What is VibeVoice?
VibeVoiceは、テキストを表現豊かなマルチスピーカーの対話型オーディオに変換するために設計された、洗練されたフレームワークです。従来のText-to-Speech (TTS) の核となる制限に直接対処し、ポッドキャストやオーディオドラマのような長尺コンテンツを、一貫した話者アイデンティティと自然な対話の流れで生成することを可能にします。
主な機能
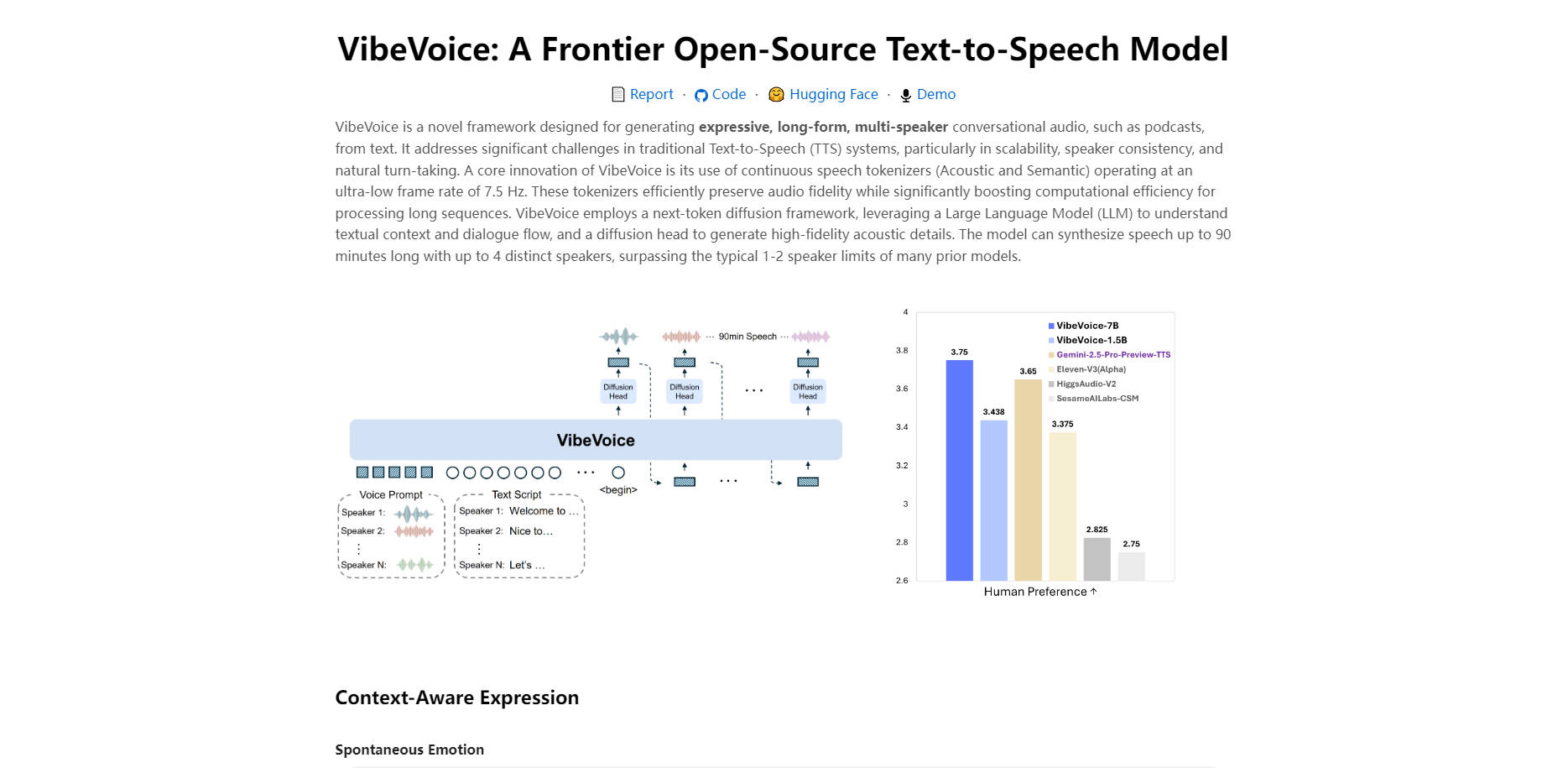
🎙️ 長尺のマルチスピーカー対話を生成 1回のセッションで最大4人の異なる話者による最大90分の連続オーディオを生成できます。この機能は、単なるナレーションを超え、複雑な対話、インタビュー、パネルディスカッションなどを簡単に作成することを可能にします。
🎭 表現豊かで忠実度の高い音声を生成 VibeVoiceはテキストの文脈を分析し、自然な感情と抑揚を持った音声を生成します。高度なボコーダーを活用することで、生成されるオーディオは非常に明瞭で、人間の会話のニュアンスを忠実に再現し、優れたリスニング体験を提供します。
⚙️ 一貫した話者アイデンティティを保持 専用のスピーカー埋め込みを活用することで、VibeVoiceは、オーディオの長さに関わらず、各話者の声が明確かつ一貫して保たれることを保証します。これにより、長尺オーディオ生成で発生しがちな、時間の経過とともに声が変化したり、独自の特徴が失われたりするという一般的な問題を解決します。
🌍 クロス言語対応 同じ会話内でも、複数の言語で音声をシームレスに合成できます。これにより、VibeVoiceは多言語コンテンツ、語学学習教材、そしてグローバルにアクセス可能なオーディオ制作のための強力なツールとなります。
ユースケース
ポッドキャストおよびオーディオドラマ制作: 個人のクリエイターでも、複数の共同ホストが登場するフルボイスのポッドキャストや、全登場人物が登場するオーディオドラマを制作できるようになります。スクリプトを書き、声を割り当てるだけで、VibeVoiceが制作準備完了の完全なオーディオファイルを生成します。
アクセシブルなコンテンツ作成: 長尺の記事、研究論文、または書籍全体を、魅力的なマルチスピーカーのオーディオブックに変換します。これにより、コンテンツのアクセシビリティが向上するだけでなく、単一のナレーターによる朗読よりも、よりダイナミックなリスニング体験を提供します。
インタラクティブ音声アプリケーションの開発: VibeVoiceを統合することで、アプリケーション内でダイナミックなリアルタイム会話を実現します。ゲーム内でよりリアルなNPCs (ノンプレイヤーキャラクター) を作成したり、複雑な多段階の対話に対応できる、より洗練された文脈認識型バーチャルアシスタントを構築したりできます。
VibeVoiceを選ぶ理由
VibeVoiceは単なる別のTTSシステムではありません。その基盤となるアーキテクチャは、長尺の対話型オーディオにおける課題を克服するために特別に設計されています。
比類ない効率性と忠実度: その核となる革新は、超低フレームレートの7.5 Hzで動作する連続音声トークナイザーの使用です。この独自のアプローチにより、長尺オーディオシーケンスに必要な計算負荷を大幅に削減しつつ、オーディオ品質を犠牲にしません。これは、他の多くのモデルを制限する忠実度とパフォーマンス間の古典的なトレードオフを解決します。
深い文脈理解: VibeVoiceは、Large Language Model (LLM) を活用して、対話の流れと文脈を理解します。これは、単に言葉を読むだけでなく、会話の構造を把握し、スクリプトに基づいて自然なターン交代と適切な感情表現を可能にするということです。
設計によるスケーラビリティ: このフレームワークは、長時間の会話を処理するためにゼロから構築されています。他のシステムが数分を超えると一貫性やパフォーマンスに苦労する可能性があるのに対し、VibeVoiceは最大90分のコンテンツに対して信頼性の高い、高品質な結果を提供できるよう最適化されています。
結論
VibeVoiceは、これまで制作が複雑でリソースを多大に必要としていた、洗練された長尺の対話型オーディオを生成するための強力なツールを、クリエイター、開発者、そしてコミュニケーションを担う人々に提供します。これにより、魅力的なポッドキャスト、アクセシブルなメディア、そしてインタラクティブな体験を創造するための新たな可能性が開かれます。
VibeVoiceがあなたのオーディオプロジェクトをどのように向上させるか、ぜひお試しください!
More information on VibeVoice
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
VibeVoice was manually vetted by our editorial team and was first featured on 2025-08-26.
Related Searches