
Click outside to close
What is VALL-E-X?
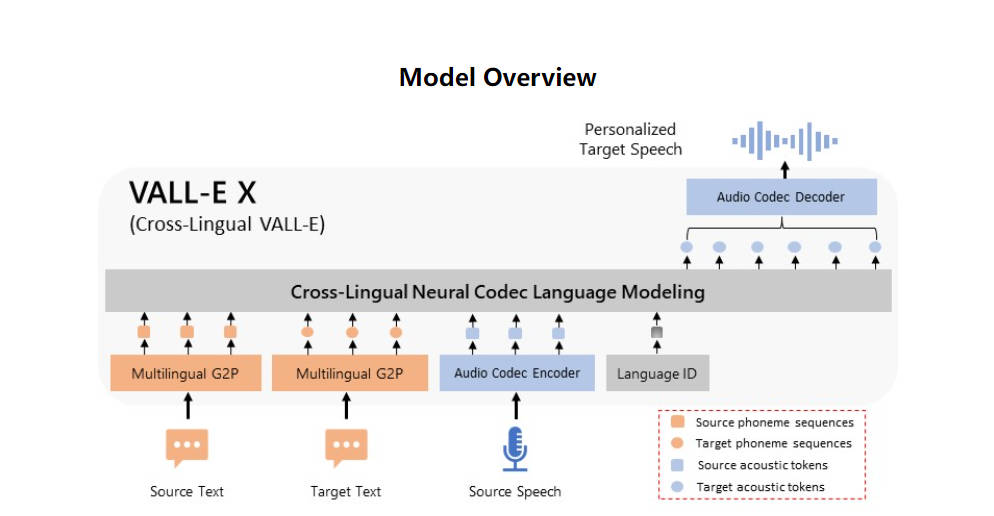
VALL-E X is an open-source implementation of Microsoft's VALL-E X zero-shot TTS model. It is a multilingual text-to-speech (TTS) model that allows users to generate natural and expressive speech in English, Chinese, and Japanese. The model offers several key features, including multilingual TTS, zero-shot voice cloning, speech emotion control, zero-shot cross-lingual speech synthesis, accent control, and acoustic environment maintenance. VALL-E X can be used for various purposes, such as creating personalized speech, experimenting with different accents, and generating speech in different languages. The model is easy to use and supports both CPU and GPU. It is available for research and application usage, and the trained model can be downloaded for free. With its advanced functionalities and user-friendly interface, VALL-E X is a powerful tool for voice cloning and multilingual speech synthesis.
Key Features:
1. Multilingual TTS: VALL-E X supports speech synthesis in three languages - English, Chinese, and Japanese. It generates natural and expressive speech, allowing users to create audio content in multiple languages.
2. Zero-shot Voice Cloning: With VALL-E X, users can enroll a short recording of an unseen speaker and generate personalized speech that sounds just like them. This feature enables the creation of high-quality speech with the same tone, pitch, and emotion as the original speaker.
3. Speech Emotion Control: VALL-E X adds an extra layer of expressiveness to audio by synthesizing speech with the same emotion as the provided acoustic prompt. Users can control the emotional tone of the generated speech, enhancing the overall impact of the audio content.
Use Cases:
1. Personalized Speech Generation: VALL-E X's zero-shot voice cloning feature is particularly useful for creating personalized speech content. It can be used to generate audio content with the voice of a specific person, character, or even the user's own voice. This can be valuable for applications such as voiceovers, virtual assistants, and audiobook narration.
2. Accent Experimentation: VALL-E X allows users to experiment with different accents. It enables users to speak in one language with the accent of another language, adding a creative touch to audio content. This feature can be beneficial for language learning, entertainment, and cultural expression.
3. Multilingual Speech Synthesis: VALL-E X supports cross-lingual speech synthesis, enabling monolingual speakers to generate personalized speech in another language. This feature is valuable for communication, language translation, and cultural exchange. For example, a Japanese speaker can use VALL-E X to speak in Chinese or English while maintaining fluency and accent.
VALL-E X is a powerful multilingual text-to-speech model that offers cutting-edge functionalities for speech synthesis and voice cloning. With its ability to generate natural and expressive speech in multiple languages, control speech emotion, and experiment with accents, VALL-E X provides users with a versatile tool for creating personalized and impactful audio content. Whether for professional use or personal projects, VALL-E X is a valuable resource that opens up new possibilities in voice cloning and multilingual speech synthesis.
More information on VALL-E-X
VALL-E-X was manually vetted by our editorial team and was first featured on 2023-11-09.
VALL-E-X Alternatives
VALL-E-X Alternatives-

VibeVoice: Free online AI text-to-speech. Instantly create realistic, multi-speaker audio conversations up to 90 mins. No downloads or signup!
-

All Voice Lab is the AI voice platform for ultra-realistic TTS & voice cloning. Powered by SOTA MaskGCT 2.0 model. Multilingual, expressive audio for creators & devs.
-
Discover OpenVoice V2, the latest AI voice cloning innovation! Enjoy superior audio fidelity, multi-lingual support, and versatile voice control for free commercial use.
-
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech).
-

Introducing Voicebox, the groundbreaking generative AI model for speech synthesis and manipulation. Enhance communication and revolutionize virtual experiences with versatile, accurate, and multi-language Voicebox.