What is Turbopuffer?
turbopufferは、莫大なインフラコストをかけることなく、大規模なスケーラビリティが求められる現代のエンタープライズデータワークロード向けに設計された高性能な検索エンジンです。低コストのオブジェクトストレージを唯一のステートフルな依存関係として独自に採用することで、turbopufferはベクトル検索とフルテキスト検索の機能を効率的に組み合わせ、ペタバイト規模のインデックスを経済的に維持するという中核的な課題を解決します。B2Bおよびエンタープライズ顧客向けに特化して構築されたこのプラットフォームは、信頼性の高い10ミリ秒未満のウォームレイテンシーを実現し、マルチテナント環境における強力なデータ分離をサポートします。
主な特徴
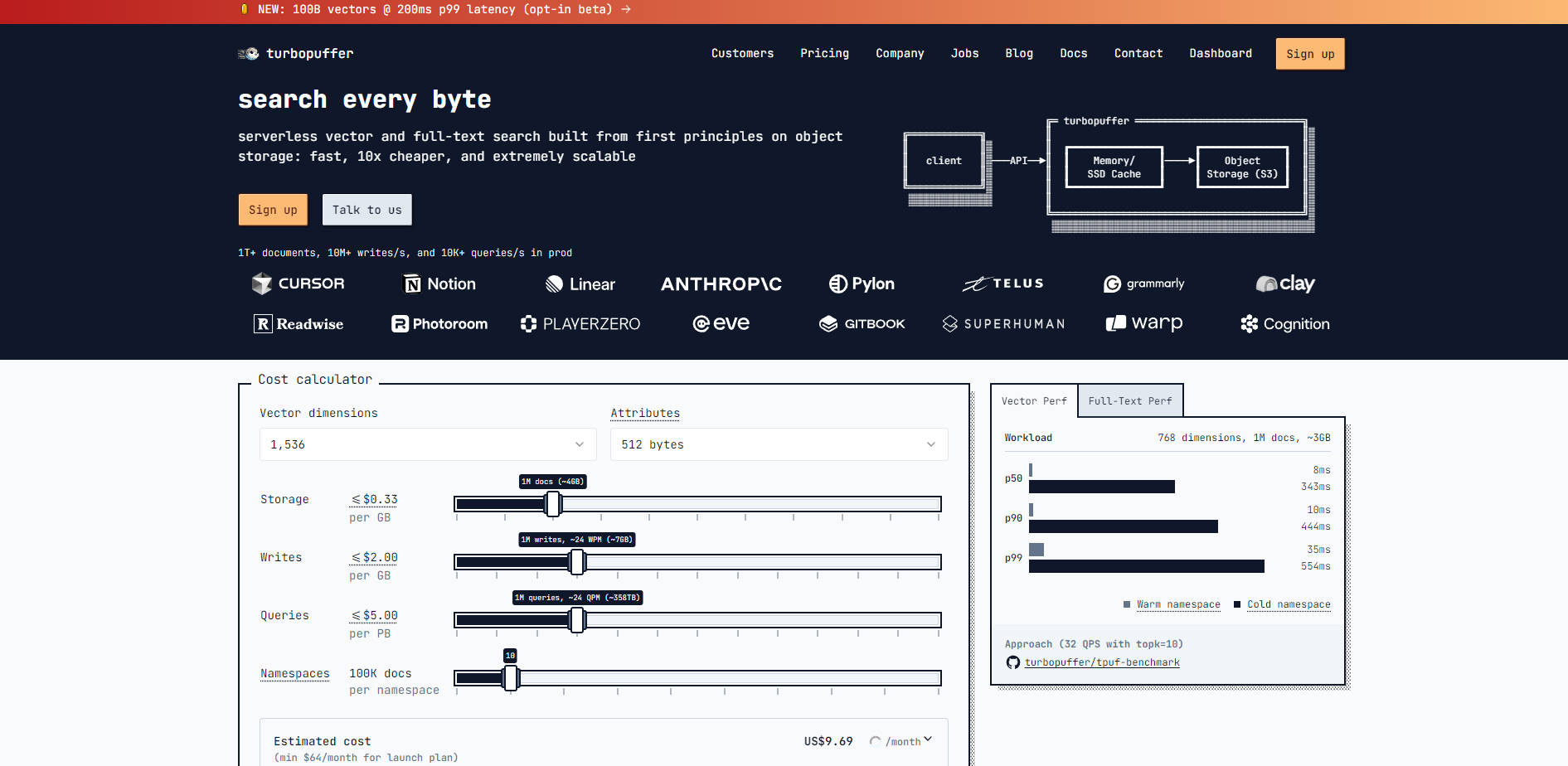
turbopufferは、コンピュート(NVMe SSDとメモリキャッシュ)とステート(オブジェクトストレージ)を分離することで、パフォーマンスと効率の両方を提供するよう設計されています。このアーキテクチャにより、コストを管理しつつ、数十億のドキュメントを処理することが可能になります。
🔍 統合されたベクトル検索とフルテキスト検索
単一のAPIコールで、現代的なハイブリッド検索の力を手に入れることができます。turbopufferは、ベクトル埋め込みには重心ベースのApproximate Nearest Neighbour (ANN) インデックス (SPFresh) を、キーワード検索には転置BM25インデックスを利用します。この組み合わせにより、高い再現率が保証され、後続の絞り込みプロセス向けに堅牢な候補セットを生成できるため、導入直後から優れた関連性を実現します。
☁️ オブジェクトストレージネイティブアーキテクチャ
ステートは、低コストのオブジェクトストレージ(S3やGCSなど)で排他的に管理され、システムが数兆のドキュメントに対して水平にスケーリングすることを可能にします。コンピュートノードはNVMe SSDとメモリキャッシュを利用し、活発に検索されるデータのみをキャッシュします。このアプローチにより、従来のレプリケートされたディスクシステムと比較して、頻繁にアクセスされるネームスペースであってもストレージコストを大幅に削減できます。
✅ 強力な一貫性と耐久性(ACD)
データ整合性と信頼性は極めて重要です。turbopufferは、原子性(Atomicity)、一貫性(Consistency)、耐久性(Durability)といったACD特性を提供します。書き込みは即座にWrite-Ahead Log (WAL) にコミットされ、APIが応答した時点で耐久性が保証されます。デフォルトでは、後続のクエリはすぐに書き込みを確認でき、信頼性の高いアプリケーションに不可欠な強力な一貫性を確保します。
🛡️ エンタープライズグレードの分離とセキュリティ
B2Bマルチテナンシー向けに設計されたturbopufferは、各クライアントのデータをオブジェクトストレージ上の独自のネームスペースプレフィックス内に分離します。高いコンプライアンス要件を持つエンタープライズのニーズに対し、シングルテナンシークラスター、VPCへのBring Your Own Cloud (BYOC) デプロイ、およびCustomer Managed Encryption Keys (CMEK) による分離をサポートしており、お客様がデータ暗号化キーを完全に制御できることを保証します。
ユースケース
turbopufferは、高いスループット、大規模なスケール、厳格なデータ分離を要求しつつ、総所有コスト(TCO)を最小限に抑えるシナリオで優れた性能を発揮します。
1. 効率的なファーストステージ検索
数百万から数十億のドキュメントを扱う際、迅速に検索範囲を絞り込む必要があります。turbopufferのハイブリッド検索を利用して、数十から数百の関連性の高い結果からなる候補セットを効率的に生成します。この機能は、再ランキングや絞り込みのセカンドステージに依存する大規模アプリケーションにとって重要であり、初期検索の速度と網羅性の両方を確保します。
2. 10ミリ秒未満のレイテンシーワークロードの提供
検索速度がユーザーエクスペリエンスに直接影響するユーザー向けアプリケーションにおいて、turbopufferは、その優れたウォームクエリパフォーマンス(p50=8ms)を活用することを可能にします。重要なネームスペースや特定のユーザーデータセグメントをプリフライトクエリで「事前にウォームアップ」する戦略を実装することで、その後のユーザーインタラクションは低いウォームレイテンシーのみを体験することが保証されます。
3. 高いコンプライアンス要件に対応したデータストレージと検索
Protected Health Information (PHI) のような機密情報を扱う企業は、turbopufferのセキュリティスタックから恩恵を受けることができます。当社はCustomer Managed Encryption Keys (CMEK) をサポートし、SOC 2 Type 2監査を受けています。HIPAAコンプライアンスを必要とするお客様は、Business Associate Agreement (BAA) を要求でき、お客様が選択したリージョン内で安全かつコンプライアンスに準拠したデータホスティングに必要なフレームワークを提供します。
turbopufferを選ぶ理由
turbopuffer独自のアーキテクチャは、従来の検索データベースやベクトルデータベースと比較して、明確な運用上および財務上の優位性を提供します。
優れたコスト効率とパフォーマンス
turbopufferは、データがキャッシュされている場合(p50ウォームレイテンシー8ms)、インメモリ検索エンジンと同等の速度を提供するよう設計されていますが、運用コストははるかに安価です。インデックスデータの大部分を高価なレプリケートされたディスクシステムではなく、低コストのオブジェクトストレージに保存することで、全体のストレージフットプリントとインフラ支出を劇的に削減できます。
オブジェクトストレージ効率への最適化
当社のインデックス戦略は、クラウドストレージの経済性に合わせて根本的に最適化されています。重心ベースのSPFreshインデックスは、インデックス作成時およびクエリ時に必要なランダムなラウンドトリップと書き込み増幅の数を最小限に抑えます。これは、高レイテンシーのオブジェクトストレージと対話する際に、グラフベースのインデックス(HNSWやDiskANNなど)にとって一般的なボトルネックとなるものです。この最適化により、より高速なコールドスタートとより低い運用コストが実現します。
運用の簡素化と信頼性
オブジェクトストレージが唯一のステートフルな依存関係として機能することで、システムの運用とメンテナンスが大幅に簡素化されます。このアーキテクチャは、任意のクエリノードが任意のネームスペースのデータを即座に提供できるため、信頼性と高可用性(HA)を向上させます。さらに、システムは高スループット(毎秒10,000以上のベクトル)で大量の書き込み(追加、更新、削除)を処理するように設計されており、お客様のインデックスが常に最新かつ一貫していることを保証します。
結論
turbopufferは、最も要求の厳しいエンタープライズ検索アプリケーションが求める速度とスケーラビリティを提供しつつ、そのオブジェクトストレージ中心の設計により、総所有コストを根本的に削減します。堅牢なハイブリッド検索、強力な一貫性、マルチテナントデータ向けの大規模なスケーラビリティが必要であれば、turbopufferはお客様が必要とする信頼性とコスト効率の高い基盤を提供します。
More information on Turbopuffer
Launched
2023-05
Pricing Model
Paid
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Turbopuffer was manually vetted by our editorial team and was first featured on 2025-11-02.