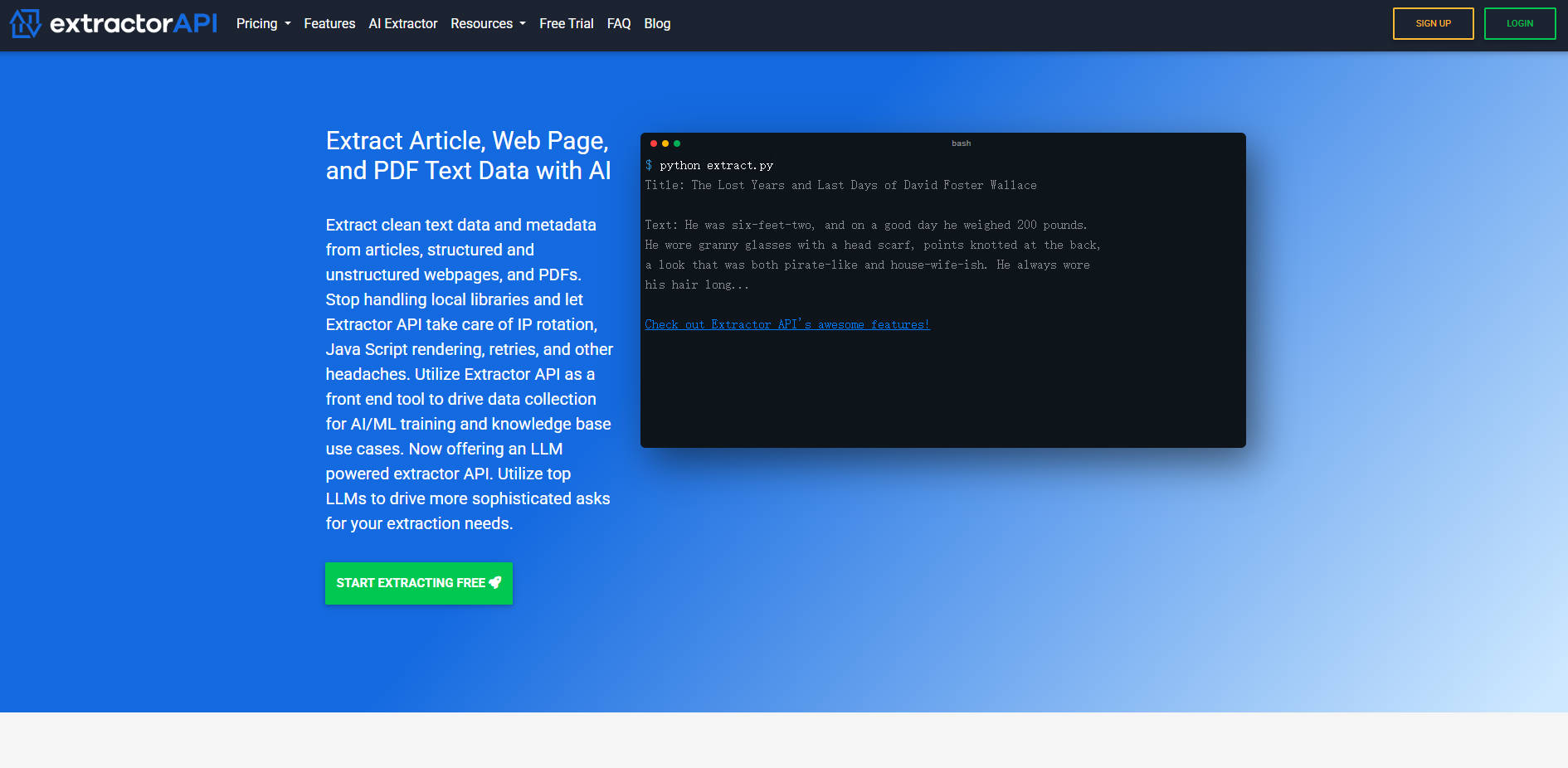
What is Extractor API?
The Extractor APIは、大規模なデータ収集を簡素化するために設計された、包括的で高性能なテキスト抽出プラットフォームです。IPローテーションの管理、再試行処理、動的なJavaScriptレンダリングといったウェブスクレイピング固有の技術的複雑さを解消し、記事、構造化/非構造化されたウェブページ、PDFから、クリーンで構造化されたテキストと貴重なメタデータを提供します。データチーム、AI/MLエンジニア、ナレッジベース作成者は、Extractor APIを活用することで、これまでアクセスが困難だった情報に効率的かつ費用対効果高くアクセスできます。
主な機能
🔌 シームレスな技術的堅牢性
複雑なインフラストラクチャやローカルライブラリを管理する必要はもうありません。The Extractor APIは、堅牢な再試行処理、継続的なIPローテーション、必要なJavaScriptレンダリング(有料プランで利用可能)といった、抽出における一般的な課題を自動的に処理します。これにより、高い信頼性と可用性が保証され、チームは抽出の仕組みではなく、データ出力にのみ集中できます。
🧠 LLMによる高度な抽出
専用のLLM搭載 Extractor APIを通じて、OpenAIやGoogle LLMsを含む主要モデルの能力を活用できます。この機能は、単なるテキスト解析を超え、高度な抽出要件に対応し、多様なウェブページ形式で高い精度を実現します。さらに、ターゲットとなるプロンプトを介してウェブページと「対話」することで、微妙なニュアンスの情報まで引き出す独自の能力を備えています。
📄 PDFデータ抽出の自動化
企業独自のローカル文書と公開されている文書の両方で、抽出ワークフローを容易に統合できます。この機能は、非構造化PDFから主要なデータセットとクリーンなテキストを抽出するプロセスを自動化し、複雑な文書形式に閉じ込められた貴重な情報を、迅速に利用可能なデータに変換することを可能にします。
🔎 グローバルニュース検索API
単一の専用APIコールで、世界のニュース状況にアクセスできます。The News Search機能は、リクエストごとに最大100件の関連結果を、必須のメタデータとともに返します。これにより、市場インテリジェンスやトレンド分析に不可欠なリアルタイムまたは過去のデータストリームを、迅速かつ効率的に取得できます。
🖼️ 迅速なデプロイメントのためのビジュアル抽出ツール
迅速な分析やAPIを使用しないワークフローのために、プラットフォームは直感的なオンラインビジュアルツールを提供します。ユーザーは最大1,000件のURLを一度に貼り付けるかアップロードして、即座にテキストを抽出できます。抽出されたクリーンなデータは永続的なJobsページに保存され、後でCSVまたはJSON形式で取得可能です。
活用事例
1. 高品質なAI/ML学習データの供給
データチームは、信頼性の高いデータパイプラインを構築する上で、Extractor APIを重要な最初のステップとして活用しています。数千ものソースからクリーンで構造化されたテキストとメタデータを収集することで、ダウンストリームのデータウェアハウスやデータレイクが高品質なソースマテリアルを受け取り、機械学習モデルのより正確なトレーニングとパフォーマンス向上を促進します。
2. 動的なナレッジベースの構築
外部情報を迅速かつ自動的に取り込み、包括的なナレッジベースを構築できます。PDF Data Extraction機能を使用して、技術ホワイトペーパー、公開レポート、またはドキュメントから主要な事実や数値を抽出し、手作業でのデータ入力なしに社内ナレッジシステムが常に最新の状態に保たれるようにします。
3. ターゲットを絞った高度なデータQA
詳細な製品仕様や研究要約など、複雑で高度に構造化されたページで通常の抽出がうまくいかない場合でも、LLM搭載エクストラクターが解決策を提供します。希望するLLMを選択し、正確なプロンプトを作成することで、ウェブページコンテンツとプログラム的に対話し、複雑なページ構造からでも、必要な正確かつ非常に具体的な情報のみを抽出できます。
結論
The Extractor APIは、複雑なウェブデータやドキュメントデータを、クリーンで実用的なインテリジェンスに変換するために必要な堅牢性と高度な機能を提供します。技術的な前提条件を処理し、最先端のAIツールを提供することで、データパイプラインが信頼性が高く、効率的で、高度なアプリケーションに対応できるようになります。
More information on Extractor API
Launched
2020-03
Pricing Model
Freemium
Starting Price
$33/ month
Global Rank
12055209
Follow
Month Visit
<5k
Tech used
Top 5 Countries
44.64%
36.93%
18.42%
India
France
United States
Traffic Sources
5.75%
1.47%
0.17%
9.98%
53.25%
29.08%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Extractor API was manually vetted by our editorial team and was first featured on 2025-10-31.
Extractor API 代替ソフト
もっと見る 代替ソフト-

Parse Extract: LLMパイプライン向けの高度なデータ抽出とOCR。 複雑なドキュメントやウェブデータを、クリーンでLLMに最適なテキストへと変換します。 費用対効果に優れ、高いセキュリティを実現します。
-

AIを活用し、あらゆるサイトから構造化されたウェブデータを楽々抽出。コードは一切不要です!プロンプトとスキーマで、必要な情報を正確に定義するだけ。
-

-

Extracta.ai を使用して、構造化されていないあらゆる文書からデータを抽出します。スキャンした文書を自動的に解析し、必要な情報を取得します。
-
