






Click outside to close
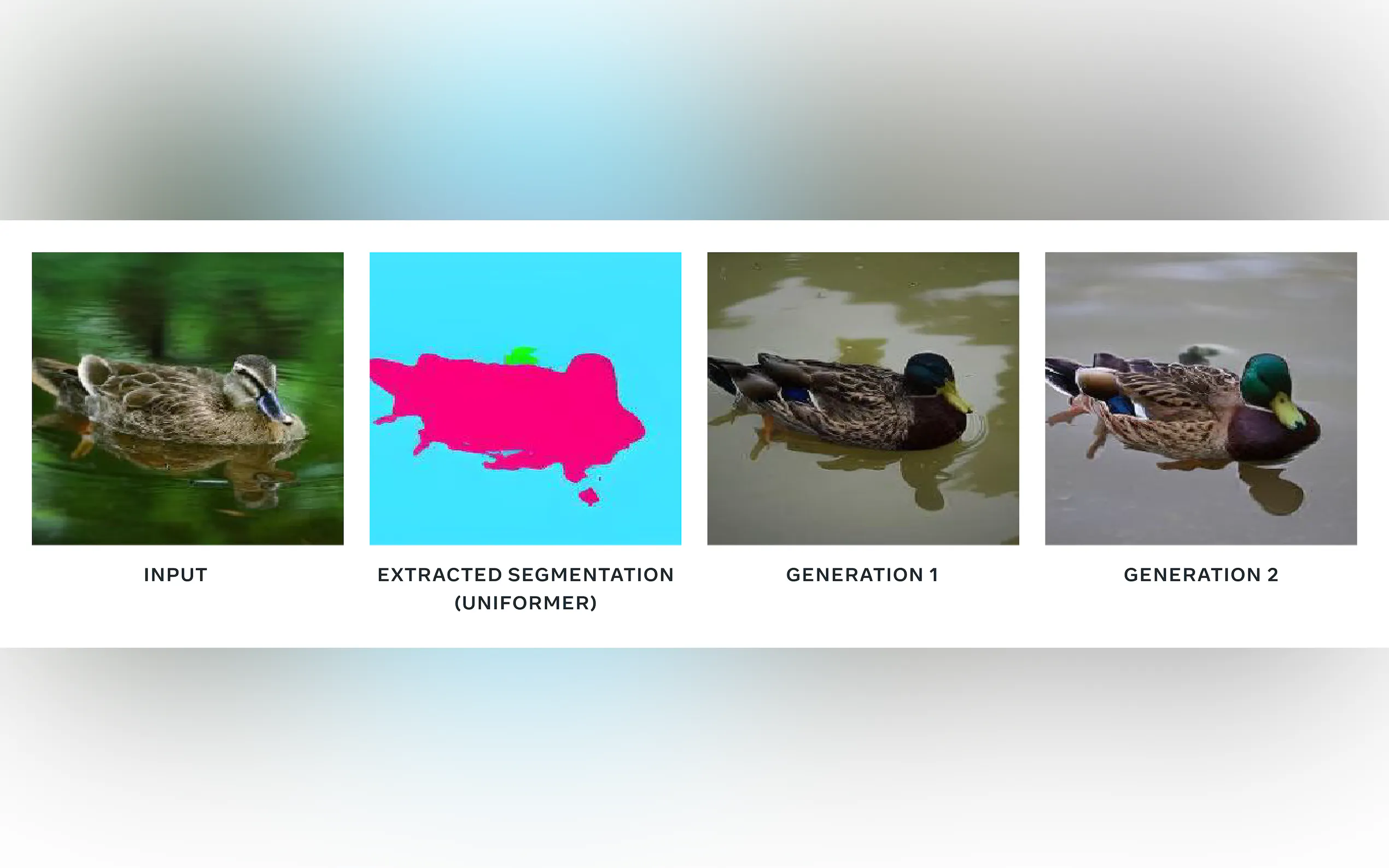
What is CM3leon?
CM3leon, a groundbreaking multimodal generative AI model, ushers in a new era of versatility and efficiency in text-to-image and image-to-text generation. Developed using a novel approach adapted from text-only language models, CM3leon excels in creating coherent images from textual prompts and vice versa. Its architecture, a decoder-only transformer, enables it to handle a diverse range of tasks, from image caption generation to visual question answering. With its state-of-the-art performance and impressive efficiency, CM3leon stands as a testament to the potential of retrieval augmentation and scaling strategies in autoregressive models.
Key Features
Dual Modalities📝➡️🖼️🖼️➡️📝: CM3leon seamlessly transitions between text and image, offering unparalleled flexibility in generative AI.
Efficient Training⚙️: Trained with significantly less compute than previous methods, CM3leon maintains high performance while reducing costs.
Multitask Mastery🧠: Large-scale multitask instruction tuning enhances its capabilities across various image and text generation tasks.
Structure-Guided Editing🎨: CM3leon understands and interprets structural information for visually coherent and contextually appropriate image edits.
Super-Resolution🌟: With an additional super-resolution stage, CM3leon can produce higher-resolution images from its original outputs.
More information on CM3leon
Launched
1991-01
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
1.6M
Top 5 Countries
24.79%
8.23%
4.75%
3.87%
3.53%
United States (24.79%)
India (8.23%)
China (4.75%)
Germany (3.87%)
France (3.53%)
Traffic Sources
38.37%
46.99%
3.18%
10.67%
mail (0.06%)
direct (38.37%)
search (46.99%)
social (3.18%)
referrals (10.67%)
paidReferrals (0.72%)
Source: Similarweb (Jan 3, 2026)
CM3leon was manually vetted by our editorial team and was first featured on 2023-07-18.
CM3leon Alternatives
CM3leon Alternatives-
With a total of 8B parameters, the model surpasses proprietary models such as GPT-4V-1106, Gemini Pro, Qwen-VL-Max and Claude 3 in overall performance.
-

BAGEL: Open-source multimodal AI from ByteDance-Seed. Understands, generates, edits images & text. Powerful, flexible, comparable to GPT-4o. Build advanced AI apps.
-

Cambrian-1 is a family of multimodal LLMs with a vision-centric design.
-

Yi Visual Language (Yi-VL) model is the open-source, multimodal version of the Yi Large Language Model (LLM) series, enabling content comprehension, recognition, and multi-round conversations about images.
-
CogVLM and CogAgent are powerful open-source visual language models that excel in image understanding and multi-turn dialogue.