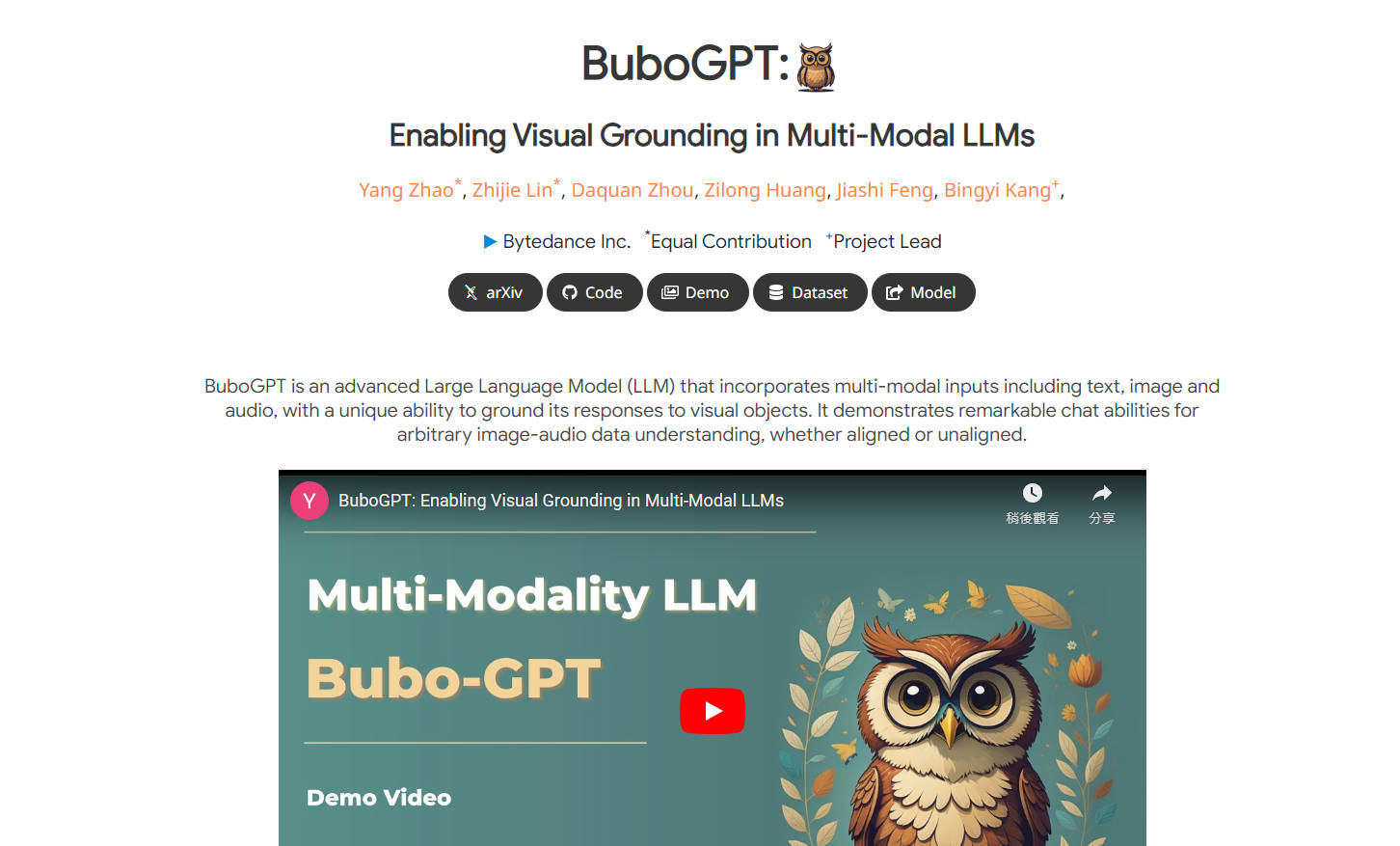
What is BuboGPT?
BuboGPTは、バイトダンス社が開発した高度な大規模言語モデル(LLM)です。テキスト、画像、音声をはじめとするマルチモーダル入力を統合しており、視覚オブジェクトに対する応答を基盤にする独自の機能を備えています。BuboGPTは、アラインされているかどうかにかかわらず、任意の画像音源データを理解する優れたチャット能力を発揮します。
主な特徴:
1. マルチモーダル理解:BuboGPTは、テキスト、ビジョン(画像)、音声など、複数のモーダリティーを同時に理解して処理するように設計されています。あらかじめトレーニングされたモデルともよく一致する一般的なセマンティックスペースを学習し、さまざまな視覚オブジェクトとモーダリティー間のきめ細かい関係を調べます。
2. ビジュアルグラウンディング:入力を粗視なマッピングで構築する他のLLMとは異なり、BuboGPTはテキストと他のモーダリティー間の明確かつ有益な対応関係を通じて、入力の特定部分を基盤にすることができます。これにより、ユーザーエクスペリエンスが向上し、マルチモーダルLLMのアプリケーションのシナリオが拡大します。
3. きめ細かなビジュアル理解:BuboGPTは、さまざまな複雑さを持つさまざまなシナリオで、テクスチャの単語やフレーズを画像の領域に正確に関連付けることができます。基盤の目的で単一画像を入力として分析することで、きめ細かなビジュアル理解を行います。
ユースケース:
1. 画像音源の理解:BuboGPTは、配置の制約なしに任意の画像音源データを理解することに優れています。たとえば、テキストの合図に基づいて画像の領域を正確に説明したり、オーディオクリップに含まれるすべてのアコースティックパートをカバーする有益な説明を提供したりできます。
2. アラインされた音源画像の理解:一致する音源画像のペアが提供された場合、BuboGPTは画像内の対応する視覚要素にサウンドを関連付けることで、効果的にサウンドローカリゼーションタスクを実行できます。
3. 任意の音源画像の理解:入力として提供される音源クリップと画像の間に本質的な配置がない場合、BuboGPTはそれらの関連性を判断し、任意の音源画像の理解に対して高品質の応答を生成できます。
BuboGPTは、テキスト、画像、音声の理解を組み合わせた強力なマルチモーダルLLMです。視覚オブジェクトに対する応答を基盤にするという独自の機能は、他のモデルとは一線を画し、より正確で詳細な言語理解を可能にします。画像音源の理解やきめ細かいビジュアル分析などのさまざまな分野で応用できるBuboGPTは、AIシステムがマルチモーダルデータと対話する方法に革命を起こす可能性を秘めています。
More information on BuboGPT
Launched
2024
Pricing Model
Free
Starting Price
Global Rank
16509734
Follow
Month Visit
<5k
Tech used
cdnjs,Fastly,Google Fonts,Bootstrap,GitHub Pages,jQuery,Gzip,Varnish,HSTS,Amazon AWS S3,YouTube
Top 5 Countries
26.85%
24.53%
20.53%
13.5%
9.49%
Argentina
Iraq
United Kingdom
Taiwan, Province of China
Japan
Traffic Sources
72.61%
27.39%
Search
Referrals
Source: Similarweb (Jul 23, 2024)
BuboGPT was manually vetted by our editorial team and was first featured on 2023-12-07.