What is Higgs Audio V2?
超越呆板的語音合成限制。Higgs Audio V2 是一個功能強大、開源的音訊基礎模型,專為需要高度表現力且用途廣泛的音訊生成能力的開發者和研究人員設計。該模型預先訓練了超過 1,000 萬小時的多元音訊資料,能為廣泛的複雜應用提供細緻入微、媲美真人的成果,無需任何微調即可立即使用。
主要功能
🎤 動態多說話者對話生成 在單一音訊輸出中,生成多個說話者之間自然流暢的對話。模型能根據文本內容智能地分配獨特、合適的聲音,或使用您提供的特定參考聲音,這使其成為創建逼真的播客片段、有聲書場景或應用程式對話的理想選擇,無需繁瑣的後製處理。
🗣️ 高傳真零樣本語音複製 能立即從簡短的音訊樣本中複製聲音,並用於生成新的語音。這讓您能以極其簡便的方式,創建客製化旁白、個性化應用程式內音訊,或維持一致的旁白。模型能有效地捕捉參考音訊中獨特的聲音特徵,以實現真實自然的結果。
😊 自動語調與情感適應 Higgs Audio V2 內建對文本語境和情感的理解。它能自動調整語氣、音高和語速,以產生聽起來真情流露、帶有疑問或權威感的語音。這一先進功能已獲得基準測試驗證,在「情感」類別中,其勝率比「gpt-4o-mini-tts」高達 75.7%。
🌐 多功能多語言與旋律生成 該模型展現了其他系統中罕見的能力。它能生成多種語言的語音,實現如即時翻譯等應用。此外,它甚至能以複製的聲音生成旋律哼唱,或同時生成語音與背景音樂,開啟了全新的創作可能性。
為何選擇 Higgs Audio V2?
頂尖效能,無需微調: Higgs Audio V2 在 Seed-TTS Eval 和 ESD 等既定基準測試中,立即取得了頂尖的成果。其在我們 1,000 萬小時的 AudioVerse 資料集上進行的複雜預訓練,意味著您無需花費時間和成本進行模型微調,即可獲得卓越的表現力和功能。
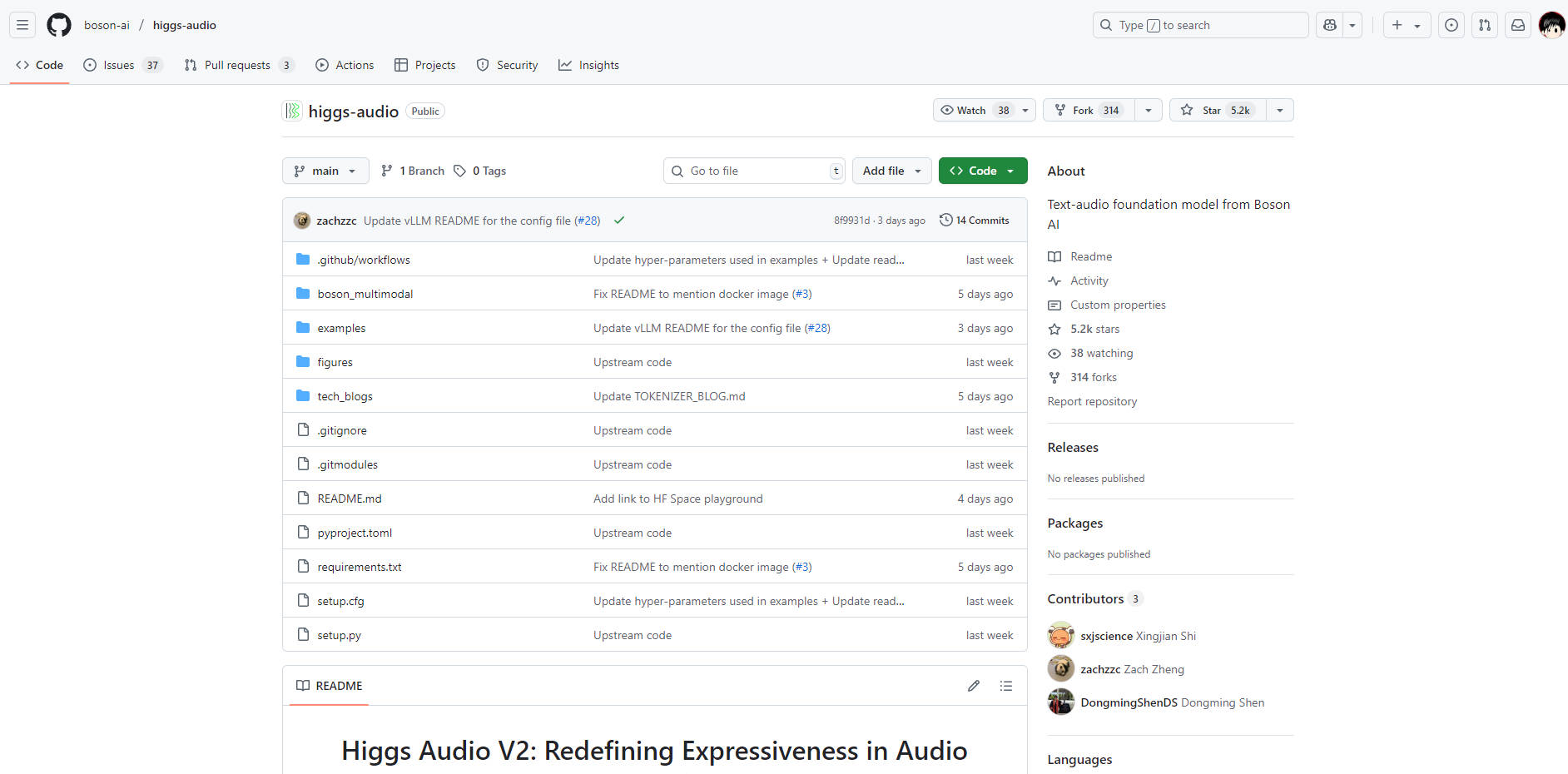
開源,以開發者為核心: 作為一個開源專案,Higgs Audio V2 提供您完全的透明度和基於強大基礎進行建構的自由。我們提供清晰的安裝說明、多種環境設定(包括 venv、conda 和 uv),以及實用的程式碼範例,幫助您快速上手。對於高吞吐量的需求,我們也提供由 vLLM 引擎支援的 OpenAI 相容 API 伺服器。
結論
Higgs Audio V2 代表著富有表現力的音訊合成領域向前邁出了一大步。透過提供一個功能強大、效能卓越且開源的基礎,它賦予您超越傳統 TTS 的能力,並建構出更動態、更引人入勝且更擬人化的音訊體驗。
立即瀏覽儲存庫以查看範例並開始使用!
More information on Higgs Audio V2
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Higgs Audio V2 was manually vetted by our editorial team and was first featured on 2025-07-27.
Related Searches