What is Reverb?
Reverb 採用 Rev 開發的尖端開源語音辨識 (ASR) 和對話者辨識模型套件。利用 WeNet 和 Pyannote 架構,Reverb ASR 在長篇語音辨識方面表現出色,而 Reverb 對話者辨識則能準確地找出說話者變換。這些模型在最大的英文人聲轉錄語料庫上進行訓練,並針對準確性和效率進行優化,適用於從轉錄到語音技術研究的各種應用。
主要特點:
? 高準確度 ASR- 使用具有聯合 CTC/注意力的 WeNet 架構,實現精準的語音轉文字。
?️ 說話者對話者辨識- 基於 Pyannote,有效識別和分割不同說話者的語音。
?️ 逐字稿控制- 提供可調整的轉錄輸出,從完全逐字稿到非逐字稿,滿足不同的需求。
? 速度和記憶體效率- Int8 量化的 ASR 模型,可實現快速推論,同時最大程度地減少資源使用。
? 完整的生產管道- 完整的開發人員系統,包括 ASR 和對話者辨識、格式化輸出和後處理。
用例:
?️ Podcast 轉錄- 自動轉錄和分割 Podcast,具有高準確度和說話者歸屬。
? 會議記錄- 從商務會議中生成詳細且可讀的逐字稿,識別每個說話者。
? 影片字幕- 建立與口語和說話者相符的準確字幕,提高可訪問性。
結論:
Reverb 重塑了開源語音技術的基準,在 ASR 和對話者辨識方面提供了無與倫比的準確性。其多功能性使其成為開發人員和研究人員的理想選擇,他們希望將先進的語音辨識功能整合到他們的專案中。憑藉調整逐字稿的逐字稿能力和對長篇音訊的卓越效能,Reverb 成為語音辨識創新的領導者。
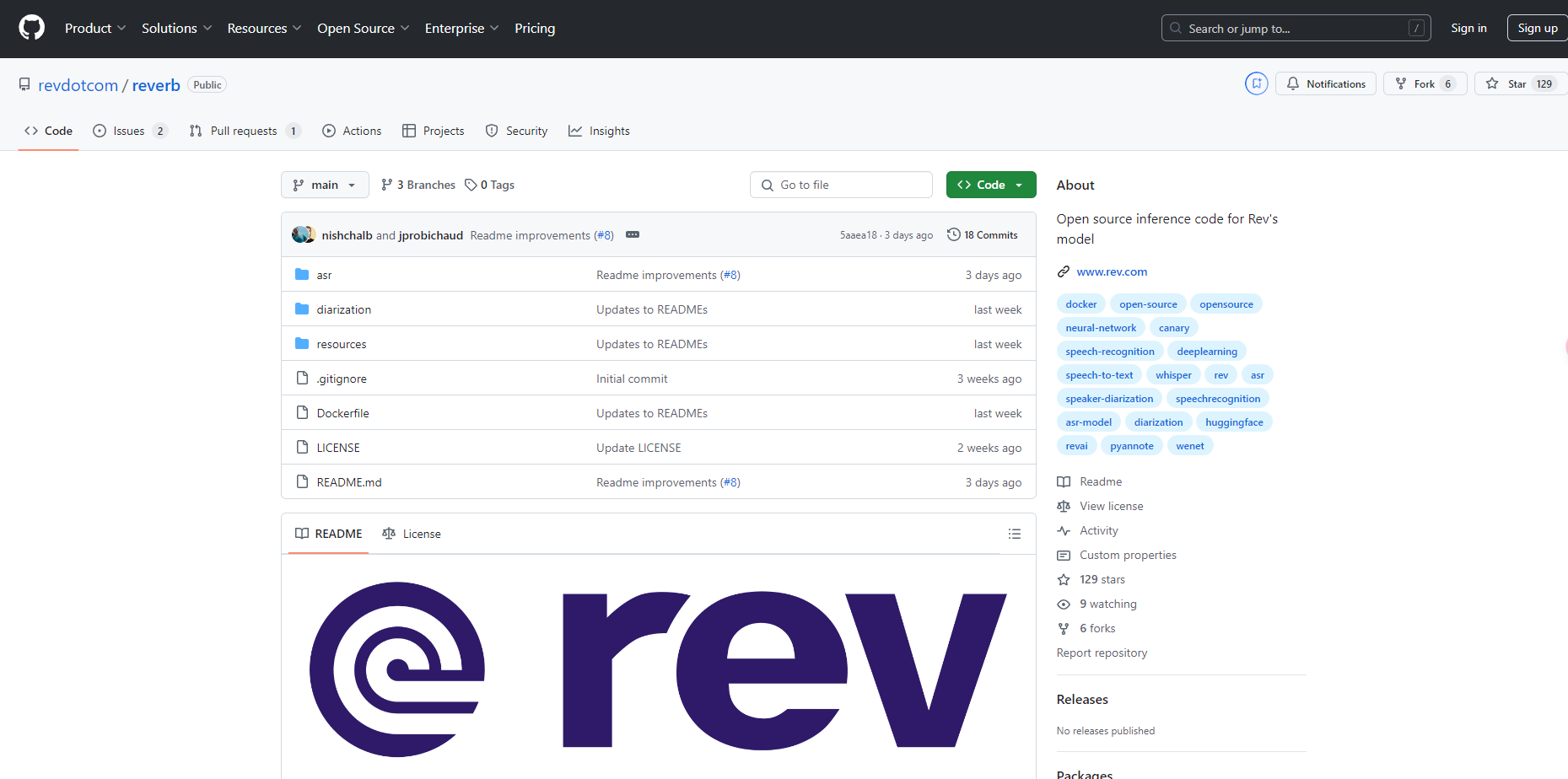
More information on Reverb
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Reverb was manually vetted by our editorial team and was first featured on 2024-10-07.
Related Searches