
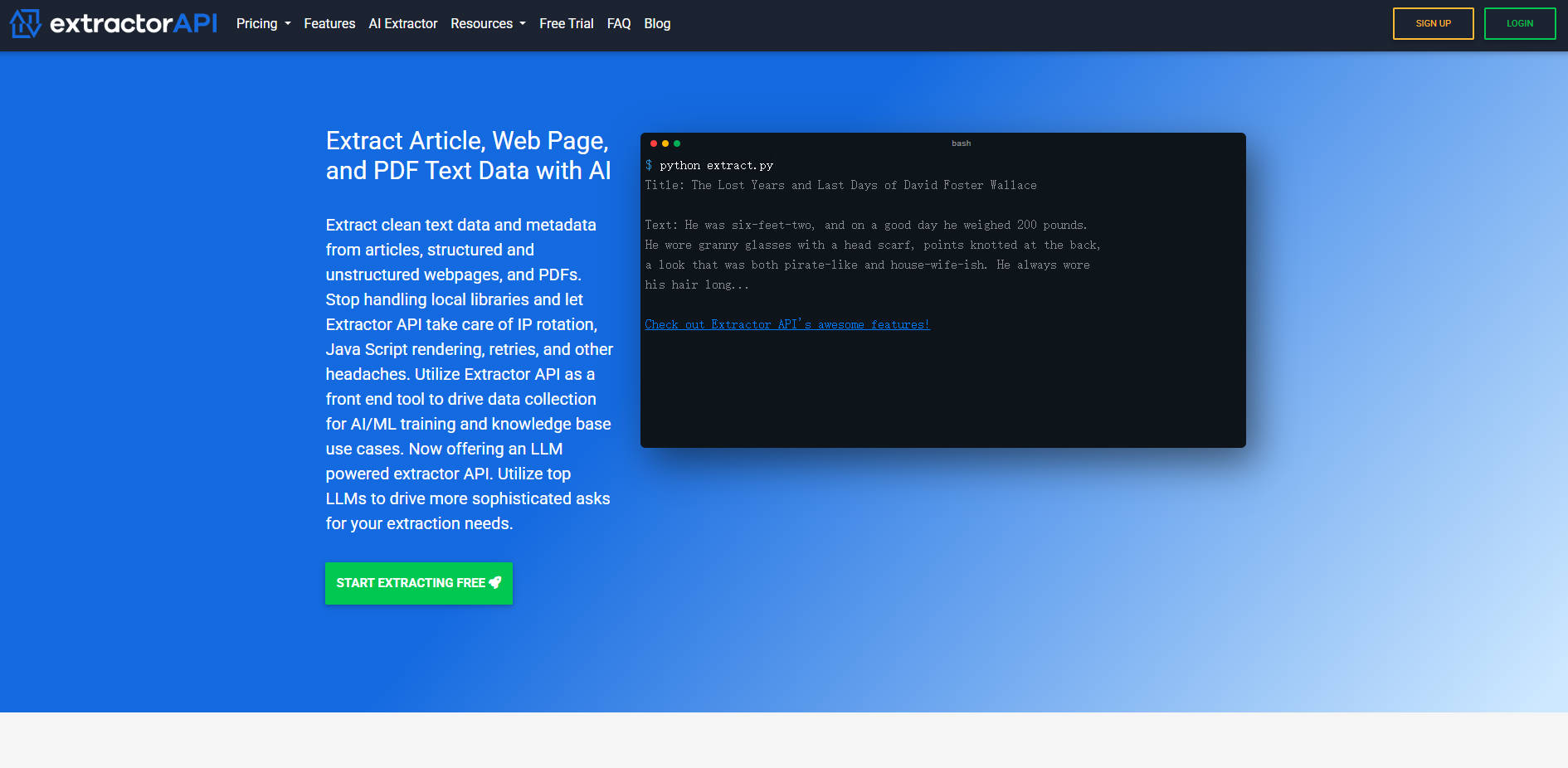
What is Extractor API?
Extractor API 是一個全方位、高效能的文字擷取平台,旨在簡化大規模資料收集。它解決了網路爬蟲固有的技術複雜性——例如處理 IP 輪替、重試機制和動態 JavaScript 渲染——以從文章、結構化/非結構化網頁和 PDF 中,提供清晰、結構化的文字和有價值的後設資料。資料團隊、AI/機器學習工程師以及知識庫建構者可仰賴 Extractor API,有效率且具成本效益地存取過往難以取得的資訊。
主要功能
🔌 無縫的技術韌性
您不再需要管理複雜的基礎設施或本地函式庫。Extractor API 會自動處理常見的擷取難題,包括強固的重試機制、持續的 IP 輪替,以及必要的 JavaScript 渲染(付費方案提供此功能)。這確保了高度的可靠性和可用性,讓您的團隊能專注於資料輸出,而非擷取機制本身。
🧠 LLM 驅動的精細擷取
透過專屬的 LLM 驅動 Extractor API,運用領先模型(包括 OpenAI 和 Google LLMs)的強大功能。這項功能超越了簡單的文字解析,實現了更複雜的擷取需求、在多種網頁格式上更高的準確性,以及透過精準提示與網頁「對話」以獲取細微資訊的獨特能力。
📄 自動化 PDF 資料擷取
輕鬆整合專有本地文件和公開文件的擷取工作流程。此功能自動化了從非結構化 PDF 中擷取關鍵資料集和清晰文字的過程,確保複雜文件格式中寶貴資訊能迅速轉換為可用的資料。
🔎 全球新聞搜尋 API
只需透過一次專屬的 API 呼叫,即可掌握全球新聞動態。新聞搜尋功能每次請求可返回多達 100 條相關結果,並附帶必要的後設資料,為市場情報和趨勢分析所需的即時或歷史資料流提供快速高效的來源。
🖼️ 用於快速部署的視覺化擷取工具
針對快速分析或非 API 工作流程,平台提供直觀的線上視覺化工具。使用者可一次貼上或上傳多達 1,000 個 URL 進行即時文字擷取,並將擷取到的乾淨資料儲存至持久性「任務頁面」(Jobs page),以便日後以 CSV 或 JSON 格式檢索。
使用案例
1. 提升高品質 AI/機器學習訓練資料
資料團隊運用 Extractor API 作為建構可靠資料管道的關鍵第一步。透過從數千個來源收集清晰、結構化的文字和後設資料,您可確保下游的資料倉儲和資料湖接收到高品質的原始資料,進而為您的機器學習模型帶來更精準的訓練和更優異的效能。
2. 建構動態知識庫
快速自動攝取外部資訊,建構全面的知識庫。運用 PDF Data Extraction 功能,從技術白皮書、公開報告或文件擷取關鍵事實和數據,確保您的內部知識系統無需人工輸入,即可永久保持最新狀態。
3. 針對性、複雜的資料品質保證
當標準擷取工具無法處理複雜、高度結構化的頁面(例如詳細的產品規格或研究摘要)時,LLM 驅動的擷取工具能提供解決方案。透過選擇所需的 LLM 並撰寫精確的提示,您可程式化地與網頁內容互動,確保即使是複雜的頁面結構,也能僅擷取到所需、高度特定的資訊。
結論
Extractor API 提供必要的穩健性和精密度,能將複雜的網頁和文件資料轉化為清晰、可付諸行動的情報。透過處理技術前提並提供尖端 AI 工具,它確保您的資料管道可靠、高效,並為進階應用做好準備。
More information on Extractor API
Launched
2020-03
Pricing Model
Freemium
Starting Price
$33/ month
Global Rank
12055209
Follow
Month Visit
<5k
Tech used
Top 5 Countries
44.64%
36.93%
18.42%
India
France
United States
Traffic Sources
5.75%
1.47%
0.17%
9.98%
53.25%
29.08%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Extractor API was manually vetted by our editorial team and was first featured on 2025-10-31.
Extractor API 替代方案
更多 替代方案-

Parse Extract: 先進的資料萃取與光學字元辨識技術,專為大型語言模型(LLM)管線設計。能將繁雜的文件與網路數據,轉化為清晰易懂、可供LLM使用的文本。兼具成本效益與安全保障。
-

-

-

-
