What is CLIPSeg?
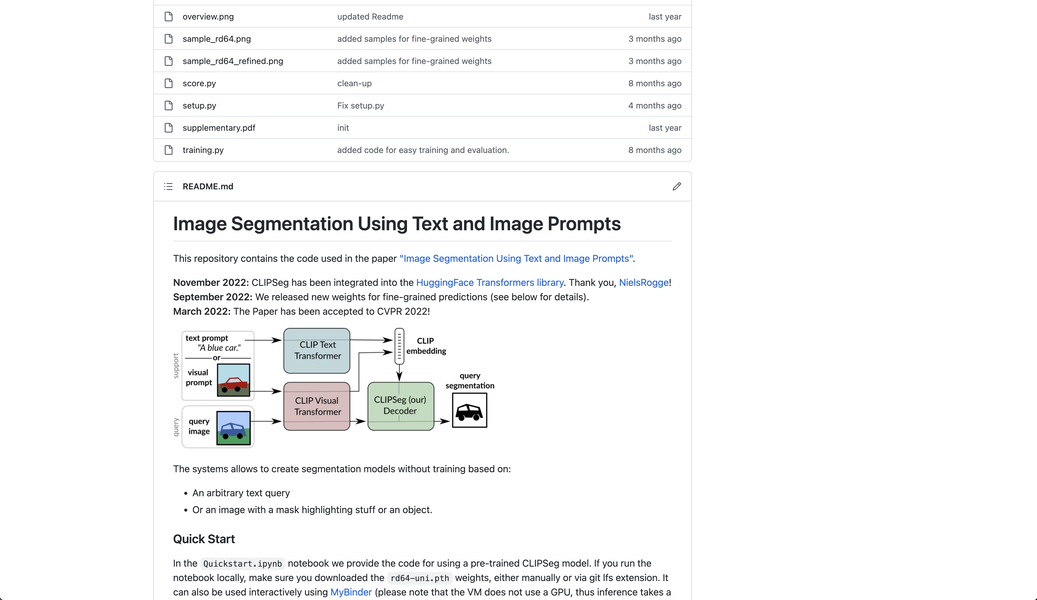
CLIPSeg は、テキストまたは画像プロンプトに基づいて画像セグメンテーションを可能にする AI ツールです。これは CLIP モデルをデコーダーで拡張し、ゼロショットおよびワンショット画像セグメンテーションを可能にします。この汎用性の高いツールは、参照表現セグメンテーション、ゼロショットセグメンテーション、ワンショットセグメンテーションなど、さまざまなセグメンテーションタスクを処理できます。
主な特徴:
1. デコーダー拡張: CLIPSeg は CLIP モデルの上に最小限のデコーダーを追加し、プロンプトに基づいて画像セグメンテーションを可能にします。
2. プロンプトの柔軟性: ユーザーはテキストまたは画像の形式でプロンプトを提供することができ、さまざまなセグメンテーションタスクに動的に適応できます。
3. 統一モデル: CLIPSeg は、複数のセグメンテーションタスクを処理できる統一モデルを提供し、タスクごとに個別のモデルを必要としません。
使用例:
1. 参照表現セグメンテーション: CLIPSeg は、画像内の特定のオブジェクトまたは領域を説明するテキストプロンプトに基づいて画像セグメンテーションを生成できます。
2. ゼロショットセグメンテーション: CLIPSeg を使用すると、ユーザーはトレーニング中に含まれていなかったオブジェクトクラスの画像セグメンテーションを生成し、モデルの機能を拡張できます。
3. ワンショットセグメンテーション: CLIPSeg を使用すると、ユーザーは単一の画像プロンプトに基づいて画像セグメンテーションを生成できるため、限られた情報しかないシナリオに役立ちます。
結論:
CLIPSeg は、プロンプトに基づいて画像セグメンテーションを可能にすることで CLIP モデルの機能を強化する強力な AI ツールです。そのデコーダー拡張とプロンプトの柔軟性により、参照表現セグメンテーション、ゼロショットセグメンテーション、ワンショットセグメンテーションなど、さまざまなセグメンテーションタスクに適しています。統一モデルを提供することで、CLIPSeg はセグメンテーションプロセスを簡素化し、さまざまな分野での潜在的な応用を提供します。
More information on CLIPSeg
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Amazon AWS CloudFront,cdnjs,Google Fonts,KaTeX,RSS,Stripe
CLIPSeg was manually vetted by our editorial team and was first featured on 2023-03-07.
Related Searches
CLIPSeg 代替ソフト
もっと見る 代替ソフト-
CLIP Interrogatorは、OpenAIのCLIPとSalesforceのBLIPを組み合わせたプロンプトエンジニアリングツールで、与えられた画像に一致するテキストプロンプトを最適化します。
-

Segment Anythingを発見、画像のセグメンテーションのためのAIツールです。プロンプトタスクとSAMアーキテクチャで正確なセグメンテーションを生成。さまざまなユースケースに適しており、リアルタイムの対話が可能。
-
-
-