What is Hugging Face?
Hugging Face is a machine learning (ML) and data science platform that allows users to build, deploy, and train ML models. It serves as a community where developers can share and test their work openly. The platform is known for its Transformers Python library, which simplifies the process of downloading and training ML models. Hugging Face provides infrastructure for running and deploying AI in live applications, and users can browse through models and data sets uploaded by others. The platform is open source and offers deployment tools, reducing model training time, resource consumption, and environmental impact.
Key Features:
1. Implement machine learning models: Users can upload ML models to the platform, including models for natural language processing, computer vision, image generation, and audio. Hugging Face's Transformers library simplifies the process of including ML models in workflows and creating ML pipelines.
2. Share and discover models and data sets: Researchers and developers can share their models and data sets with the community. Other users can download these models and use them in their own applications. Hugging Face's Datasets library allows users to discover and access data sets for training ML models.
3. Fine-tune and train models: Hugging Face provides tools for fine-tuning and training deep learning models through its application programming interface (API). Users can customize and optimize models according to their specific needs.
Use Cases:
- Research and development: Hugging Face supports collaborative research projects and provides a curated list of research papers. Researchers can access models, data sets, and evaluation tools to advance the field of natural language processing (NLP) and machine learning.
- Business applications: Hugging Face's Enterprise Hub enables business users to work with transformers, data sets, and open-source libraries in a privately hosted environment. This allows for the development of custom ML applications tailored to specific business needs.
- Model evaluation: Hugging Face provides access to a code library for evaluating ML models and data sets. Users can assess the performance and effectiveness of their models using these evaluation tools.
Conclusion:
Hugging Face is a machine learning platform and community that simplifies the process of building, deploying, and training ML models. It offers a wide range of features, including model implementation, sharing and discovery of models and data sets, fine-tuning and training capabilities, and hosting interactive demos. The platform's open-source nature and deployment tools make it accessible and cost-effective for users. With its collaborative approach to AI development, Hugging Face aims to democratize AI access and empower developers to create their own AI models.



More information on Hugging Face
Launched
2023
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Amazon AWS CloudFront,cdnjs,Google Fonts,KaTeX,RSS,Stripe
Hugging Face was manually vetted by our editorial team and was first featured on 2023-03-07.
Related Searches
Hugging Face Alternatives
Load more Alternatives-
The course teaches you about applying Transformers to various tasks in natural language processing and beyond.
-

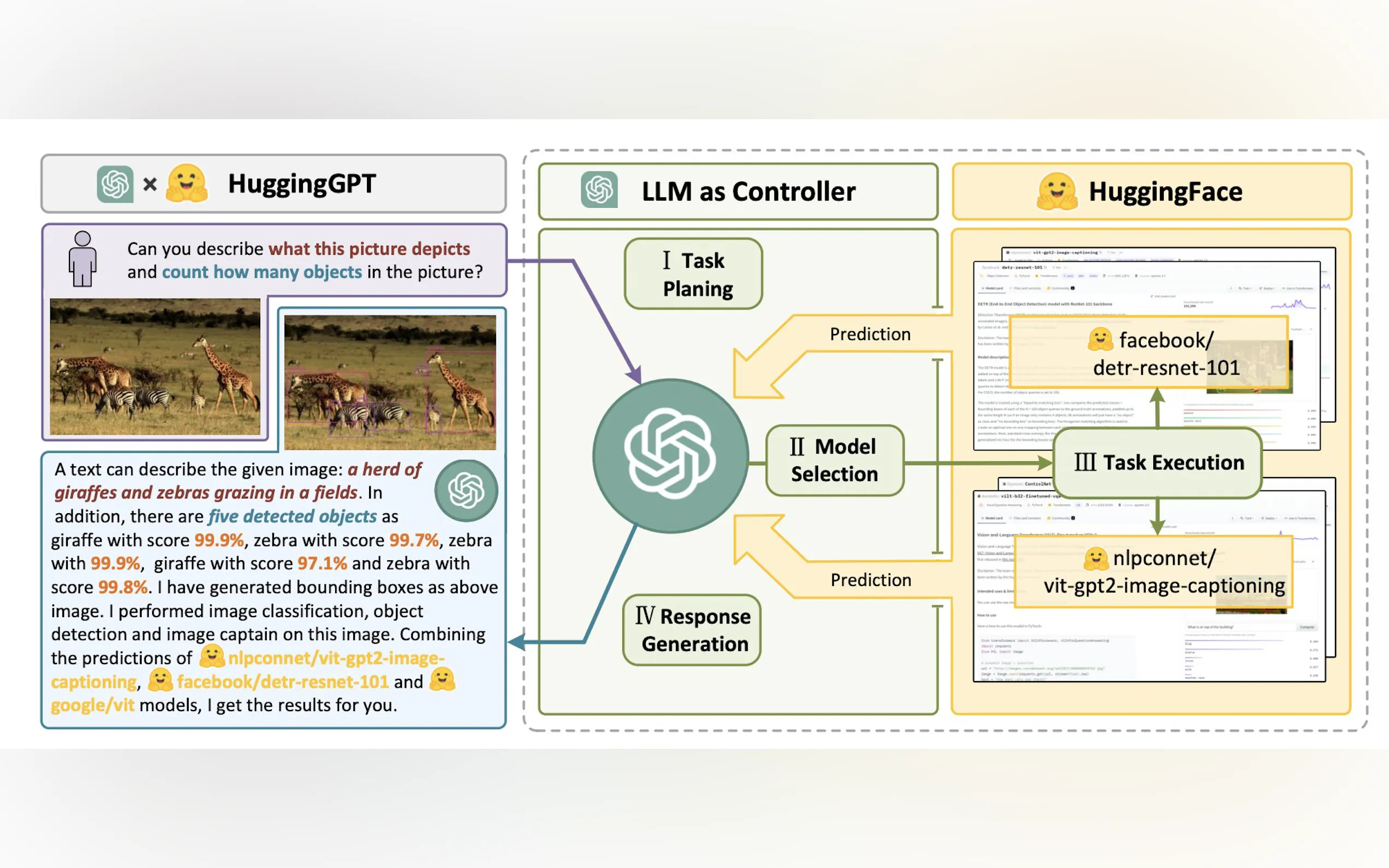
Hugging Face Transformer Agents: An experimental library with support for open-source & proprietary models, extensive default tools and customizable features for building AI-powered apps, integrating smoothly with HF models & datasets.
-
Explore HuggingChat, the open-source AI chatbot that lets you contribute and enhance its source code. Experiment with AI capabilities today!
-

-