
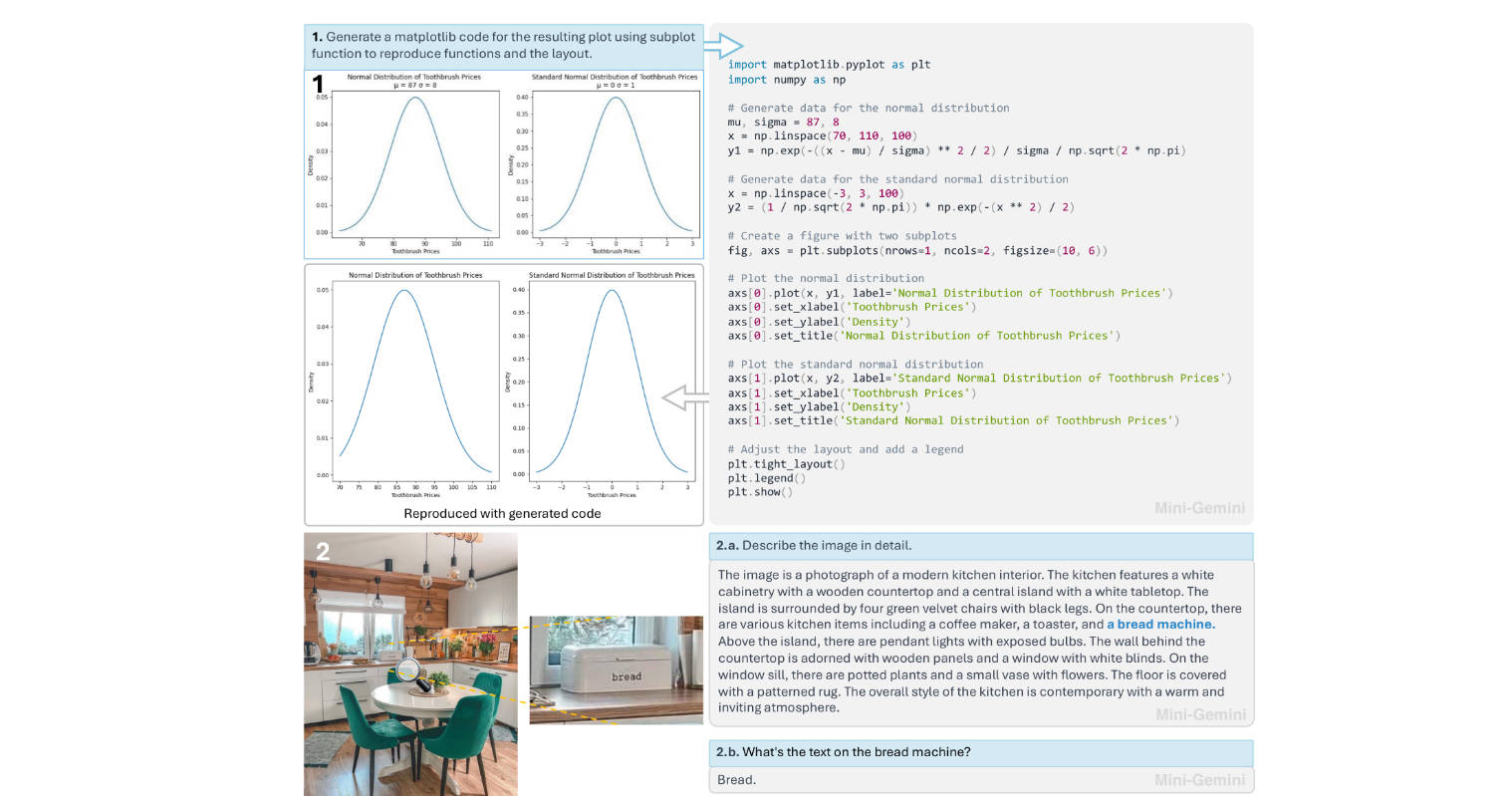
What is Mini-Gemini?
香港中文大学の研究者によって開発されたMini-Geminiは、マルチモーダルなVision Language Model(VLM)を強化する画期的なフレームワークです。高解像度のビジュアルトークン、高品質のデータ、VLMガイドの生成を活用することで、Mini-Geminiは既存のVLMとGPT-4やGeminiのような高度なモデルとのパフォーマンスギャップを埋めます。
主な機能:
? 高解像度のビジュアルトークン:Mini-Geminiは追加のビジュアルエンコーダーを使用して、高解像度のビジュアルトークンを洗練し、トークンの増加なしに画像理解を向上させます。
? 高品質のデータ:特化したデータセットを構築することで、Mini-Geminiは正確な画像認識と推論に基づく生成を促進し、現在のVLMの運用範囲を拡大します。
? VLMガイドの生成:Mini-GeminiはLanguage Model(LLM)を統合して、テキストと画像を同時に理解して生成し、フレームワークの画像理解、推論、生成能力を強化します。
使用事例:
ビジュアルダイアログの強化:Mini-Geminiは、ビジュアル入力を正確に理解して応答することで、チャットボットや仮想アシスタントでビジュアルダイアログを向上させるために展開できます。
画像キャプション:Mini-Geminiは画像の記述的なキャプションを生成することで、画像アノテーションのプロセスを自動化し、コンテンツクリエイターやマーケターにメリットをもたらします。
ゼロショット学習:ゼロショットベンチマークにおけるMini-Geminiの優れたパフォーマンスは、希少疾患の診断や野生生物のモニタリングなど、ラベル付けされたデータが少ないタスクに役立ちます。
結論:
Mini-Geminiは、画像理解、推論、生成機能を強化することで、Vision Language Modelのランドスケープに革命をもたらします。会話型AIからコンテンツ作成まで、さまざまな分野で新しい可能性を切り開くためにMini-Geminiを活用しましょう。
FAQ:
Mini-Geminiは既存のVision Language Modelとどのように異なりますか?Mini-Geminiは、高解像度のビジュアルトークンの洗練、高品質のデータの活用、VLMガイドの生成の統合により、既存のVLMを強化し、優れたパフォーマンスと運用範囲の拡大を実現します。
Mini-GeminiはさまざまなサイズのLanguage Modelで使用できますか?はい、Mini-Geminiは2Bから34Bまでのさまざまな密度の高いMoE Large Language Model(LLM)をサポートし、さまざまな計算リソースとタスク要件に対応します。
Mini-Geminiの現実世界のアプリケーションにはどのようなものがありますか?Mini-Geminiは、チャットボット、画像キャプションシステム、ゼロショット学習タスクなど、AIが視覚情報をやり取りして理解するやり方に革命をもたらす、さまざまなシナリオに適用できます。

More information on Mini-Gemini
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Mini-Gemini was manually vetted by our editorial team and was first featured on 2024-04-15.
Mini-Gemini 代替ソフト
もっと見る 代替ソフト-

Google の高度な AI モデル、Gemini をご紹介します。AI のインタラクションに革命を起こすように設計されています。マルチモーダル機能、洗練された推論、高度なコーディング能力を備えた Gemini は、研究者、教育者、開発者が知識を発見し、複雑な科目を単純化し、高品質のコードを生成することを可能にします。世界中の業界を変革する Gemini の可能性と可能性を探りましょう。
-

-

-

-

Gemma 3 270M: 特定のタスクに特化した、コンパクトかつ超高効率なAI。正確な指示追従と低コストなオンデバイス展開向けにファインチューニング可能。