
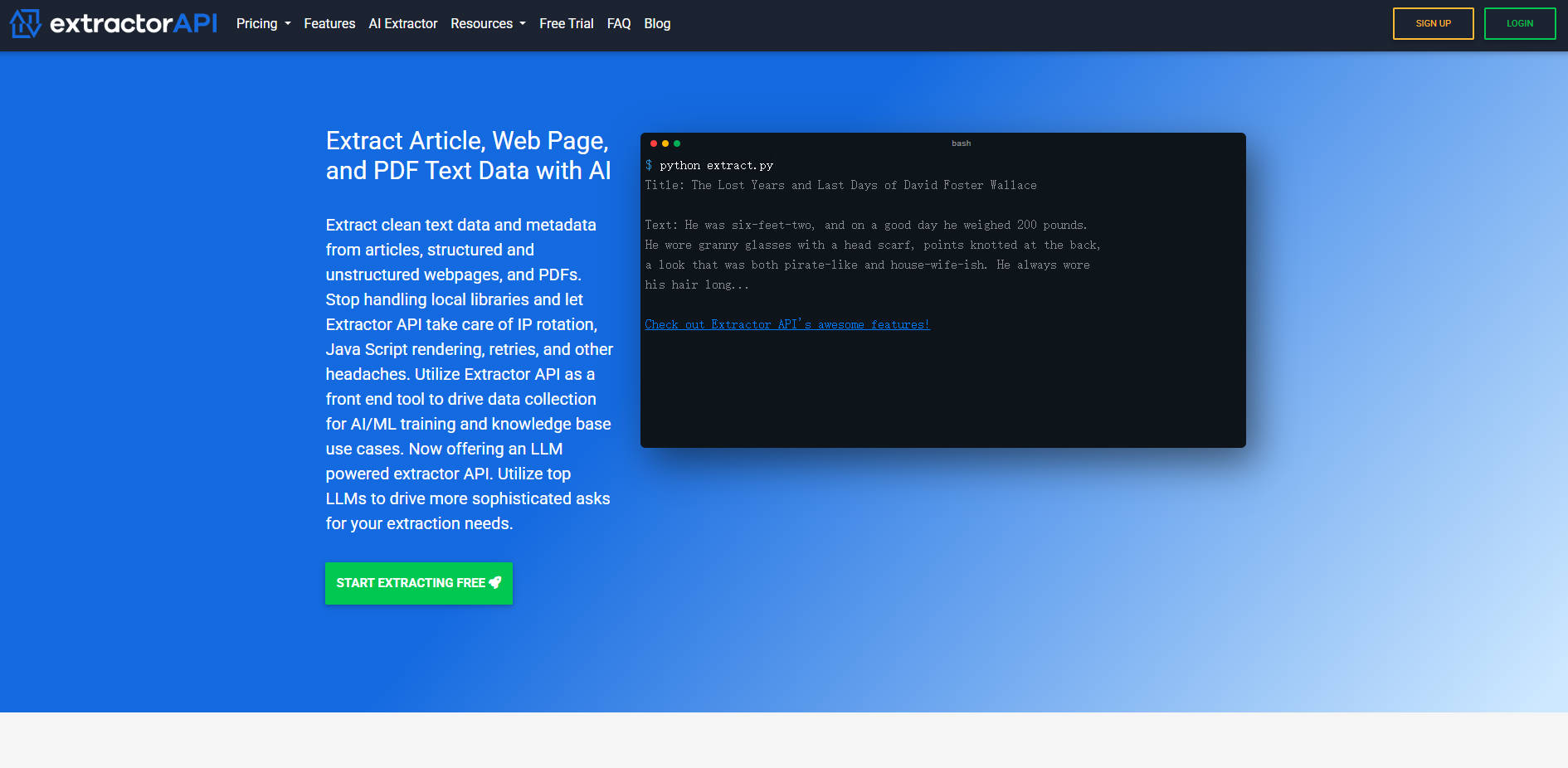
What is Extractor API?
Extractor API — это комплексная, высокопроизводительная платформа для извлечения текста, разработанная для упрощения сбора больших объемов данных. Она решает присущие веб-скрапингу технические сложности, такие как управление ротацией IP-адресов, повторные попытки и динамическая отрисовка JavaScript, предоставляя чистый, структурированный текст и ценные метаданные из статей, структурированных/неструктурированных веб-страниц и PDF-файлов. Команды по работе с данными, инженеры по ИИ/МО и создатели баз знаний могут полагаться на Extractor API для эффективного и экономичного доступа к ранее недоступной информации.
Ключевые особенности
🔌 Непревзойденная техническая надежность
Вам больше не нужно управлять сложной инфраструктурой или локальными библиотеками. Extractor API автоматически справляется с типичными сложностями извлечения, включая надежные повторные попытки, непрерывную ротацию IP-адресов и необходимую отрисовку JavaScript (доступно на платных тарифах). Это обеспечивает высокую надежность и доступность, позволяя вашей команде сосредоточиться исключительно на выходных данных, а не на механизмах извлечения.
🧠 Продвинутое извлечение данных с помощью LLM
Используйте возможности ведущих моделей, включая OpenAI и Google LLMs, через специализированный Extractor API на базе LLM. Эта функция выходит за рамки простого синтаксического анализа текста, обеспечивая выполнение сложных требований к извлечению, более высокую точность в различных форматах веб-страниц и уникальную возможность «общаться» с веб-страницами с помощью целенаправленных запросов для получения тонкой информации.
📄 Автоматизированное извлечение данных из PDF
Легко интегрируйте рабочие процессы извлечения как для собственных локальных, так и для общедоступных документов. Эта функция автоматизирует процесс извлечения ключевых наборов данных и чистого текста из неструктурированных PDF-файлов, гарантируя, что ценная информация, запертая в сложных форматах документов, может быть быстро преобразована в пригодные для использования данные.
🔎 Global News Search API
Получите доступ к мировому новостному ландшафту с помощью одного специализированного вызова API. Функция News Search возвращает до 100 релевантных результатов за один запрос, включая необходимые метаданные, обеспечивая быстрый и эффективный источник данных в реальном времени или исторических данных, крайне важных для анализа рынка и отслеживания тенденций.
🖼️ Визуальный инструмент извлечения для быстрого развертывания
Для быстрого анализа или рабочих процессов без использования API платформа предлагает интуитивно понятный онлайн-инструмент визуального извлечения. Пользователи могут одновременно вставить или загрузить до 1000 URL-адресов для немедленного извлечения текста, сохраняя полученные чистые данные на постоянной странице «Задания» для последующего извлечения в формате CSV или JSON.
Примеры использования
1. Обеспечение высококачественными данными для обучения ИИ/МО
Команды по работе с данными используют Extractor API в качестве критически важного первого шага при создании надежных конвейеров данных. Собирая чистый, структурированный текст и метаданные из тысяч источников, вы гарантируете, что ваши нижестоящие хранилища и озера данных получат высококачественный исходный материал, обеспечивая более точное обучение и лучшую производительность ваших моделей машинного обучения.
2. Создание динамических баз знаний
Быстро и автоматически импортируйте внешнюю информацию для создания исчерпывающих баз знаний. Используйте функцию извлечения данных из PDF, чтобы получить ключевые факты и цифры из технических документов, публичных отчетов или документации, гарантируя, что ваши внутренние системы знаний будут постоянно обновляться без ручного ввода данных.
3. Целенаправленный, продвинутый контроль качества данных
Когда стандартное извлечение не справляется со сложными, высокоструктурированными страницами (например, подробные спецификации продуктов или резюме исследований), экстрактор на базе LLM предлагает решение. Выбрав нужную LLM и написав точный запрос, вы можете программно взаимодействовать с содержимым веб-страницы, гарантируя извлечение только точной, строго определенной информации, даже из сложных структур страниц.
Заключение
Extractor API обеспечивает необходимую надёжность и функциональность для преобразования сложных веб-данных и данных документов в чистую, практически применимую информацию. Решая технические предпосылки и предлагая передовые инструменты ИИ, он гарантирует, что ваши конвейеры данных будут надёжными, эффективными и готовыми к продвинутым приложениям.
More information on Extractor API
Launched
2020-03
Pricing Model
Freemium
Starting Price
$33/ month
Global Rank
12055209
Follow
Month Visit
<5k
Tech used
Top 5 Countries
44.64%
36.93%
18.42%
India
France
United States
Traffic Sources
5.75%
1.47%
0.17%
9.98%
53.25%
29.08%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Extractor API was manually vetted by our editorial team and was first featured on 2025-10-31.
Extractor API Альтернативи
Больше Альтернативи-

Parse Extract: Передовое извлечение данных и ОРС для конвейеров LLM. Превращает сложные документы и веб-данные в чистый текст, готовый для обработки LLM. Экономично и безопасно.
-

С легкостью извлекайте структурированные веб-данные с любого сайта, используя ИИ. Код не нужен! Определяйте в точности, что вам нужно, с помощью промптов и схемы.
-

Parsera, платформа для извлечения веб-данных на базе LLM, позволяет извлекать все видимые данные с любого URL-адреса с помощью инструкций на естественном языке, которые затем можно одним кликом преобразовать в многократно используемый скрипт для парсинга и применить его к тысячам однотипных страниц.
-

Извлекайте данные из любых неструктурированных документов с помощью Extracta.ai. Автоматически анализируйте отсканированные документы и извлекайте необходимую информацию.
-
