What is Diffbot?
輕鬆將網頁轉換成結構化數據,使用 Diffbot,無需規則,毫不費力。只需為您的 AI、分析或業務需求提供乾淨、可操作的洞察。
為什麼選擇 Diffbot?
網路是資訊的寶庫,但它凌亂且結構鬆散。Diffbot 利用 AI、電腦視覺和機器學習,像人類一樣閱讀網站,將數據提取並組織成可用的格式——無論是新聞文章、產品詳情還是公司簡介。
主要功能
? 從任何網站提取數據:刮取文章、產品頁面、討論等,無需編寫複雜的規則。
? 知識圖譜:訪問全球最大的結構化人物、組織、產品和新聞數據集——超過 100 億個實體,且仍在持續增加。
? 自然語言處理:超越關鍵字。從原始文本中提取實體、關係和情感。
? 大規模爬取:在幾分鐘內將整個網站轉換成結構化數據庫。
? API 存取:透過 REST API 無縫整合,快速輕鬆地擷取數據。
適用對象
? 商業分析師:透過公司圖像數據豐富您的數據集,追蹤市場趨勢或監控競爭對手的活動。
? 開發人員:利用即時存取結構化網頁數據,建立 AI 驅動的應用程式。
? 內容團隊:提取和分析新聞文章或產品數據,以進行市場研究。
? 投資者:追蹤情感和關係,做出更明智的投資決策。
真實案例
1️⃣ 市場監控:一家全球金融服務公司使用 Diffbot 追蹤公司相關的情緒,並以此指導投資決策。
2️⃣ 潛在客戶開發:銷售團隊透過知識圖譜中的洞察豐富 CRM 數據,以識別高價值潛在客戶。
3️⃣ 內容推薦:像 Dianomi 這樣的原生廣告網路使用 Diffbot 將廣告與相關且品牌安全的內容相匹配。
4️⃣ 學術研究:JSTOR 與 HBO 合作,利用 Diffbot 的自然語言 API 將歷史記錄轉錄生動化。
立即開始
無需信用卡。完整 API 存取權限。立即開始將網頁轉換成可操作的數據。
常見問題
問:Diffbot 是否適用於所有網站?
答:是的!Diffbot 的 AI 可以從任何網站提取數據,無論其語言或結構。
問:Diffbot 與傳統網頁抓取有何不同?
答:與基於規則的抓取器不同,Diffbot 使用 AI 自動分類和提取網頁中的關鍵屬性——無需手動設定。
問:我可以自定義數據提取流程嗎?
答:當然可以。Diffbot 的 API 非常靈活,您可以訓練其自然語言模型,使其專注於您的特定領域或實體。
問:它安全嗎?
答:是的,Diffbot 遵守嚴格的數據安全標準,以保護您的資訊並確保合規性。




More information on Diffbot
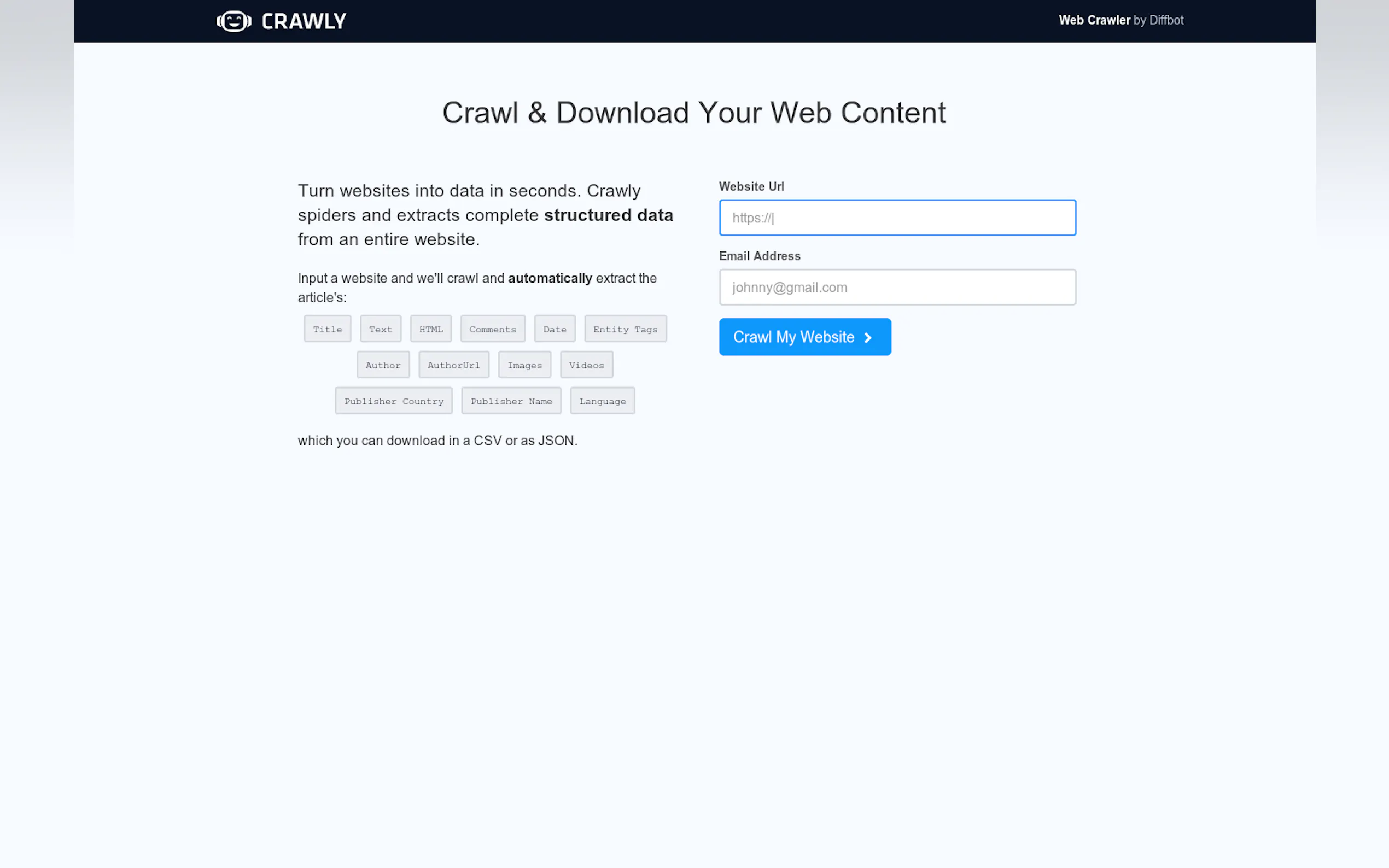
Top 5 Countries
29.2%
6.32%
5.33%
5.03%
5%
United States
Germany
India
Vietnam
Nigeria
Traffic Sources
3.38%
1.08%
0.12%
8.95%
46.43%
39.88%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Diffbot was manually vetted by our editorial team and was first featured on 2023-12-17.
Related Searches
Diffbot 替代方案
更多 替代方案-

別再與網路爬蟲阻擋機制纏鬥了。WebScraping.AI API 能為您全權處理 JS、代理伺服器與驗證碼等問題,更運用 AI 進行智慧資料擷取與分析。
-
-

-
-