What is VibeVoice?
VibeVoice 是一个先进的框架,旨在将您的文本转化为富有表现力的多说话者对话音频。它直接解决了传统文本转语音(TTS)的核心局限,使您能够生成播客和有声剧等长篇内容,同时保持一致的说话者身份和自然的对话流程。
主要功能
🎙️ 创建长篇多说话者对话 在单次会话中,VibeVoice 可生成长达90分钟的连续音频,支持多达四位不同的说话者。这项能力超越了简单的旁白叙述,让您轻松制作复杂的对话、访谈和圆桌讨论。
🎭 实现富有表现力的高保真语音 VibeVoice 分析文本上下文,生成带有自然情感和语调的语音。借助先进的声码器,生成的音频异常清晰,紧密模仿人类对话的细微差别,提供卓越的听觉体验。
⚙️ 确保说话者身份一致性 VibeVoice 利用专属的说话者嵌入技术,确保每个说话者的声音在整个音频中(无论多长)都保持独特和一致。这解决了长篇音频生成中一个常见问题,即声音可能随时间推移而漂移或失去其独特特征。
🌍 利用跨语言支持 即使在同一对话中,也能无缝合成多语言语音。这使得 VibeVoice 成为创建多语言内容、语言学习材料以及全球可访问音频制作的强大工具。
应用场景
播客和有声剧制作: 作为一名独立创作者,您现在可以制作一个拥有多位联合主持人或拥有完整角色阵容的有声剧。只需编写剧本,分配声音,然后让 VibeVoice 生成完整的、可用于制作的音频文件。
无障碍内容创作: 将长篇文章、研究论文或整本书转化为引人入胜的多说话者有声读物。这不仅使您的内容更易于访问,而且比单一旁白朗读提供更具活力的听觉体验。
开发交互式语音应用: 集成 VibeVoice,为您的应用程序提供动态的实时对话能力。在游戏中创建更逼真的 NPCs(非玩家角色),或构建更复杂的、上下文感知的虚拟助手,能够处理复杂的、多轮对话。
为何选择 VibeVoice?
VibeVoice 不仅仅是另一个 TTS 系统;其底层架构经过专门设计,旨在克服长篇对话音频的挑战。
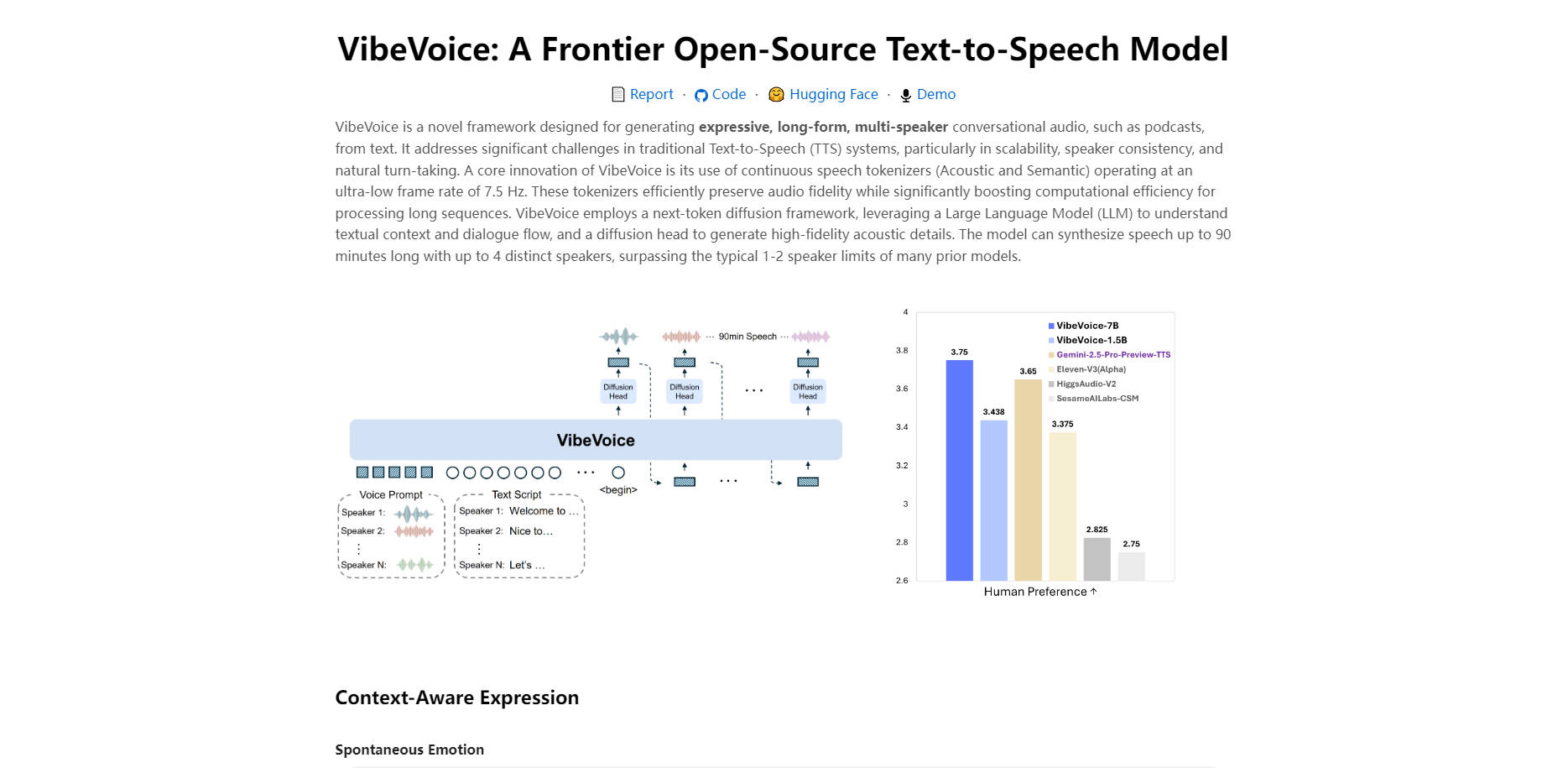
前所未有的效率和保真度: 其核心创新之处在于采用了以超低 7.5 Hz 帧率运行的连续语音分词器。这种独特方法显著降低了长音频序列所需的计算负荷,同时不牺牲音频质量。它解决了许多其他模型在保真度和性能之间存在的经典权衡问题。
深度上下文理解: VibeVoice 利用 Large Language Model (LLM) 来理解对话的流程和上下文。这意味着它不仅仅是读取单词,而是理解对话结构,从而能够根据剧本实现自然的轮流发言和恰当的情感表达。
可扩展性设计: 该框架从头开始构建,旨在处理长时间对话。其他系统可能在几分钟后难以保持一致性或性能,而 VibeVoice 则经过优化,可为长达90分钟的内容提供可靠、高质量的结果。
总结
VibeVoice 为创作者、开发者和传播者提供了一个强大的工具,用于生成复杂的长篇对话音频,这些内容在过去制作起来既复杂又资源密集。它为创建引人入胜的播客、无障碍媒体和交互式体验开辟了新的可能性。
探索 VibeVoice 如何提升您的音频项目!
More information on VibeVoice
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
VibeVoice was manually vetted by our editorial team and was first featured on 2025-08-26.
Related Searches