
Click outside to close
What is CogVLM & CogAgent?
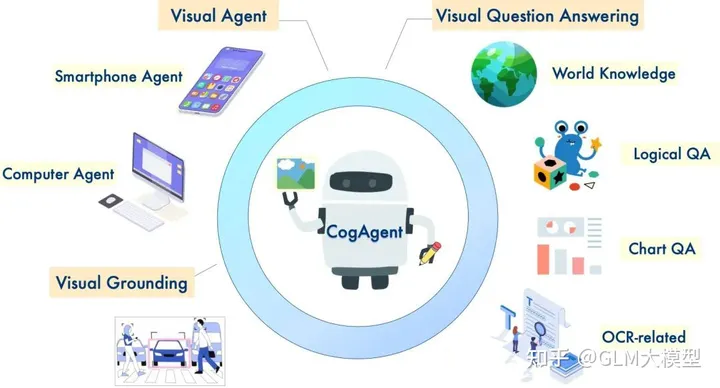
CogVLM and CogAgent are powerful open-source visual language models that excel in image understanding and multi-turn dialogue. CogVLM-17B achieves state-of-the-art performance on various cross-modal benchmarks, showcasing its robust capabilities in image captioning, visual question answering, and grounding tasks. CogAgent-18B, an improved version, further enhances these abilities and introduces GUI Agent functionalities, enabling interactions with high-resolution images and performing tasks on GUI screenshots.
Key Features:
1️⃣ Image Understanding & Dialogue (CogVLM-17B):
🖼️ Handles image understanding and generates detailed descriptions.
💬 Engages in multi-turn dialogues with visual context.
2️⃣ GUI Agent & Enhanced Abilities (CogAgent-18B):
🖥️ Supports high-resolution image inputs (1120x1120) for better visual understanding.
👨💻 Possesses GUI Agent capabilities, performing tasks and answering questions related to GUI screenshots.
📚 Demonstrates improved OCR-related capabilities through specialized training.
3️⃣ Grounding & Multiple Dialogue Modes:
📍 Provides image descriptions with bounding box coordinates for objects.
🔎 Retrieves bounding box coordinates based on object descriptions.
📝 Generates descriptions from specified bounding box coordinates.
Use Cases:
🤖 Natural Language Visual Reasoning:CogVLM and CogAgent excel in tasks that require visual understanding and language generation, such as image captioning, visual question answering, and grounding tasks.
💻 GUI Interaction and Automation:CogAgent's GUI Agent capabilities make it suitable for tasks involving interactions with GUI screenshots, such as web pages, applications, and software.
📚 Question Answering with Visual Context:Both models can answer questions related to images, providing informative responses that leverage their understanding of the visual context.
📝 Language Generation with Visual Input:Given an image, CogVLM and CogAgent can generate detailed descriptions, stories, or dialogue that are coherent with the visual content.
Conclusion:
CogVLM and CogAgent are versatile visual language models that combine image understanding, multi-turn dialogue, and GUI Agent functionalities. Their powerful capabilities make them valuable assets for various applications, including natural language-based visual reasoning, GUI interaction and automation, question answering with visual context, and language generation with visual input.
More information on CogVLM & CogAgent
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
CogVLM & CogAgent was manually vetted by our editorial team and was first featured on 2024-01-28.
CogVLM & CogAgent Alternatives
CogVLM & CogAgent Alternatives-

GLM-4.5V: Empower your AI with advanced vision. Generate web code from screenshots, automate GUIs, & analyze documents & video with deep reasoning.
-

GLM-4-9B is the open-source version of the latest generation of pre-trained models in the GLM-4 series launched by Zhipu AI.
-

Qwen2-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud.
-

Yi Visual Language (Yi-VL) model is the open-source, multimodal version of the Yi Large Language Model (LLM) series, enabling content comprehension, recognition, and multi-round conversations about images.
-

The New Paradigm of Development Based on MaaS , Unleashing AI with our universal model service