
What is DocStrange?
DocStrange 是一個功能強大且開源的 Python 函式庫,旨在將複雜、非結構化的文件——包括 PDF、圖片、試算表和簡報——轉換為乾淨、可用的資料格式,並為人工智慧 (AI) 應用進行最佳化。它透過提供高度準確、結構化的輸出,解決了為下游 AI 工作流程(例如檢索增強生成 (RAG) 管道)準備多樣化內容的關鍵問題。如果您是開發人員或資料科學家,正在建構強大的大型語言模型 (LLM) 應用程式,DocStrange 為高品質輸入資料提供了必要的基礎。
主要功能
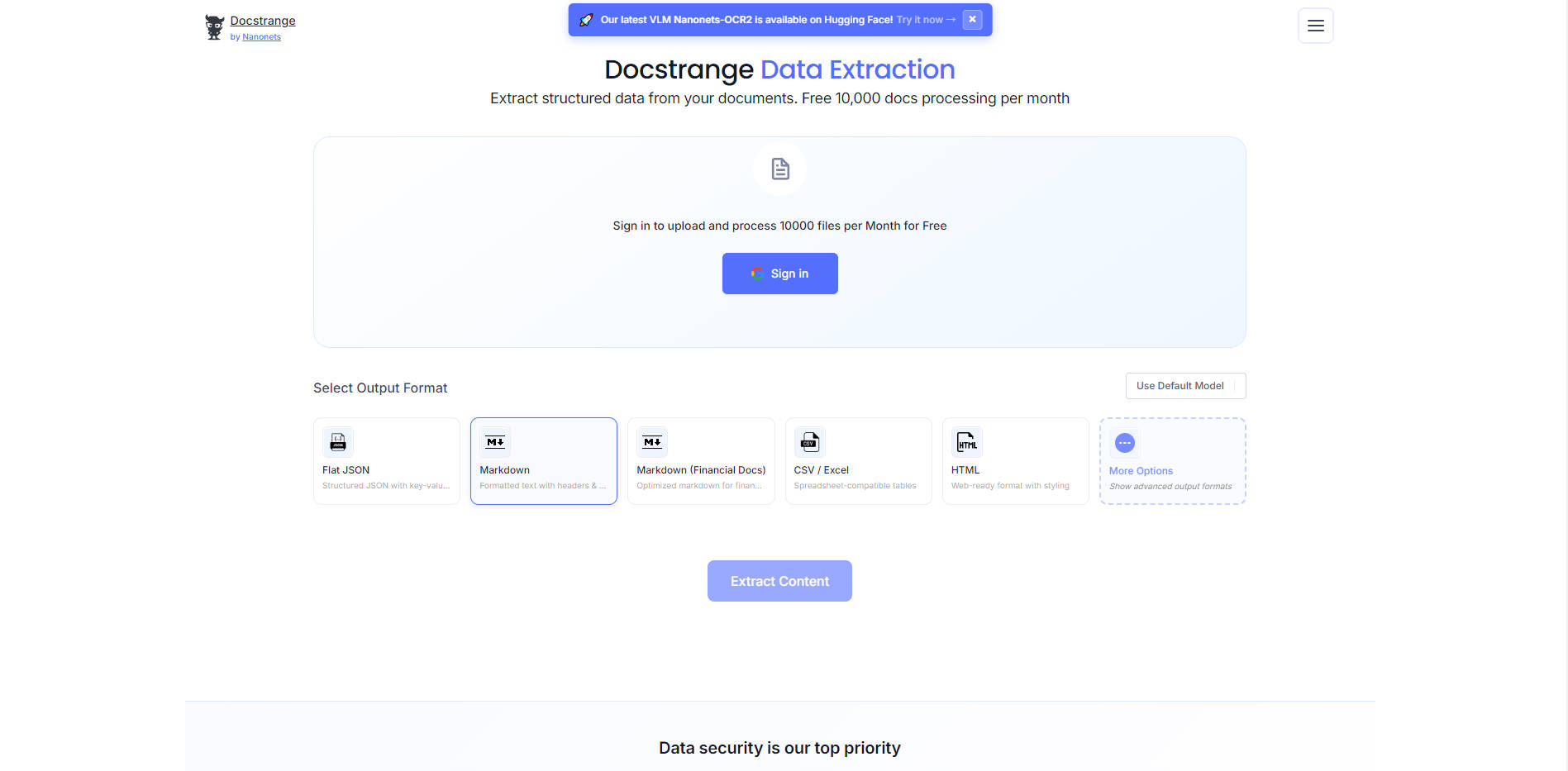
DocStrange 提供端到端的處理管道,確保輸出保留重要的文件結構,同時消除雜訊和多餘內容。
📄 通用輸入與靈活輸出
DocStrange 支援廣泛的檔案類型,包括 PDF、圖片 (JPEG, PNG)、PPTX、DOCX、XLSX 和網頁連結 (URL),簡化您的資料擷取流程。它以專為 AI 應用設計的格式輸出: LLM 最佳化 Markdown、結構化 JSON (支援綱要)、HTML 和 CSV。這種靈活性確保您的原始資料能立即用於向量資料庫或提示工程。
🧠 智慧型結構化擷取
擺脫單純的文字抓取。DocStrange 允許您定義特定欄位或強制執行巢狀 JSON 綱要,確保輸出資料的結構一致。這項功能由升級後的 7B 模型提供支援,可實現更高的準確性和更深入的文件理解,能夠精確地從複雜表單或合約中擷取實體、關係和關鍵指標。
🔎 進階光學字元辨識 (OCR) 與多餘內容移除
處理掃描文件、手機照片或收據時,常會引入雜訊,進而降低 AI 效能。DocStrange 整合了進階的光學字元辨識 (OCR) 管道,並具備多種引擎備援機制,即使是品質不佳的圖片也能精準擷取文字。它會自動清理輸出,移除頁面上的多餘內容和頁首,確保最終文字乾淨、連貫,且對語言模型具有高度可讀性。
📊 精準表格與結構辨識
表格對標準解析器來說,是出了名的難以處理。DocStrange 擅長精準辨識和格式化表格,將其轉換為乾淨、LLM 最佳化的 Markdown 表格。這種結構化上下文的保留至關重要,它能讓大型語言模型 (LLM) 正確解讀資料點之間的關係,而不是將表格視為扁平、雜亂的文字區塊。
使用案例
DocStrange 專為需要高品質資料、結構完整性和處理隱私的場景而設計。
1. 建構強大的 RAG 管道
快速將大量的複雜文件(例如:法規 PDF、內部知識庫、技術手冊)轉換為乾淨、可分割且適用於大型語言模型 (LLM-Ready) 的 Markdown 格式。透過提供乾淨、結構化的輸入,您可以顯著減少檢索過程中的雜訊,從而提高 RAG 系統的回答品質並減少幻覺。
2. 自動化金融與法律資料處理
利用結構化 JSON 擷取功能,自動處理表單、發票和合約的資料接收。例如,您可以定義一個綱要,從一批掃描的發票中擷取 invoice_number、 vendor_name 和 total_amount,將非結構化圖片轉換為乾淨、可供資料庫使用的資料,無需手動介入。
3. 確保資料隱私與合規性
對於處理敏感或專有文件的組織,DocStrange 提供 百分之百私有的本機模式。您可以在自己的 CPU 或 GPU 基礎設施上執行整個轉換管道——包括 7B 模型、OCR 和版面分析——確保資料不會傳輸到外部雲端服務,並維持完全的合規性控制。
獨特優勢
DocStrange 不僅以其功能脫穎而出,更以其架構設計展現獨特之處,在文件處理工具中提供無與倫比的控制能力和品質。
完全的本機處理控制: 不同於通用型的雲端 AI 服務(例如 AWS Textract),DocStrange 提供功能齊全的本機處理選項。這讓您能完全掌控資料管道、延遲和營運成本,同時保障資料隱私。
隨插即用的端到端管道: DocStrange 是一個強大、整合的解析解決方案,而非僅僅是像 LangChain 那樣的彈性框架。它在內部處理光學字元辨識 (OCR)、版面偵測、表格擷取和最終輸出格式化的複雜協調工作,省去了您自行建構和調整這些組件所需的大量開發時間。
卓越的掃描件與照片處理能力: 許多文件解析器難以處理非原生數位 PDF。DocStrange 專為處理低解析度掃描件和手機照片等困難輸入而設計,能在高傳真 OCR 至關重要的情境下,提供高品質結果並將錯誤降至最低。
結論
DocStrange 提供了將最具挑戰性的文件格式轉換為 AI 就緒資料所需的準確性、結構和控制能力。透過提供乾淨、LLM 最佳化的輸出,您能加速開發週期,並確保您的 RAG 管道和智慧型應用程式獲得最高品質的結果。
More information on DocStrange
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
DocStrange was manually vetted by our editorial team and was first featured on 2025-10-26.
DocStrange 替代方案
更多 替代方案-

-

-

Parse Extract: 先進的資料萃取與光學字元辨識技術,專為大型語言模型(LLM)管線設計。能將繁雜的文件與網路數據,轉化為清晰易懂、可供LLM使用的文本。兼具成本效益與安全保障。
-

提供結構化 Markdown,最高可將 token 用量節省達 70%,同時保持語義結構完整,並可直接匯入您的 RAG 或代理程式工作流程。無需安裝,順暢無阻——只需上傳,即可立即取得經 AI 優化的輸出內容。
-
