
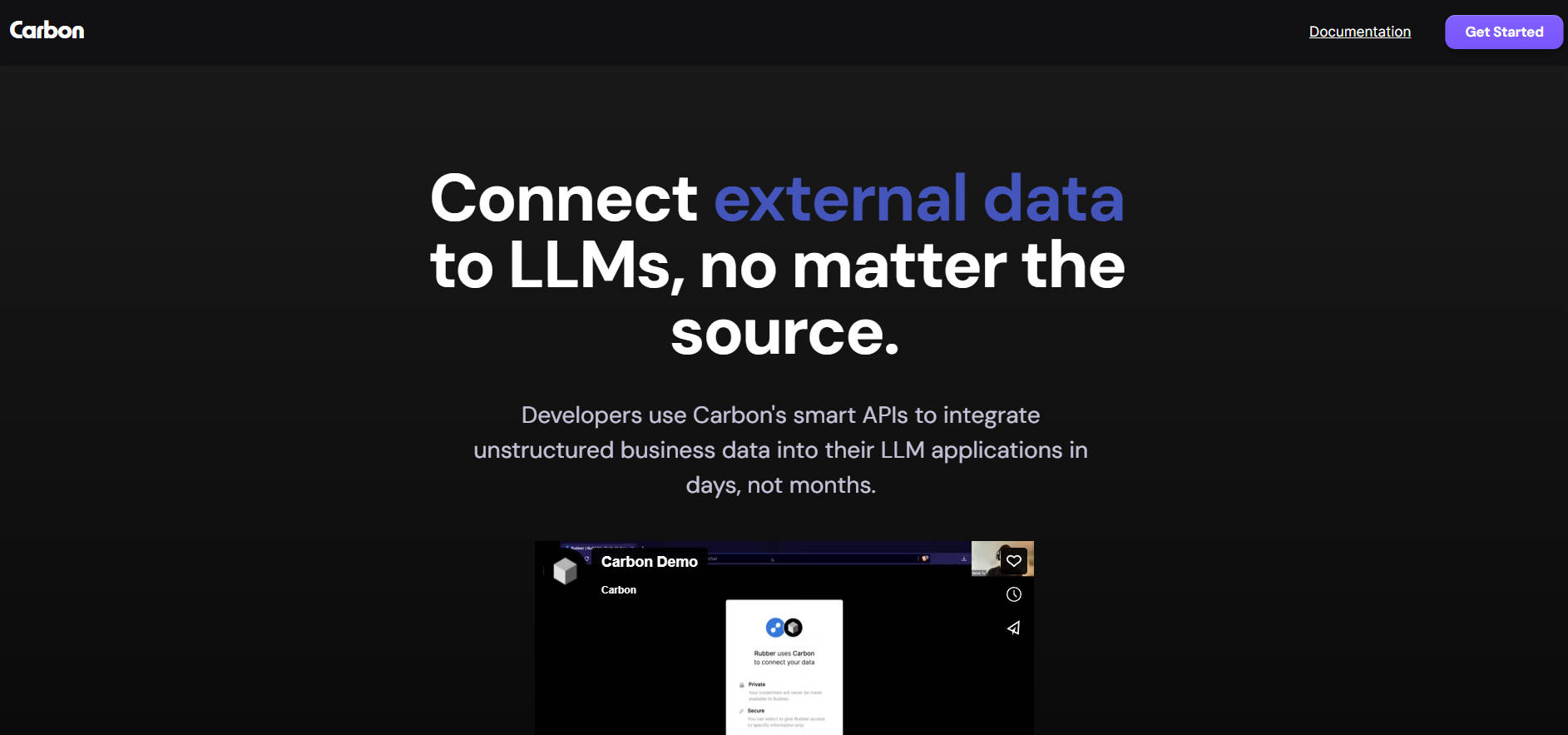
What is Carbon?
Carbon is a software that allows developers to connect external data to LLM applications using smart APIs. It enables integration of unstructured business data into LLM applications in a matter of days.
Key Features:
Integration of external data into LLM applications
Smart APIs for seamless data integration
Support for various data sources including local files, web content, and 3rd party services
Usage-based pricing model for cost optimization
Ready-made components for file upload, web scraping, and 3rd party authentication
Document management capabilities
Semantic search for unstructured data
SOC 2 compliance and white label options
High reliability with 99.5% SLAs and auto scaling
24/7 support from engineers and managed OAuth for third-party services
Custom builds and usage reporting
Carbon is a software solution that simplifies the integration of external data into LLM applications. With its smart APIs, developers can connect unstructured business data to LLM applications swiftly. Carbon supports various data sources and offers ready-made components for ease of use. Its usage-based pricing model ensures cost optimization. Additionally, it provides document management, semantic search, and compliance features. With reliable performance and extensive support, Carbon enables efficient data utilization at scale.
More information on Carbon
Launched
2017-12-16
Pricing Model
Starting Price
Global Rank
3900418
Country
United States
Month Visit
17.1K
Tech used
Framer,Google Fonts,Gzip,OpenGraph,HSTS
Top 5 Countries
19.81%
6.56%
5.39%
5.04%
4.62%
United States
Turkey
Indonesia
Viet Nam
Peru
Traffic Sources
69.29%
21.96%
4.67%
4.08%
Direct
Search
Social
Referrals
Updated Date: 2024-04-30
Carbon was manually vetted by our editorial team and was first featured on September 4th 2024.
Related Searches
Carbon Alternatives
Load more Alternatives-

Baseplate Connect seamlessly connects data to LLM apps. Enjoy fast retrieval workflows, hybrid search, and easy deployment options.
-

With CarbonCopy Artificial Intelligence you can create ad copy, product descriptions, images, audio and more - easily!
-
Incorporating AI into your products has never been more effortless. LLMRails's models enable dynamic chat functionalities, generate compelling text for product descriptions, blog posts, and articles, and comprehend the essence of text for search purposes, content moderation, and intent identification.
-
Carbonate is an AI-driven automated end-to-end testing that integrates directly into your testing fr
-

LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language