
What is Turbopuffer?
turbopuffer — это высокопроизводительная поисковая система, разработанная для современных корпоративных задач по обработке данных, которые требуют огромных масштабов без непомерных затрат на инфраструктуру. За счёт уникального использования недорогого объектного хранилища в качестве единственной зависимости, сохраняющей состояние, turbopuffer эффективно сочетает возможности векторного и полнотекстового поиска, решая ключевую задачу экономичного поддержания индексов петабайтного масштаба. Разработанная специально для B2B и корпоративных клиентов, эта платформа обеспечивает надёжную задержку «тёплых» запросов менее 10 мс и поддерживает строгую изоляцию данных для многопользовательских сред.
Ключевые особенности
turbopuffer спроектирован для обеспечения как производительности, так и эффективности за счёт разделения вычислительных ресурсов (NVMe SSD и кэш памяти) и состояния (объектное хранилище). Эта архитектура позволяет обрабатывать миллиарды документов, сохраняя при этом контроль над расходами.
🔍 Единый векторный и полнотекстовый поиск
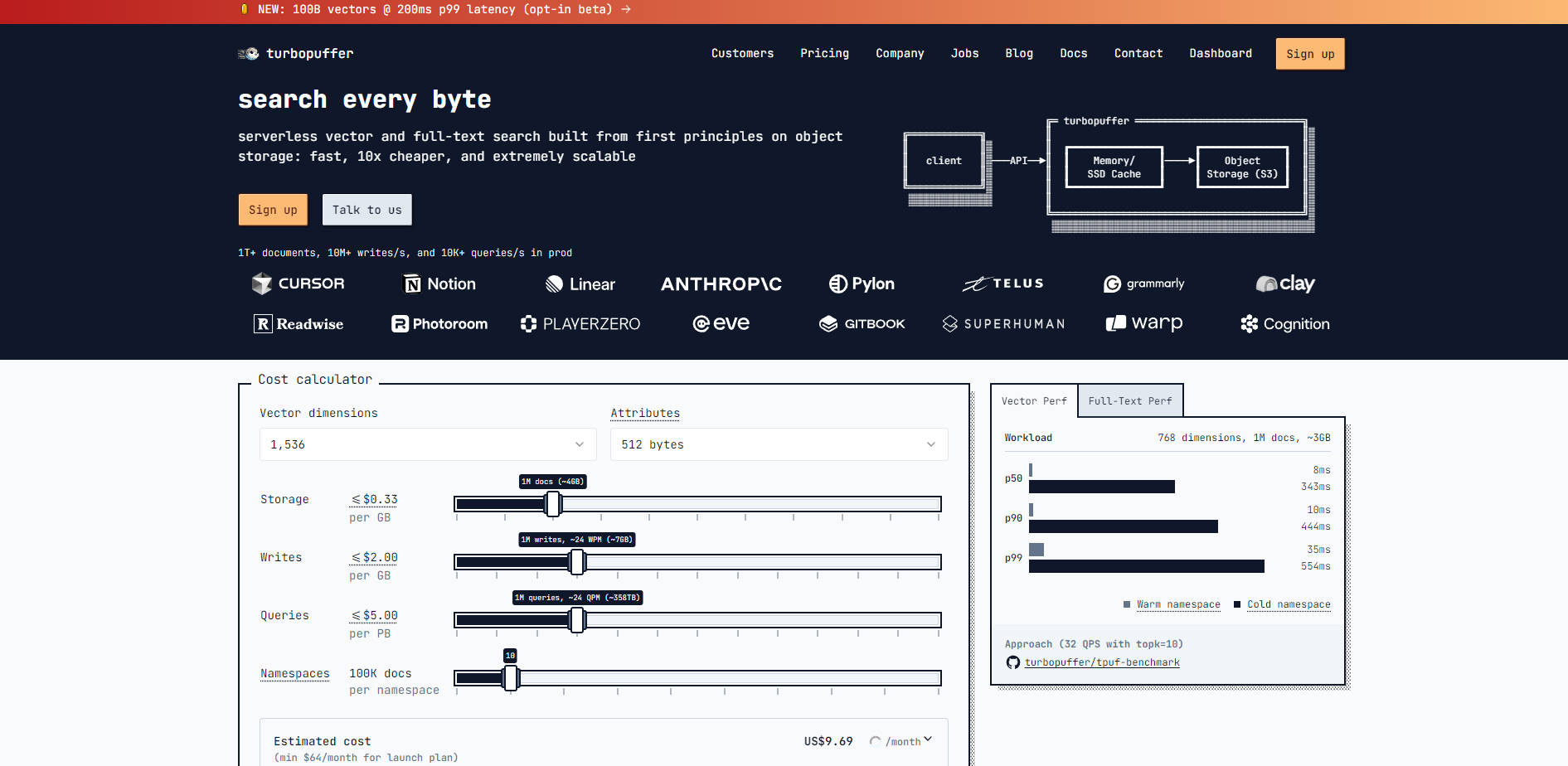
Вы получаете мощь современного гибридного поиска всего за один вызов API. turbopuffer использует центроидно-ориентированный индекс приблизительного поиска ближайших соседей (ANN) (SPFresh) для векторных эмбеддингов и инвертированный индекс BM25 для поиска по ключевым словам. Такая комбинация обеспечивает высокий показатель полноты поиска и позволяет формировать надёжные наборы кандидатов для последующих процессов уточнения, предоставляя превосходную релевантность «из коробки».
☁️ Архитектура, нативно работающая с объектными хранилищами
Состояние управляется исключительно в недорогом объектном хранилище (например, S3 или GCS), что позволяет системе горизонтально масштабироваться до триллионов документов. Вычислительные узлы используют NVMe SSD и кэш памяти, кэшируя только активно искомые данные. Такой подход значительно снижает затраты на хранение по сравнению с традиционными реплицированными дисковыми системами, даже для часто используемых пространств имён.
✅ Строгая согласованность и долговечность (ACD)
Целостность и надёжность данных имеют первостепенное значение. turbopuffer обеспечивает свойства атомарности, согласованности и долговечности (ACD). Записи немедленно фиксируются в журнале Write-Ahead Log (WAL) и становятся постоянными после возврата API. По умолчанию последующие запросы немедленно видят запись, обеспечивая строгую согласованность, необходимую для надёжных приложений.
🛡️ Корпоративный уровень изоляции и безопасности
Разработанный для B2B-моделей с множеством клиентов, turbopuffer изолирует данные каждого клиента в его собственном префиксе пространства имён в объектном хранилище. Для корпоративных нужд с высокими требованиями к соответствию нормам мы поддерживаем изоляцию через однопользовательские кластеры, развёртывание Bring Your Own Cloud (BYOC) в вашей VPC и Customer Managed Encryption Keys (CMEK), обеспечивая вам полный контроль над ключами шифрования ваших данных.
Сценарии использования
turbopuffer отлично проявляет себя в сценариях, требующих высокой пропускной способности, огромного масштаба и строгой изоляции данных, при этом минимизируя общую стоимость владения (TCO).
1. Эффективный поиск на первом этапе
При работе с миллионами или миллиардами документов необходимо быстро сузить область поиска. Используйте гибридный поиск turbopuffer для эффективного формирования набора из десятков или сотен релевантных результатов. Эта возможность критически важна для высокомасштабных приложений, которые полагаются на второй этап переранжирования или уточнения, обеспечивая при этом, что начальный поиск будет как быстрым, так и всеобъемлющим.
2. Обработка рабочих нагрузок с задержкой менее 10 мс
Для пользовательских приложений, где скорость поиска напрямую влияет на пользовательский опыт, turbopuffer позволяет использовать его впечатляющую производительность «тёплых» запросов (p50=8 мс). Вы можете реализовать стратегию «предварительного прогрева» критически важных пространств имён или определённых сегментов пользовательских данных с помощью «предварительного» запроса, гарантируя, что последующие взаимодействия пользователя будут происходить только с низкой задержкой «тёплого» состояния.
3. Хранение и поиск данных с высокой степенью соответствия нормам
Предприятия, работающие с конфиденциальной информацией, такой как защищённая медицинская информация (PHI), получают преимущества от стека безопасности turbopuffer. Мы поддерживаем Customer Managed Encryption Keys (CMEK) и проходим аудиты SOC 2 Type 2. Клиенты, которым требуется соответствие HIPAA, могут запросить соглашение о деловом партнёрстве (BAA), предоставляющее необходимую основу для безопасного и соответствующего нормам хостинга данных в выбранном вами регионе.
Почему стоит выбрать turbopuffer?
Уникальная архитектура turbopuffer предоставляет явные операционные и финансовые преимущества по сравнению с традиционными поисковыми и векторными базами данных.
Превосходная экономически эффективная производительность
turbopuffer разработан для работы со скоростью in-memory поисковых систем при кэшировании данных (p50 задержка «тёплых» запросов 8 мс), но при этом значительно дешевле в эксплуатации. Храня подавляющую часть индексных данных в недорогом объектном хранилище, а не в дорогих реплицированных дисковых системах, вы значительно сокращаете общие объёмы хранения и расходы на инфраструктуру.
Оптимизация для эффективной работы с объектными хранилищами
Наши стратегии индексирования фундаментально оптимизированы для экономики облачных хранилищ. Центроидно-ориентированный индекс SPFresh минимизирует количество случайных запросов туда-обратно и усиление записи, необходимые при индексировании и запросах, что является распространёнными «узкими местами» для графовых индексов (таких как HNSW или DiskANN) при взаимодействии с объектными хранилищами с высокой задержкой. Эта оптимизация приводит к более быстрым «холодным» запускам и снижению эксплуатационных расходов.
Упрощённые операции и надёжность
Поскольку объектное хранилище является единственной зависимостью, сохраняющей состояние, эксплуатация и обслуживание системы значительно упрощаются. Эта архитектура повышает надёжность и высокую доступность (HA), поскольку любой узел запросов может мгновенно обслуживать данные для любого пространства имён. Более того, система спроектирована для обработки интенсивных операций записи (добавления, обновления и удаления) с высокой пропускной способностью (~10 000+ векторов/сек), гарантируя, что ваш индекс остаётся актуальным и согласованным.
Заключение
turbopuffer обеспечивает скорость и масштабируемость, необходимые для самых интенсивных корпоративных поисковых приложений, одновременно значительно сокращая общую стоимость владения благодаря своей объектно-ориентированной архитектуре. Если вам нужны надёжный гибридный поиск, строгая согласованность и огромная масштабируемость для многопользовательских данных, turbopuffer предоставит необходимую надёжную и экономичную основу.
More information on Turbopuffer
Launched
2023-05
Pricing Model
Paid
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Turbopuffer was manually vetted by our editorial team and was first featured on 2025-11-02.
Turbopuffer Альтернативи
Больше Альтернативи-

-
-

Turso — это платформа баз данных, которая берет встроенный движок баз данных libSQL и адаптирует его для распределенных приложений производственного масштаба. Она добавляет такие возможности, как репликация, ветвление, восстановление на определенный момент времени, нативный векторный поиск и программное управление через API, при этом сохраняя привычный для разработчиков опыт работы с SQLite.
-

-

TurboSeek — это поисковая система с искусственным интеллектом, использующая API Bing и передовые модели. Она предлагает понимание естественного языка, расширенные результаты, скорость, связанные вопросы и открытое сотрудничество. Идеально подходит для исследований, решения технических проблем и создания контента.