What is Turbopuffer?
turbopuffer是一款高性能搜索引擎,专为现代企业数据工作负载而设计,能够满足海量规模需求,同时避免高昂的基础设施成本。turbopuffer独辟蹊径,仅以低成本对象存储作为其唯一的有状态依赖,高效地整合了向量和全文搜索能力,巧妙解决了经济地维护PB级索引的核心难题。该平台专为B2B及企业客户打造,提供可靠的、低于10毫秒的暖查询延迟,并支持多租户环境下的强大数据隔离。
主要特性
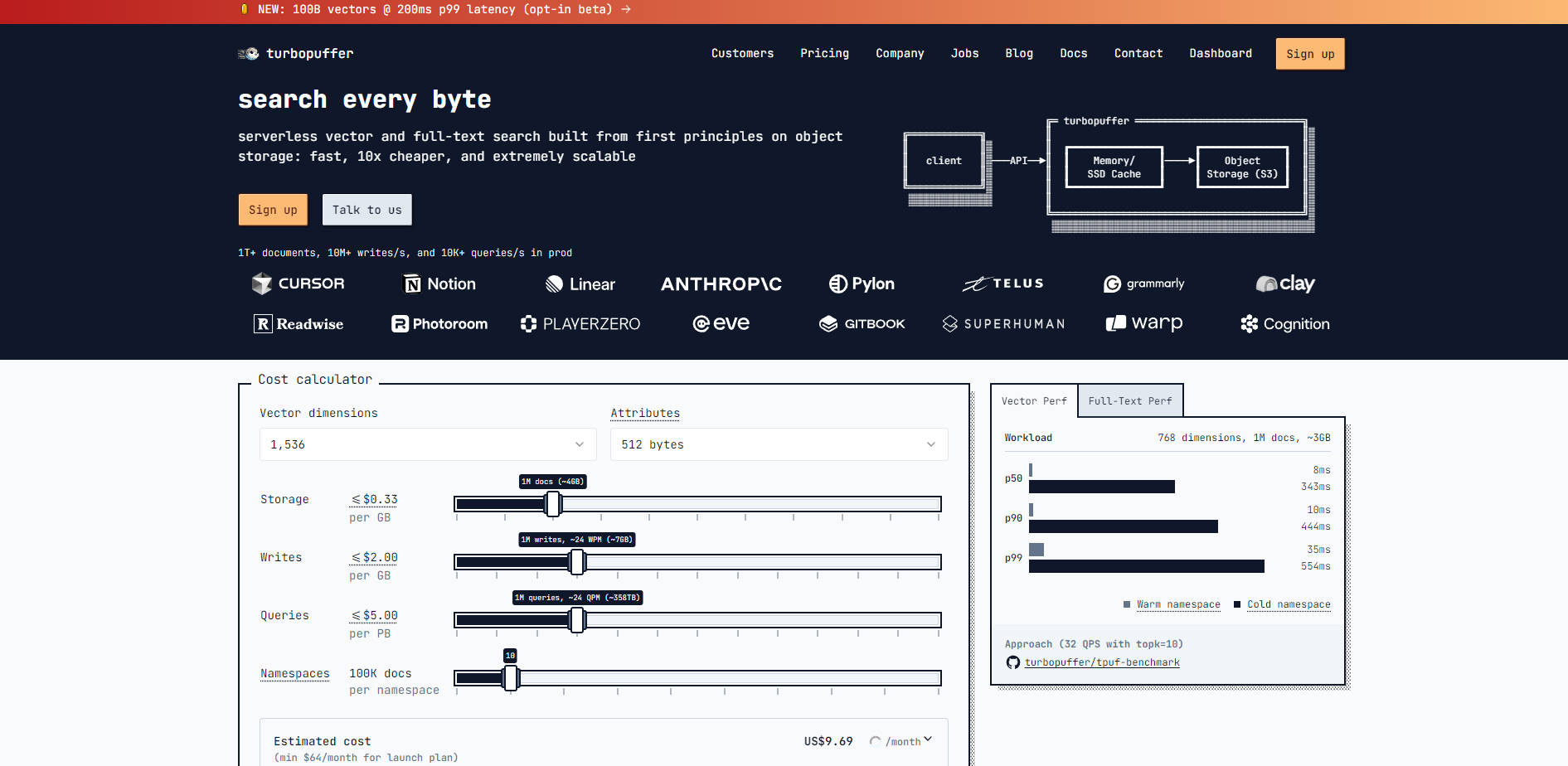
turbopuffer在设计上通过将计算层(NVMe SSD和内存缓存)与状态层(对象存储)分离,实现了性能与效率的双重提升。这种架构使您能够处理数十亿文档,同时有效控制成本。
🔍 统一的向量与全文搜索
您只需一次API调用,即可获得现代混合搜索的强大能力。turbopuffer采用基于质心的近似最近邻(ANN)索引(SPFresh)进行向量嵌入搜索,并利用倒排BM25索引进行关键词搜索。这种结合确保了高召回率,并能为您生成强大的候选集,以供后续的精炼处理,从而开箱即用地提供卓越的相关性。
☁️ 对象存储原生架构
状态层完全由低成本对象存储(如S3或GCS)管理,使系统能够横向扩展至数万亿文档。计算节点利用NVMe SSD和内存缓存,仅缓存活跃搜索的数据。与传统的复制磁盘系统相比,即使对于频繁访问的命名空间,这种方法也能显著降低存储成本。
✅ 强一致性与持久性 (ACD)
数据完整性和可靠性至关重要。turbopuffer提供原子性(Atomicity)、一致性(Consistency)和持久性(Durability)(ACD) 特性。写入操作会立即提交到预写日志(WAL),并在API返回时即刻持久化。默认情况下,后续查询会立即看到写入的数据,从而确保了可靠应用程序所需的强一致性。
🛡️ 企业级隔离与安全
turbopuffer专为B2B多租户设计,在对象存储上为每个客户端的数据提供独立的命名空间前缀隔离。针对高合规性的企业需求,我们支持通过单租户集群、客户自持云(BYOC)部署到您的VPC中,以及客户管理加密密钥(CMEK)来实现隔离,确保您对数据加密密钥拥有完全控制权。
典型应用场景
turbopuffer在需要高吞吐量、海量规模和严格数据隔离,同时最大限度降低总拥有成本(TCO)的场景中表现卓越。
1. 高效的首阶段检索
当处理数百万甚至数十亿文档时,您需要快速缩小搜索范围。利用turbopuffer的混合搜索功能,高效生成包含数十到数百个相关结果的候选集。这项能力对于依赖第二阶段重新排序或精炼的大规模应用至关重要,确保了初始搜索既快速又全面。
2. 提供低于10毫秒延迟的工作负载
对于搜索速度直接影响用户体验的面向用户应用,turbopuffer使您能够充分利用其卓越的暖查询性能(P50=8毫秒)。您可以通过预先查询(pre-flight query)来“预热”关键命名空间或特定用户数据段,从而确保后续用户交互仅体验到低暖查询延迟。
3. 高合规性数据存储与搜索
处理敏感信息(如受保护健康信息PHI)的企业,将受益于turbopuffer的安全栈。我们支持客户管理加密密钥(CMEK),并经过SOC 2 Type 2审计。需要符合HIPAA标准的用户可以请求签署商业伙伴协议(BAA),从而为您选择的区域内提供安全、合规的数据托管所需框架。
为何选择turbopuffer?
turbopuffer独特的架构相比传统搜索和向量数据库,提供了明显的运营和财务优势。
卓越的成本效益性能
turbopuffer在数据被缓存时,其速度可媲美内存型搜索引擎(P50暖查询延迟为8毫秒),但运营成本远低于后者。通过将绝大部分索引数据存储在低成本对象存储中,而非昂贵的复制磁盘系统,您可以大幅减少整体存储占用和基础设施开支。
为对象存储效率而优化
我们的索引策略从根本上为云存储经济性进行了优化。基于质心的SPFresh索引最大限度地减少了索引和查询过程中所需的随机往返次数和写入放大,这些是图结构索引(如HNSW或DiskANN)在与高延迟对象存储交互时常见的瓶颈。这种优化带来了更快的冷启动速度和更低的运营成本。
简化运维,增强可靠性
由于对象存储是唯一的有状态依赖,系统的运维和维护工作得以显著简化。这种架构增强了可靠性和高可用性(HA),因为任何查询节点都可以即时为任何命名空间提供数据服务。此外,该系统旨在以高吞吐量(每秒约10,000+向量)处理大量写入操作(追加、更新和删除),确保您的索引保持最新和一致。
总结
turbopuffer通过其以对象存储为中心的设计,不仅提供了最严苛企业搜索应用所需的处理速度和可扩展性,更从根本上降低了总拥有成本。如果您需要为多租户数据提供强大的混合搜索、强一致性和大规模可扩展性,turbopuffer将为您提供所需可靠且经济高效的基础。
More information on Turbopuffer
Launched
2023-05
Pricing Model
Paid
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Turbopuffer was manually vetted by our editorial team and was first featured on 2025-11-02.