What is FireRedTTS-2?
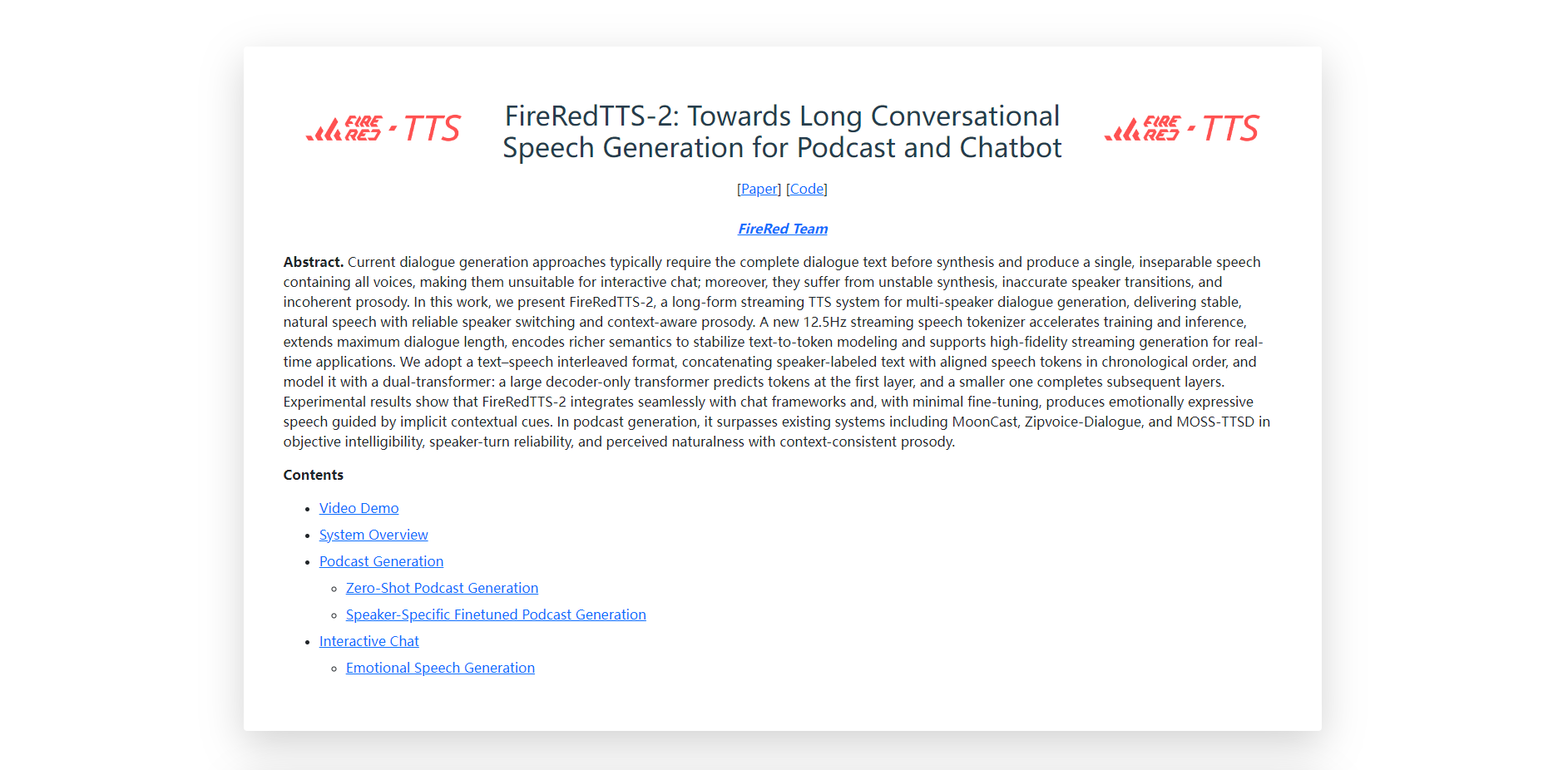
FireRedTTS-2是一款先进的长篇流式文本转语音(TTS)系统,专为动态多说话人对话生成而设计。它解决了在长篇对话中生成自然、稳定且语境感知的语音的挑战,使其成为播客和聊天机器人等需要复杂语音交互应用的理想解决方案。
核心功能
🗣️ 长篇对话语音生成: 可生成最长3分钟、包含4个不同说话人的长篇对话。随着训练数据的不断丰富,可无缝扩展至更长对话及更多参与者。这一能力对于打造丰富、交互式的音频体验至关重要。
🌍 多语言与零样本语音克隆: 支持广泛的语言,包括英语、中文、日语、韩语、法语、德语和俄语。FireRedTTS-2还提供零样本语音克隆功能,无需大量预训练即可在不同语言和语码转换场景中复刻语音。
⚡ 超低延迟流式传输: FireRedTTS-2基于创新的12.5Hz流式语音分词器和双Transformer架构,实现了灵活的逐句生成。这种设计在L20 GPU上实现了低至140毫秒的首包延迟,确保实时应用快速响应,同时保持高音频质量。
✨ 强大稳定性与自然韵律: 该系统能生成稳定、自然悦耳的语音,具备可靠的说话人切换和语境感知的韵律。我们的模型在独白和对话测试中均表现出高相似度以及低词错误率(WER)和字符错误率(CER),确保输出的一致性和高质量。
🎲 随机音色生成: 随机生成多样化的语音音色,这一宝贵功能可用于创建大规模ASR(自动语音识别)或语音交互数据,以增强您的AI模型。
应用场景
动态播客制作: 轻松制作多说话人播客,实现自然的对话流程、清晰的说话人区分,并可为特定角色或主持人克隆语音,大幅节省制作时间和成本。
高级聊天机器人交互: 为下一代聊天机器人提供类人、多说话人对话能力,在复杂或长篇对话场景中,提供更具吸引力、更自然的的用户体验。
AI模型数据生成: 利用随机音色生成和多语言支持,为训练和评估ASR模型、语音合成系统以及其他语音驱动的AI应用生成海量多样化数据集。
为何选择 FireRedTTS-2?
FireRedTTS-2凭借其独特地融合了长篇多说话人对话生成、超低延迟流式传输和强大的多语言支持而脱颖而出。尽管许多TTS系统在单说话人或短篇内容方面表现出色,但FireRedTTS-2专为处理复杂、多方的长篇对话而设计。
无与伦比的对话深度: 与标准TTS解决方案不同,FireRedTTS-2原生支持4个说话人、长达3分钟的对话,为复杂的叙事和交互提供必要的深度。
实时响应能力: 其流式架构和140毫秒的首包延迟确保您的应用程序保持高度响应,这对于聊天机器人等实时交互至关重要,因为延迟会影响用户体验。
借助语音克隆实现全球覆盖: 凭借广泛的语言支持以及在不同语言之间执行零样本语音克隆的独特能力,将您的应用程序推向全球,从而在全球范围内实现一致的品牌形象和个性化体验。
结语
FireRedTTS-2使开发者和内容创作者能够以前所未有的灵活性和低延迟,生成高度自然、多说话人、长篇对话式语音。它是增强用户参与度、拓展语音驱动应用能力的强大解决方案。
探索FireRedTTS-2,革新您创建和交互合成语音的方式。
More information on FireRedTTS-2
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
FireRedTTS-2 was manually vetted by our editorial team and was first featured on 2025-09-12.
Related Searches