
What is Sliq?
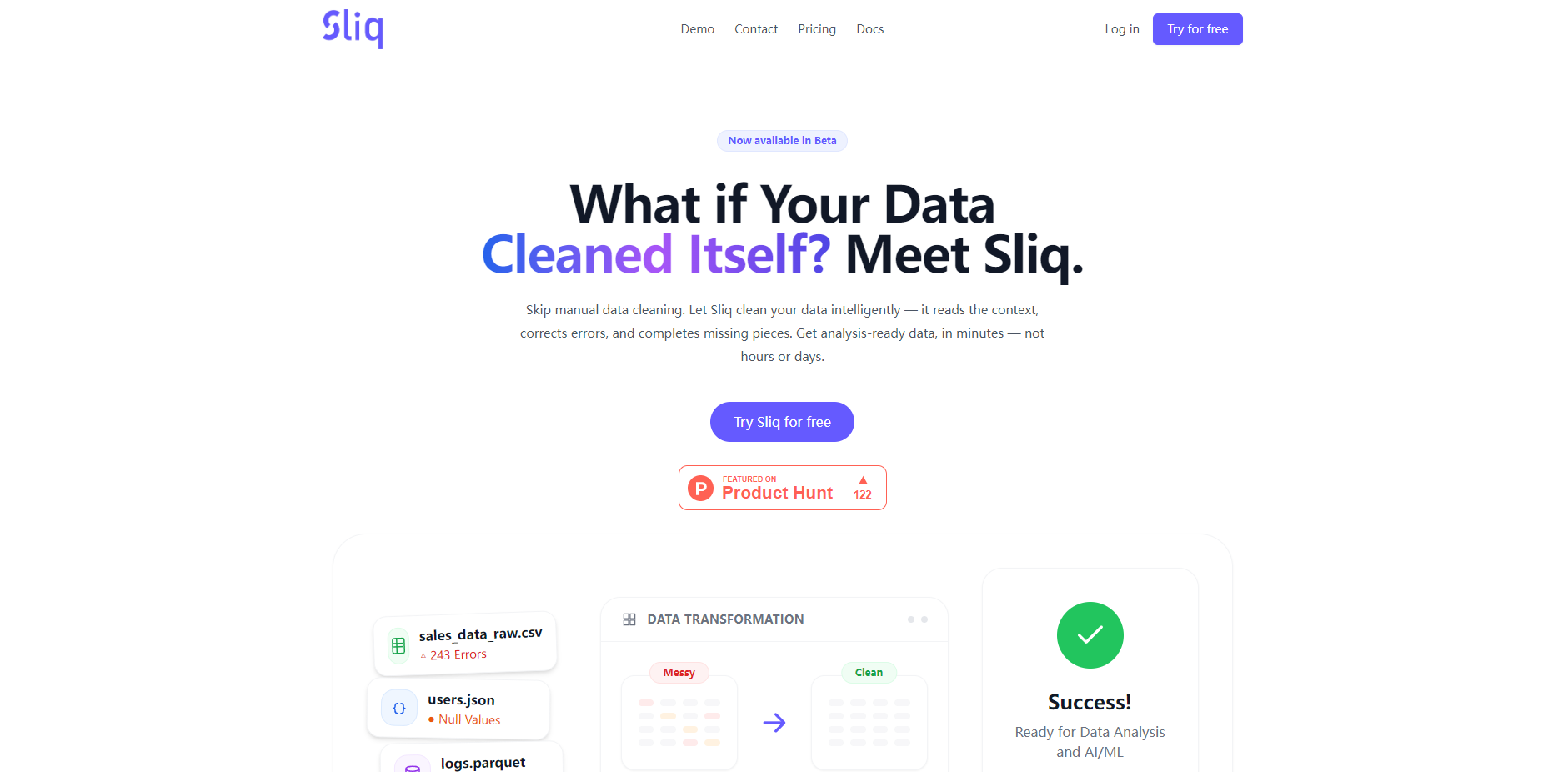
Sliq is an AI-Powered Data Cleaning Platform designed to eliminate the manual burden of data preparation. It intelligently corrects schema issues, fills missing values, and resolves formatting errors, delivering analysis-ready datasets to data analysts and engineers in minutes, not hours or days. By automating the most time-consuming aspects of ETL, Sliq ensures your data foundation is accurate and ready for immediate business intelligence, reporting, or AI/ML model training.
Key Features
Sliq provides the essential automation and deep understanding required to transform raw, messy inputs into verified clean data suitable for immediate analysis.
🧹 Intelligent Automated Cleaning Pipeline
Sliq automatically detects and fixes the most common and complex data quality issues, including missing values (nulls), inconsistent formatting, and structural schema errors. The system reads the context of the raw data, applies intelligent corrections, and completes missing pieces, ensuring the integrity and consistency of your dataset without manual intervention.
🌐 Comprehensive Format Support
Work within your existing data ecosystem seamlessly. Sliq handles a wide array of popular data formats and structures, allowing you to upload raw files or pass DataFrames directly. Supported formats include Excel, CSV, JSON, Parquet, and native integration with popular libraries like Pandas and Polars.
🚀 Flexible Workflow Integration
Whether you prefer a visual interface or command-line automation, Sliq supports your workflow. Utilize the Sliq Dashboard to upload datasets, monitor cleaning jobs, and download results via a user-friendly UI. Alternatively, integrate the powerful Sliq Python library (SDK) directly into scripts, notebooks, and production pipelines to trigger and manage automated cleaning jobs.
🧠 Context-Aware Interpretation
Unlike basic cleaning scripts, Sliq understands your data’s domain. By leveraging contextual inputs (such as description, purpose, or column descriptions), Sliq makes intelligent cleaning decisions tailored to the industry—be it finance, healthcare, or retail—ensuring transformations are accurate, appropriate, and avoid unintended data distortions.
Use Cases
Sliq accelerates critical data workflows, allowing teams to shift focus from preparation to insight generation.
1. Accelerating Ad-Hoc Analysis
A data analyst receives a raw sales data CSV file (sales_data_raw.csv) containing 243 formatting errors and various null values. Instead of spending half a day writing custom scripts to standardize names and impute missing entries, the analyst uploads the file to the Sliq Dashboard. Sliq processes the dataset instantly, generating a verified clean file ready for immediate pivot table creation and reporting, shrinking preparation time from hours to under 10 minutes.
2. Streamlining Production ETL Pipelines
A data engineer needs to incorporate unstructured log data (logs.parquet) into a daily reporting database. Using the Sliq Python library, the engineer integrates a cleaning job directly into the existing ETL script. The job is triggered automatically, ensuring that the unstructured logs are consistently standardized and transformed before being loaded into the warehouse, guaranteeing that downstream models and dashboards receive high-quality input every cycle.
3. Rapid Feature Engineering for AI/ML
A data science team is preparing multiple diverse datasets for a new predictive model. They utilize Sliq's API with the optional is_feature_engineering flag enabled. Sliq not only cleans the raw input but also performs automated feature engineering, generating valuable derived features based on the data's context. This significantly reduces the manual effort required to prepare training sets, allowing the team to iterate on model designs faster.
Why Choose Sliq?
Sliq offers tangible advantages rooted in optimized engineering and intelligent design, ensuring superior performance and integration compared to traditional manual or script-based cleaning methods.
Lightning Fast Processing
Sliq is built for scale. Our highly optimized engine is engineered to handle heavy lifting, allowing you to process gigabytes of messy data in minutes, rather than waiting hours for traditional processing methods or resource-intensive notebooks to complete. This efficiency is crucial for real-time applications and large-scale data lake management.
Domain-Specific Accuracy
By being "Context Aware," Sliq achieves a higher level of accuracy in imputation and correction. The system utilizes descriptions you provide about the dataset’s domain and purpose to intelligently interpret values. For example, it can differentiate between a missing ZIP code in a retail dataset and a missing medical code in a healthcare dataset, preventing generic or misleading transformations.
Seamless Integration
Sliq ensures minimal disruption to your current environment. With dedicated access points via the intuitive Dashboard and the robust Python SDK, you can easily connect Sliq into existing cloud storage, data lakes, and analytical workflows for a unified and scalable data preparation experience.
Conclusion
Sliq fundamentally shifts the paradigm of data preparation, replacing tedious manual labor with intelligent, lightning-fast automation. By consistently delivering verified clean data in minutes, Sliq empowers data professionals to focus their expertise on analysis and innovation, maximizing the value derived from every dataset.
More information on Sliq
Launched
2025-12
Pricing Model
Freemium
Starting Price
$25 / month
Global Rank
Follow
Month Visit
<5k
Tech used
Sliq was manually vetted by our editorial team and was first featured on 2025-12-19.
Sliq 대체품
더보기 대체품-

데이터 클리너: 한 번의 클릭으로 지저분한 데이터를 정리합니다. 안전하고 다국어를 지원하며, 사용자 정의가 가능합니다. 분석가, 과학자 등을 위한 제품입니다.
-

데이터 분석이 간편해지는 비즈니스 인텔리전스 플랫폼, DataSquirrel.ai를 만나보세요. 자동 데이터 정제, 자동 분석, 자동 시각화 기능으로 데이터 분석 시간을 절약하고, 더욱 빠르고 현명한 의사결정을 내리세요.
-

-
-

Cloudsquid: AI 기반 문서 데이터 추출 솔루션. PDF, 스캔 문서 등에서 데이터를 추출하고, 워크플로우 자동화, 원활한 통합, 효율성 증대를 경험하세요.