
What is Inworld TTS?
InworldのText-to-Speech(TTS)モデルは、開発者に超リアルで文脈を理解した音声合成と高精度な音声クローン
主な機能
Inworld TTSは、最も要求の厳しいインタラクティブアプリケーションに必要な制御と速度を備えながら、高忠実度の音声を提供できるよう設計されており、それでいて極めて手頃な価格設定を実現しています。
- 🎙️ パフォーマンス駆動型オーディオマークアップ:単なるテキスト読み上げを超越します。Inworld TTSでは、テキスト内に直接オーディオマークアップを挿入することで、発話の感情(例:怒り、喜び、落ち着き)、表現スタイル(例:ささやき、ドラマチック)、非言語音(例:笑い声、ため息、呼吸)を精密に制御できます。これは、意味、感情、パフォーマンススタイルを同時に制御できる数少ないソリューションの一つです。
- ⏱️ サブ秒単位のリアルタイムストリーミング:ライブ会話に最適化されたこのシステムは、WebSocket技術を活用し、継続的かつ低遅延のストリーミングを実現します。標準的なHTTPリクエストとは異なり、この永続的な接続により、瞬時の対話、会話途中でのパラメーター更新、そしてシームレスなAIエージェントインタラクションのために不可欠なユーザー割り込み検出(バージイン)をサポートします。
- 🔗 視覚同期のためのタイムスタンプアラインメント:発話された単語をミリ秒単位で正確に同期させるタイムスタンプ付き音声出力を生成します。この機能は、高忠実度なバーチャルキャラクターを作成する開発者にとって不可欠であり、完璧なリップシンク、単語ごとの字幕アニメーション、特定の音声キューに基づくゲーム内イベントのトリガーを可能にします。
- 🗣️ 即時かつプロフェッショナルな音声クローン:最小限の労力でカスタムボイスを素早く作成できます。インスタント(ゼロショット)クローンは、わずか2~15秒の音声で作成可能で、API経由で迅速に展開できます。高忠実度なブランドの一貫性を保つため、プロフェッショナル(ファインチューニング)クローンはディープラーニングを活用し、バーチャルアイドル、ブランドアンバサダー、ゲームの主人公の音声特性を忠実に再現します。
- 🌍 クロスリンガル&多言語対応:12の主要言語に対応しており、いずれもネイティブスピーカーレベルの流暢さを実現するように設計されています。決定的なのは、Inworldがクロスリンガル音声マイグレーションをサポートしていることです。これにより、クローンされた単一の音声が、英語と中国語などの言語間で滑らかかつ自然に移行し、キャラクター独自のアイデンティティを世界中で維持できます。
ユースケース
Inworld TTSは、様々な分野における複雑な対話の課題を解決し、デジタルキャラクターが本物らしく、応答性に富んだ音声を発することを保証します。
1. ゲームにおける動的なNPC対話
開発者は、リアルタイムストリーミングとタイムスタンプアラインメントを活用して、本当に割り込み可能で感情豊かな非プレイヤーキャラクター(NPC)を作成できます。プレイヤーがNPCの発話途中で割り込んでも、システムは
2. グローバルAIカスタマーサービスエージェント
複数の地域と言語にわたり、単一で一貫したブランドボイスを活用できる高度なAIエージェントをデプロイします。多言語
3. 精密な音声ブランディングとeラーニング
絶対的な発音
Inworld TTSを選ぶ理由
Inworldを選ぶことは、音声パイプラインにおける実証済みの品質、きめ細やかな制御、そして効率性を優先することを意味します。リアルタイムインタラクティビティと開発者支援への注力が、当社の特徴です。
- 実証された業界トップの品質:Inworldのモデルは、単語誤り率(WER)や話者類似度(SIM)などの主要な指標において優れたパフォーマンスを発揮し、Hugging Face TTS Arenaで1位を獲得しました。また、当社のInworld TTS Maxモデルは、Artificial Analysisのテキスト読み上げ
リーダーボード でも1位となり、より滑らかで自然、かつ感情的に一貫したオーディオ品質が確認されています。 - 独自のパフォーマンス制御:複雑なキャラクター開発に必要なツールを提供します。非言語音や舞台指示のためのオーディオマークアップなどの機能は、物語の深みを表現するために不可欠です。キャラクターがため息をついたり、笑ったり、ドラマチックに話したりすることを可能にし、合成音声の表現力を大幅に向上させます。
- 開発者中心の統合:ガイド付きAPIクイックスタート、すぐに使えるGitHubコード例、LiveKitやVapiといった主要な音声プロキシフレームワークとのシームレスな統合など、堅牢な統合オプションを提供し、展開までの時間を短縮します。
結論
Inworld TTSは、次世代のインタラクティブなデジタル体験を構築するための強力で柔軟な基盤を提供します。最先端の音声品質と、サブ秒単位の低遅延やタイムスタンプアラインメントといった不可欠なリアルタイム制御を融合させることで、本物のように聞こえ、反応し、振る舞うデジタルキャラクターを生み出す
TTS Playgroundを試すか、Developer Quickstartガイドを参照して、Inworld TTSがどのように今日のインタラクティブプロジェクトを変革できるかをご覧ください。
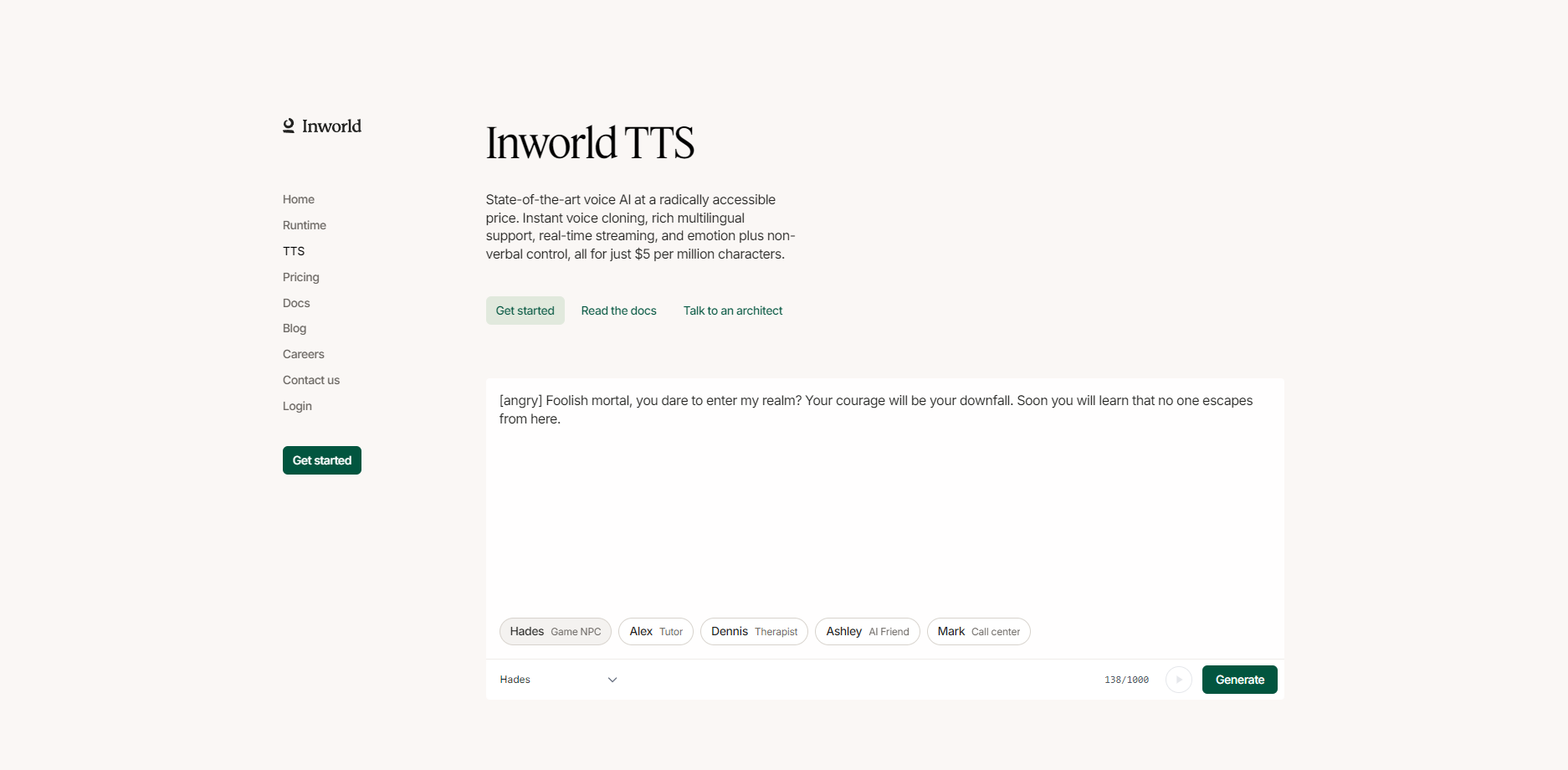
More information on Inworld TTS
Top 5 Countries
26.51%
5.76%
3.38%
3.02%
2.97%
United States
Spain
Brazil
United Kingdom
Germany
Traffic Sources
3.75%
0.8%
0.07%
8.35%
51.26%
35.76%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Inworld TTS was manually vetted by our editorial team and was first featured on 2023-08-27.
Inworld TTS 代替ソフト
もっと見る 代替ソフト-

-

-

Kyutai TTSは、超高速かつ低遅延の音声合成を実現します。テキスト生成と同時に音声を瞬時にストリーミングし、リアルタイム音声アプリやAIでの活用を可能にします。高音質。
-

-

FireRedTTS-2で、ポッドキャストやチャットボットを飛躍的に進化させましょう。自然で多人数に対応した長尺音声を提供し、超低遅延と多言語音声クローニングも実現します。