
What is Extractor API?
Extractor API 是一个全面、高性能的文本提取平台,旨在简化大规模数据采集。它解决了网络爬取固有的技术复杂性,例如 IP 轮换管理、重试机制和动态 JavaScript 渲染等,能够从文章、结构化/非结构化网页和 PDF 文件中提取出清晰、结构化的文本和有价值的元数据。数据团队、AI/ML 工程师以及知识库创建者可以依赖 Extractor API,高效且经济地获取以往难以获取的信息。
主要功能
🔌 无缝技术弹性
您不再需要管理复杂的底层基础设施或本地库。Extractor API 能够自动处理常见的提取难点,包括强大的重试机制、持续的 IP 轮换以及必要的 JavaScript 渲染(付费套餐提供)。这确保了高可靠性和可用性,让您的团队能够专注于数据产出本身,而非繁琐的提取机制。
🧠 大模型驱动的复杂信息提取
通过专用的 LLM-powered Extractor API,您可以充分利用包括 OpenAI 和 Google LLMs 在内的领先大模型的能力。这一功能超越了简单的文本解析,实现了更复杂的提取需求,在不同网页格式上均能保持更高的准确性,并且具备通过定向提示词与网页内容“对话”的独特能力,从而提取出细致入微的信息。
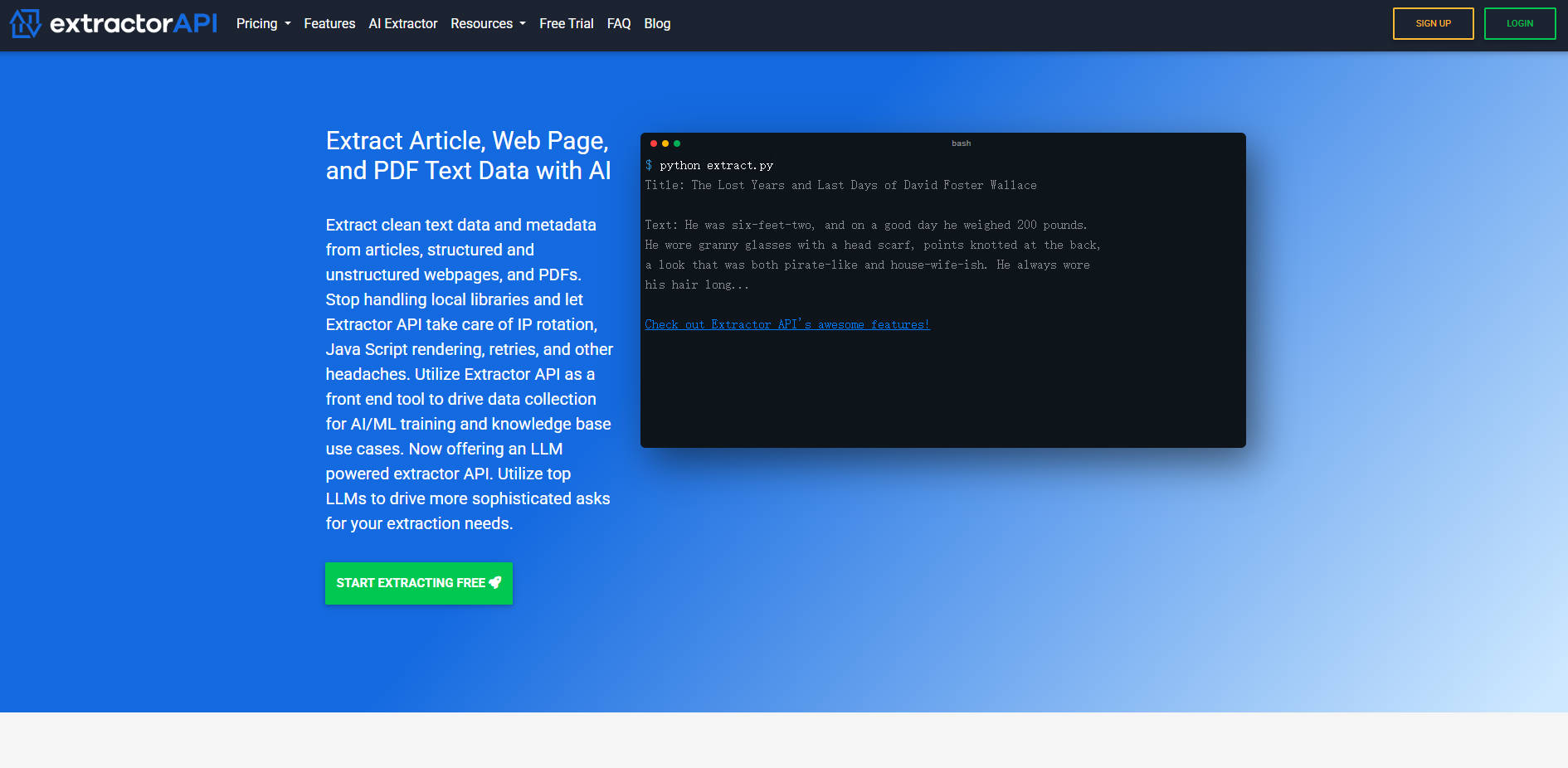
📄 自动化 PDF 数据提取
轻松整合针对专有本地文档和公共文档的提取工作流。该功能自动化从非结构化 PDF 文件中提取关键数据集和纯文本的过程,确保复杂文档格式中“锁定”的有价值信息能够迅速转化为可用数据。
🔎 全球新闻搜索 API
只需一次专用的 API 调用,即可触达全球新闻版图。News Search 功能每次请求可返回多达 100 条相关结果,并附带必要的元数据,为市场情报和趋势分析所需的实时或历史数据流提供了快速高效的来源。
🖼️ 可视化提取工具,实现快速部署
对于快速分析或非 API 工作流,平台提供了一个直观的在线可视化工具。用户可以一次性粘贴或上传多达 1,000 个 URL,进行即时文本提取,并将提取出的纯净数据保存到持久化的“任务”页面,以便日后以 CSV 或 JSON 格式检索。
应用场景
1. 为高质量 AI/ML 训练数据提供源动力
数据团队将 Extractor API 作为构建可靠数据管道的关键第一步。通过从数千个来源收集纯净、结构化的文本和元数据,您可以确保您的下游数据仓库和数据湖获得高质量的源材料,从而推动机器学习模型实现更精确的训练和更优异的性能。
2. 构建动态知识库
快速、自动化地摄取外部信息,以构建全面的知识库。利用 PDF Data Extraction 功能从技术白皮书、公共报告或文档中提取关键事实和数据,确保您的内部知识系统无需手动录入,即可持续保持最新状态。
3. 目标明确的精细化数据质检
当标准提取方式在复杂、高度结构化的页面(如详细的产品规格或研究摘要)上失效时,LLM-powered Extractor 提供了解决方案。通过选择所需的大模型并编写精确的提示词,您可以程序化地与网页内容进行交互,确保即使面对复杂的页面结构,您也能仅提取出所需的确切、高度具体的信息。
总结
Extractor API 提供了必要的鲁棒性和精细度,能够将复杂的网络和文档数据转化为纯净、可操作的情报。通过处理技术先决条件并提供尖端人工智能工具,它确保您的数据管道可靠、高效,并为高级应用做好准备。
More information on Extractor API
Launched
2020-03
Pricing Model
Freemium
Starting Price
$33/ month
Global Rank
12055209
Follow
Month Visit
<5k
Tech used
Top 5 Countries
44.64%
36.93%
18.42%
India
France
United States
Traffic Sources
5.75%
1.47%
0.17%
9.98%
53.25%
29.08%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Extractor API was manually vetted by our editorial team and was first featured on 2025-10-31.
Extractor API 替代方案
更多 替代方案-

Parse Extract:专为LLM管道打造的高级数据提取与OCR功能。将复杂的文档和网络数据转化为规整、可直接用于LLM的文本。成本效益高,安全可靠。
-

-

-

-
