What is SuperDuperDB?
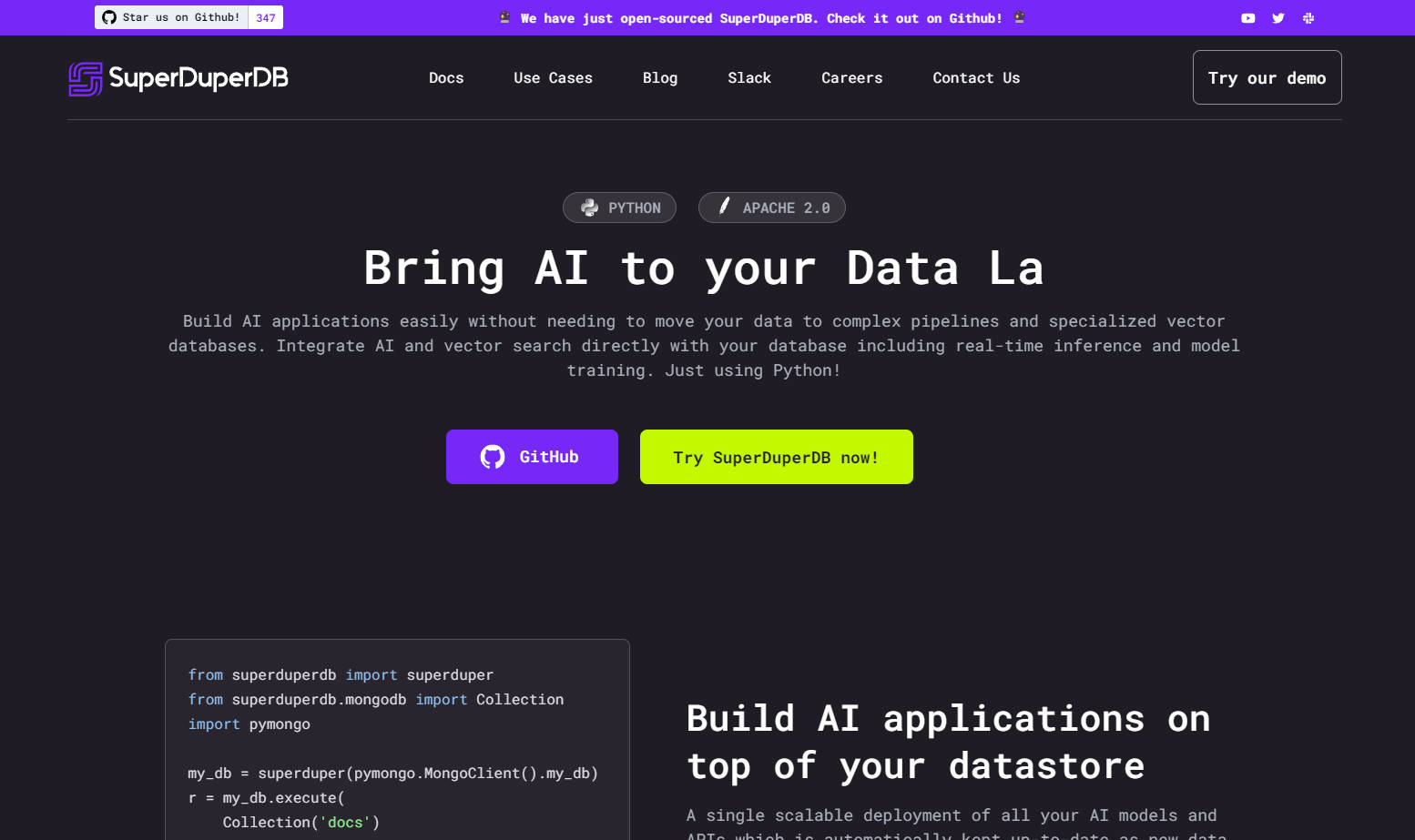
SuperDuperDB 是一款人工智能工具,用户可以轻松构建人工智能应用程序,而无需将数据移动到复杂的管道或专门的向量数据库。它支持人工智能和向量搜索与用户数据库直接集成,包括实时推理和模型训练。该工具基于 Python,提供了一系列功能,用于部署人工智能模型、训练模型、集成 API 和执行向量搜索。
主要功能:
1. 在数据存储之上构建人工智能应用程序:SuperDuperDB 提供所有人工智能模型和 API 的可扩展部署,随着新数据的处理,它们会自动更新。这消除了对其他数据库和数据重复的需求。
2. 将现有数据库变成向量数据库:借助 SuperDuperDB,用户可以在现有数据库中启用向量搜索,而无需引入独立的数据库或重复数据。这简化了在数据库之上构建的过程。
3. 使用任何 ML/AI 框架和 API:SuperDuperDB 允许用户集成和组合来自不同框架的模型,如 Sklearn、PyTorch 和 HuggingFace,以及像 OpenAI 这样的 AI API。这种灵活性支持创建复杂的人工智能应用程序和工作流。
用例:
- 部署人工智能模型:SuperDuperDB 支持将所有人工智能模型部署到用户数据存储中,使用简单的 Python 命令计算输出。这为管理和服务模型提供了一个单一的环境。
- 训练模型:用户可以在数据存储中查询其数据,对模型进行训练,而无需进行其他摄取和预处理。这简化了模型训练过程。
- 集成 AI API:SuperDuperDB 允许无缝集成人工智能 API(例如 OpenAI)和用户数据上的其他模型。这支持在统一的应用程序中组合不同的 AI 功能。
- 执行向量搜索:该工具支持用户数据上的向量搜索,包括模型管理和服务。这简化了从数据库搜索和检索相关信息的过程。
SuperDuperDB 为构建人工智能应用程序提供了一个全面的解决方案,它与现有数据存储轻松集成,支持各种 ML/AI 框架和 API,并提供高效的向量搜索功能。它消除了对复杂的管道和基础设施的需求,使全栈开发人员、数据科学家和机器学习工程师能够获得 AI 开发和部署。凭借简单的 Python 接口和对开发人员体验的关注,SuperDuperDB 简化了人工智能的实现,而无需广泛的 MLOps 知识。

More information on SuperDuperDB
Launched
2022-10-24
Pricing Model
Free
Starting Price
Global Rank
3280763
Country
Australia
Month Visit
15.5K
Tech used
Top 5 Countries
7.62%
6.56%
5.04%
4.73%
4.65%
Turkey
Colombia
Viet Nam
Russian Federation
Taiwan, Province of China
Traffic Sources
68.31%
20.06%
11.63%
Direct
Search
Social
Updated Date: 2024-04-30
SuperDuperDB was manually vetted by our editorial team and was first featured on September 4th 2024.