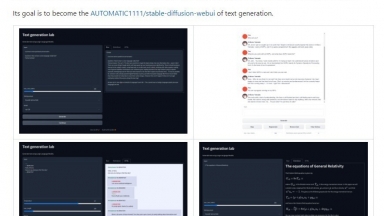
 Text Generation WebUI
Text Generation WebUI
 Text Generator Plugin
Text Generator Plugin
Text Generation WebUI
| Launched | 2023 |
| Pricing Model | Free |
| Starting Price | |
| Tech used | |
| Tag | Text Generators |
Text Generator Plugin
| Launched | 2022-11 |
| Pricing Model | Free |
| Starting Price | |
| Tech used | Fastly,JSDelivr,GitHub Pages,KaTeX,Varnish |
| Tag | Script Generators,Sentence Generators |
Text Generation WebUI Rank/Visit
| Global Rank | 0 |
| Country | |
| Month Visit | 0 |
Top 5 Countries
Traffic Sources
Text Generator Plugin Rank/Visit
| Global Rank | 1663259 |
| Country | United States |
| Month Visit | 12872 |
Top 5 Countries
Traffic Sources
Estimated traffic data from Similarweb
What are some alternatives?
LoLLMS Web UI - LoLLMS WebUI: Access and utilize LLM models for writing, coding, data organization, image and music generation, and much more. Try it now!
Open WebUI - User-friendly WebUI for LLMs (Formerly Ollama WebUI)
ChattyUI - Open-source, feature rich Gemini/ChatGPT-like interface for running open-source models (Gemma, Mistral, LLama3 etc.) locally in the browser using WebGPU. No server-side processing - your data never leaves your pc!
LLMLingua - To speed up LLMs' inference and enhance LLM's perceive of key information, compress the prompt and KV-Cache, which achieves up to 20x compression with minimal performance loss.