
What is Voxtral?
由 Mistral AI 開發的 Voxtral 是一款先進的語音理解模型,旨在克服語音互動常見的高成本、準確性不可靠以及封閉專有系統限制等挑戰。它為開發人員和企業提供一個功能強大、開放且可立即投入生產的平台,以便建構下一代先進的語音驅動應用程式。
主要特色
🗣️ 整合式音訊智慧 Voxtral 不僅能將語音轉換為文字,更內建了針對音訊內容進行摘要和直接問答的功能。這消除了連結獨立的自動語音辨識 (ASR) 和語言模型的需求,讓您能透過單一高效的流程,輕鬆提取音訊中的洞察。
⚡ 語音直接呼叫功能 將您的語音指令轉化為即時行動。Voxtral 能夠原生理解使用者意圖,並直接觸發後端功能、工作流程或 API 呼叫。這讓您能夠建立真正互動式的體驗,使用者可以僅透過語音控制應用程式,無需複雜的中介解析步驟。
🌐 優越的長篇與多語言效能 讓您自信地處理長篇音訊。憑藉 32K token 的上下文視窗,Voxtral 能處理長達 40 分鐘的音訊理解任務。它還具備自動語言偵測功能,並在世界上使用最廣泛的語言中,包括英語、西班牙語、法語、德語和印地語,提供最先進的準確性,讓您能僅用一個模型服務全球使用者。
⚙️ 開放且彈性的部署 您可以完全控制 Voxtral 的使用方式。它在寬鬆的 Apache 2.0 授權下發布,提供 240 億參數模型(適用於生產規模應用)和 30 億參數模型(適用於高效的本地及邊緣部署)。這種彈性讓您能夠為特定的應用場景,選擇效能與效率的最佳平衡點。
獨特優勢
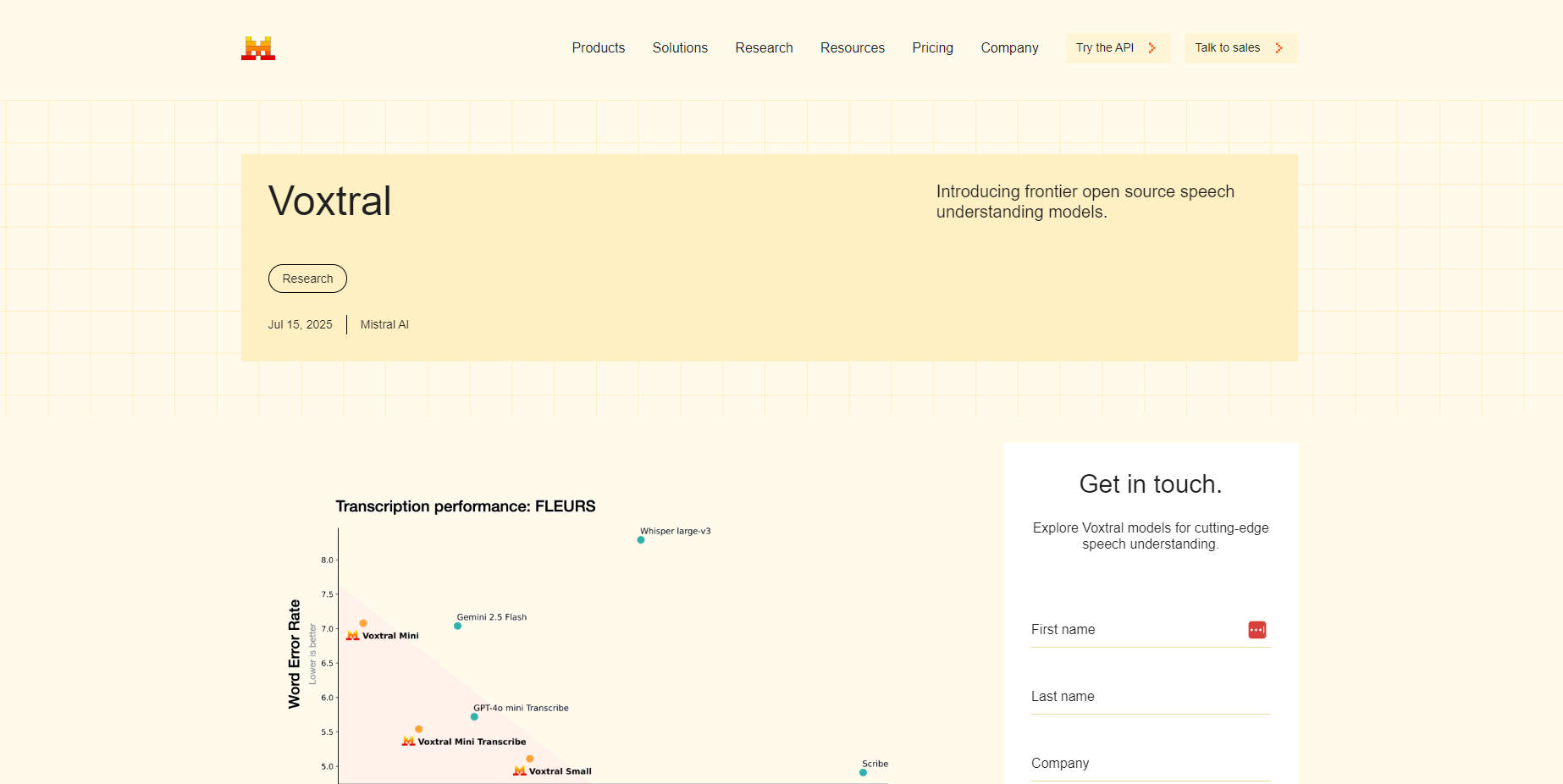
以極低成本實現最先進效能 Voxtral 彌補了有限開源工具與昂貴專有 API 之間的差距。基準測試顯示,它不僅全面超越了 Whisper large-v3 等領先模型,更能與高階 API 匹敵,而成本卻不到同類服務的一半。您無需再為了負擔得起而犧牲品質。
真正的開放性與掌控度 不同於「黑盒子」解決方案,Voxtral 的開源基礎賦予您自由,能在自己的基礎設施上部署,以實現最大的資料隱私和掌控度。這使您能夠針對專業領域(例如醫療、法律)對模型進行微調,並將其深度整合到您的技術堆疊中,從而避免供應商鎖定。
結論:
Voxtral 不僅僅是個轉錄工具;它是一個全面的語音理解平台。它讓您能夠建構真正互動式且智慧的語音應用程式,具有無與倫比的準確性、彈性和成本效益。無論您是進行大規模部署或在本地機器上進行原型開發,Voxtral 都能提供您所需的堅實基礎。
立即探索文件或下載模型,開始建構!
常見問題
1. Voxtral 與標準轉錄 API 的主要差異是什麼? Voxtral 與標準轉錄 API 的主要差異在於,標準轉錄 API 主要將語音轉換為文字,而 Voxtral 則透過整合深度語言理解,向前邁進了重要一步。這表示您不僅可以使用它來轉錄音訊,還可以在單一模型中,針對內容進行提問、產生摘要,甚至直接透過語音指令觸發軟體功能。
2. 我可以在自己的伺服器上執行 Voxtral 以保護資料隱私嗎? 是的,當然可以。Voxtral 在 Apache 2.0 授權下發布,賦予您將模型(包括 240 億和 30 億參數版本)完整下載並部署在您自有基礎設施的權利。這非常適合受監管行業中的應用,或任何將資料隱私和掌控度視為首要考量的使用場景。
3. Voxtral 如何處理多語言音訊? Voxtral 具備自動語言偵測功能。您只需將音訊輸入給它,它便會自動識別語言並以高準確度進行轉錄,無需您預先指定來源語言。它針對世界上最常用的語言進行了最佳化,以提供頂級效能,使其成為全球應用程式的多功能工具。
More information on Voxtral
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Voxtral was manually vetted by our editorial team and was first featured on 2025-07-17.
Related Searches
Voxtral 替代方案
更多 替代方案-

Ultravox.ai: Next-gen enterprise Voice AI for human-like, real-time conversations. Scale massively, eliminate lag & power smarter agents.
-
-

-
-
