
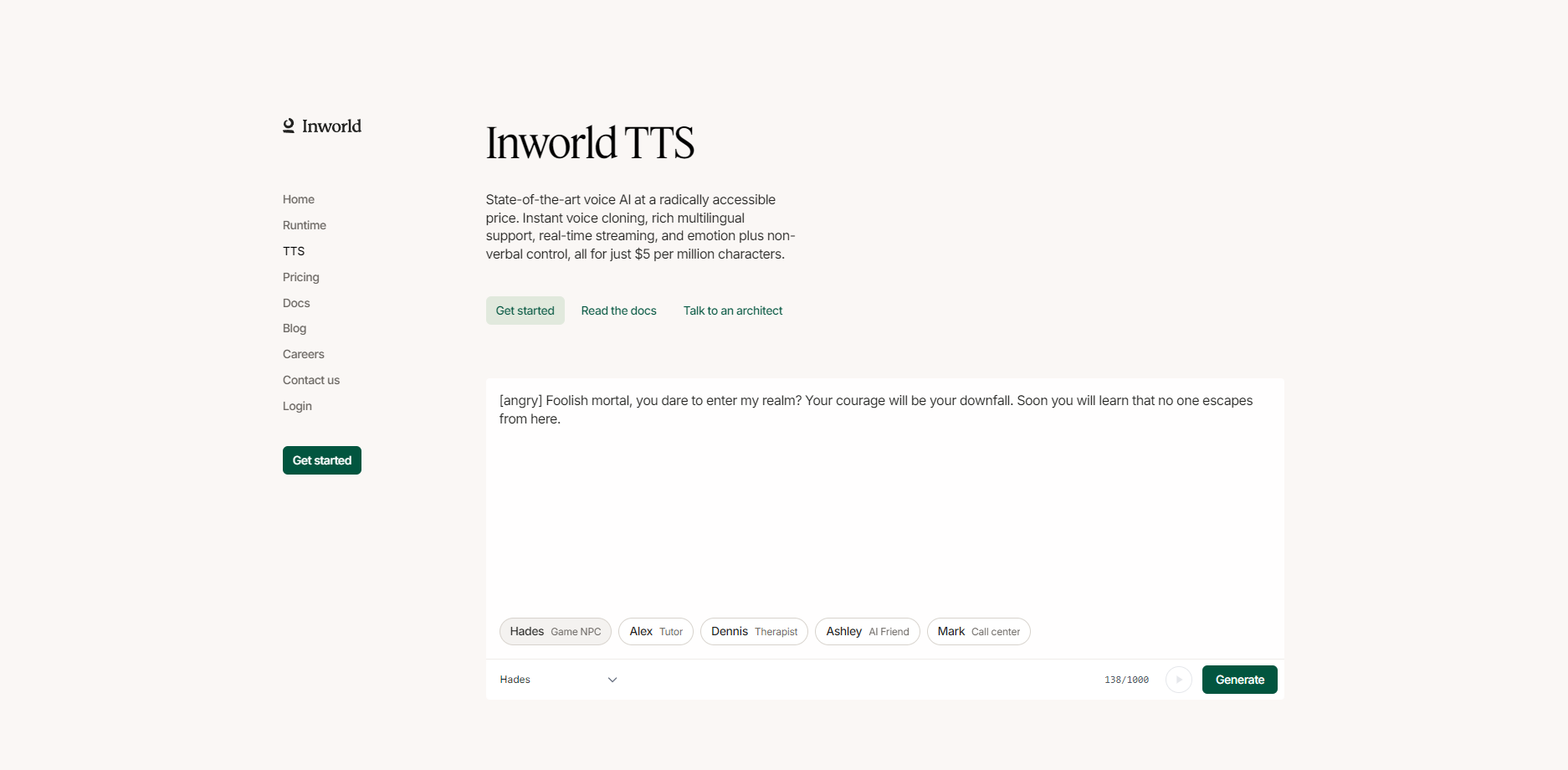
What is Inworld TTS?
Los modelos de Text-to-Speech (TTS) de Inworld ofrecen a los desarrolladores una síntesis de voz ultrarrealista y consciente del contexto, junto con capacidades precisas de clonación de voz, lo que les permite crear experiencias digitales verdaderamente naturales y atractivas. Diseñado específicamente para la interacción en tiempo real, este sistema aborda la necesidad crítica de una latencia inferior a un segundo y una salida de voz profundamente expresiva y de apariencia humana en entornos dinámicos como los videojuegos, los agentes virtuales y el servicio al cliente.
Características Clave
Inworld TTS está diseñado para ofrecer una voz de alta fidelidad con el control y la velocidad requeridos para las aplicaciones interactivas más exigentes, todo ello manteniendo precios sumamente accesibles.
- 🎙️ Marcadores de Audio Orientados a la Interpretación: Vaya más allá de la lectura de texto convencional. Inworld TTS le permite insertar marcadores de audio directamente en el texto para controlar con precisión la emoción del habla (p. ej., ira, alegría, calma), el estilo de entonación (p. ej., susurro, dramático) y los sonidos no verbales (p. ej., risas, suspiros, respiración). Esta es una de las pocas soluciones que permite el control simultáneo sobre la semántica, la emoción y el estilo de interpretación.
- ⏱️ Transmisión en Tiempo Real Inferior a un Segundo: Optimizado para conversaciones en vivo, el sistema aprovecha la tecnología WebSocket para una transmisión continua y de baja latencia. A diferencia de las solicitudes HTTP estándar, esta conexión persistente admite diálogos instantáneos, actualizaciones de parámetros a mitad de frase y la detección crítica de interrupciones del usuario (barge-in) para interacciones fluidas con agentes de IA.
- 🔗 Alineación de Marcas de Tiempo para Sincronización Visual: Genera una salida de audio con marcas de tiempo
que alinea con precisión la palabra hablada con el milisegundo. Esta característica es esencial para los desarrolladores que crean personajes virtuales de alta fidelidad, permitiendo una sincronización labial perfecta, la animación de subtítulos palabra por palabra o el desencadenamiento de eventos en el juego basados en señales de voz específicas. - 🗣️ Clonación de Voz Instantánea y Profesional: Cree rápidamente voces personalizadas con un esfuerzo mínimo. La Clonación Instantánea (Zero-Shot) requiere solo de 2 a 15 segundos de audio y está disponible a través de API para una implementación rápida. Para una consistencia de marca de alta fidelidad, la Clonación Profesional (Fine-Tuned) utiliza aprendizaje profundo para replicar las características de la voz para ídolos virtuales, embajadores de marca o protagonistas de videojuegos.
- 🌍 Soporte Translingüe y Multilingüe: Compatibilidad con 12 idiomas principales, todos ellos diseñados para una fluidez similar a la de un hablante nativo. De manera crucial, Inworld es compatible con la migración de voz translingüe, lo que permite que una única voz clonada transicione de manera fluida y natural entre idiomas, como el inglés y el chino, manteniendo la identidad única del personaje a nivel global.
Casos de Uso
Inworld TTS le permite resolver desafíos complejos de diálogo en diversos sectores, asegurando que sus personajes digitales suenen auténticos y respondan de manera adecuada.
1. Diálogo Dinámico de PNJ en Videojuegos
Los desarrolladores pueden utilizar la transmisión en tiempo real y la alineación de marcas de tiempo para crear personajes no jugables (PNJ) verdaderamente interrumpibles y emocionalmente receptivos. Si un jugador interrumpe a un PNJ a mitad de frase, el sistema puede detectar
2. Agentes Globales de Servicio al Cliente con IA
Despliegue agentes de IA sofisticados
3. Branding Vocal de Precisión y E-Learning
Para aplicaciones que requieren una
¿Por Qué Elegir Inworld TTS?
Elegir Inworld significa priorizar la calidad verificada, el control granular y la eficiencia en su proceso de voz. Nuestro enfoque en la interactividad en tiempo real y la habilitación de desarrolladores nos distingue.
- Calidad Verificada y Líder en la Industria: Los modelos de Inworld han demostrado un rendimiento superior en métricas clave como la Tasa de Error de Palabras (WER) y la Similitud del Hablante (SIM), logrando el puesto número 1 en el Hugging Face TTS Arena. Nuestro modelo Inworld TTS Max también ocupó el primer lugar en la tabla de clasificación de Text-to-Speech de Artificial Analysis, confirmando una calidad de audio más fluida, natural y emocionalmente coherente.
- Control de Interpretación Único: Proporcionamos las herramientas necesarias para el desarrollo de personajes complejos. Características como los marcadores de audio para sonidos no verbales y las acotaciones escénicas son cruciales para proporcionar profundidad narrativa, permitiendo a los personajes suspirar, reír o hablar de forma dramática, elevando significativamente la calidad expresiva del habla sintética.
- Integración Centrada en el Desarrollador: Ofrecemos opciones de integración robustas, que incluyen una Guía de Inicio Rápido de la API, ejemplos de código de GitHub listos para usar y una integración perfecta con frameworks de proxy de voz líderes como LiveKit y Vapi, acelerando su tiempo de implementación.
Conclusión
Inworld TTS ofrece una base potente y flexible para construir la próxima generación de experiencias digitales interactivas. Al fusionar una calidad de voz de vanguardia con controles esenciales en tiempo real, como la latencia inferior a un segundo y la alineación de marcas de tiempo, usted obtiene la capacidad de crear personajes digitales
Descubra cómo Inworld TTS puede transformar sus proyectos interactivos hoy mismo probando el TTS Playground o revisando la guía Developer Quickstart.
More information on Inworld TTS
Top 5 Countries
26.51%
5.76%
3.38%
3.02%
2.97%
United States
Spain
Brazil
United Kingdom
Germany
Traffic Sources
3.75%
0.8%
0.07%
8.35%
51.26%
35.76%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Inworld TTS was manually vetted by our editorial team and was first featured on 2023-08-27.
Inworld TTS Alternativas
Más Alternativas-

-

-

Kyutai TTS ofrece texto a voz ultrarrápido y de baja latencia. Transmite el audio al instante a medida que se genera el texto, lo que resulta ideal para aplicaciones de voz en tiempo real e IA. Alta fidelidad.
-

-

Transforma tus podcasts y chatbots con FireRedTTS-2: discurso natural, multilocutor y de larga duración. Disfruta de latencia ultrabaja y clonación de voz multilingüe.