What is Reverb?
Reverbは、Revが開発した最先端のオープンソース音声認識(ASR)とダイアライゼーションモデルを導入しています。WeNetとPyannoteフレームワークを活用することで、Reverb ASRは長尺音声認識に優れ、Reverb Diarizationは話者の交代を正確に特定します。これらのモデルは、人間が書き起こした英語音声データセットでトレーニングされ、精度と効率の両方に最適化されており、転写から音声テクノロジー研究まで、さまざまな用途に適しています。
主な機能:
? 高精度ASR- 精度の高い音声テキスト変換のために、CTC/アテンションアーキテクチャを備えたWeNetを使用しています。
?️ 話者ダイアライゼーション- Pyannoteに基づいて、異なる話者による音声の識別とセグメント化を効果的に行います。
?️ 逐語性の制御- 完全な逐語から非逐語まで、さまざまなニーズに対応する、調整可能な転写出力を提供します。
? 速度とメモリ効率- 少ないリソース使用で高速推論を実現する、Int8量子化ASRモデル。
? フルプロダクションパイプライン- 開発者向けに、ASRとダイアライゼーション、フォーマット化された出力、後処理を含む完全なシステム。
ユースケース:
?️ ポッドキャストの転写- 高精度で話者を特定しながら、ポッドキャストを自動的に転写し、セグメント化します。
? 会議議事録- 各話者を特定しながら、ビジネス会議から詳細で読みやすい議事録を作成します。
? ビデオキャプション- 話し言葉と話者に合わせた正確なキャプションを作成し、アクセシビリティを向上させます。
結論:
Reverbは、オープンソース音声テクノロジーのベンチマークを再定義し、ASRとダイアライゼーションにおいて比類のない精度を実現しています。その汎用性により、高度な音声認識機能をプロジェクトに組み込みたい開発者や研究者にとって理想的な選択肢となっています。転写の逐語性を微調整できることや、長尺音声に対する優れたパフォーマンスにより、Reverbは音声認識イノベーションのリーダーとして際立っています。
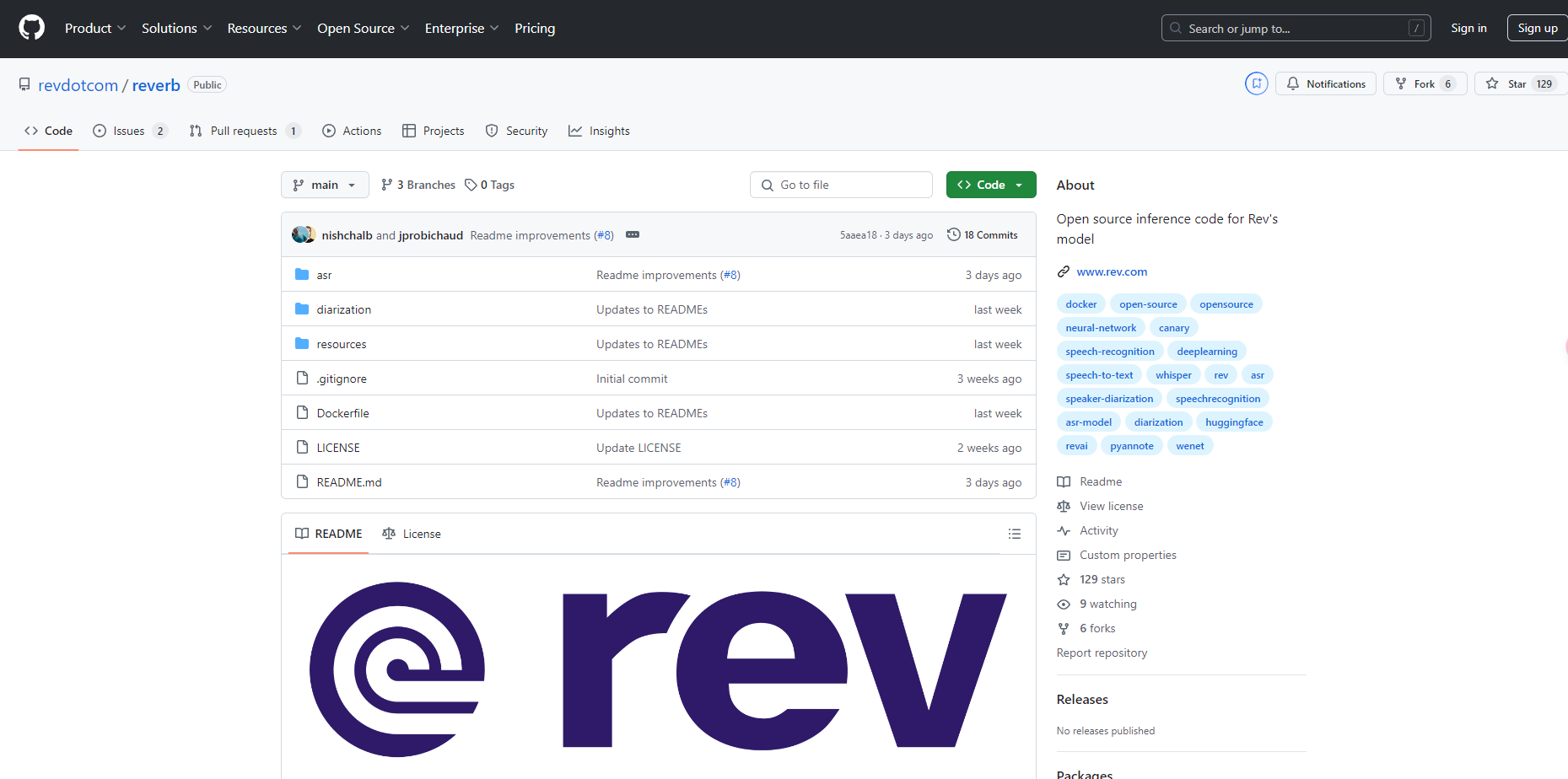
More information on Reverb
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Reverb was manually vetted by our editorial team and was first featured on 2024-10-07.
Related Searches