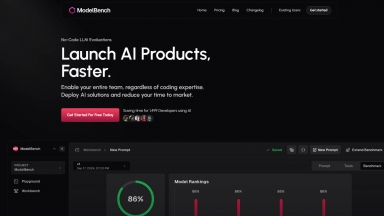
 ModelBench
ModelBench
 Promptbench
Promptbench
ModelBench
| Launched | 2024-05 |
| Pricing Model | Free Trial |
| Starting Price | 49 $ Monthly |
| Tech used | Google Tag Manager,Amazon AWS CloudFront,Google Fonts |
| Tag | A/B Testing,Data Analysis,Data Visualization |
Promptbench
| Launched | 2024 |
| Pricing Model | Free |
| Starting Price | |
| Tech used | |
| Tag | Text Analysis |
ModelBench Rank/Visit
| Global Rank | 7783759 |
| Country | India |
| Month Visit | 1971 |
Top 5 Countries
Traffic Sources
Promptbench Rank/Visit
| Global Rank | |
| Country | |
| Month Visit |
Top 5 Countries
Traffic Sources
Estimated traffic data from Similarweb
What are some alternatives?
PromptTools - PromptTools is an open-source platform that helps developers build, monitor, and improve LLM applications through experimentation, evaluation, and feedback.
BenchLLM by V7 - BenchLLM: Evaluate LLM responses, build test suites, automate evaluations. Enhance AI-driven systems with comprehensive performance assessments.
AI2 WildBench Leaderboard - WildBench is an advanced benchmarking tool that evaluates LLMs on a diverse set of real-world tasks. It's essential for those looking to enhance AI performance and understand model limitations in practical scenarios.
Prompt Builder - PromptBuilder delivers expert-level LLM results consistently. Optimize prompts for ChatGPT, Claude & Gemini in seconds.