
What is Cocoindex?
Building powerful AI applications like Retrieval-Augmented Generation (RAG) systems demands high-quality, readily accessible, and consistently up-to-date data. However, constructing and maintaining the necessary data pipelines—extracting from diverse sources, transforming complex information, and indexing it effectively—is often a complex, error-prone, and time-consuming challenge. Keeping this indexed data synchronized with ever-changing sources adds another layer of difficulty.
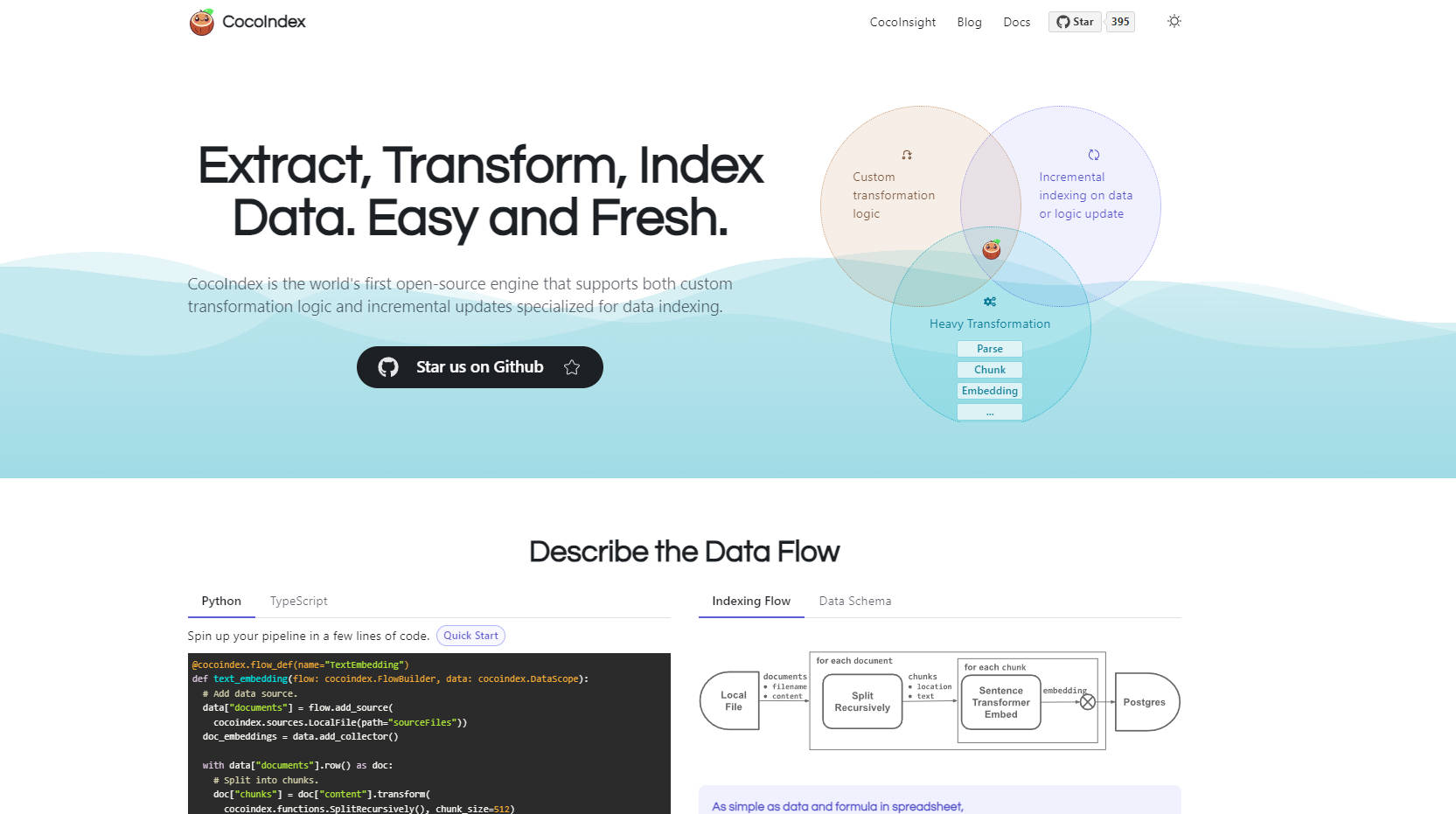
CocoIndex steps in as an open-source framework specifically engineered to simplify this entire process. It provides a robust, declarative approach to defining data indexing pipelines for AI, uniquely combining support for custom transformation logic with real-time incremental updates. Think of it as defining your data flow like a spreadsheet formula – you declare the data sources and transformations, and CocoIndex handles the intricate execution, ensuring your AI applications always work with the freshest possible information.
Key Capabilities:
⚙️ Define Custom ETL Logic: Easily implement your specific data processing needs—parsing various file types (PDFs, HTML, Docs), chunking text using different strategies, generating embeddings with your chosen models, extracting knowledge graph triples, and more—using a flexible, Python-based definition.
🔄 Automate Incremental Updates: CocoIndex automatically monitors your data sources and transformation logic. When changes occur, it intelligently reprocesses only the necessary portions, reusing caches where possible and clearing stale data, ensuring your index remains consistently fresh with low latency.
🏗️ Simplify Pipeline Management: Forget wrestling with manual schema setup, complex reprocessing logic, or resuming failed jobs. CocoIndex handles the operational heavy lifting: managing table schemas, tracking data/logic versions, ensuring data freshness, and enabling robust recovery from interruptions.
📊 Leverage Built-in Observability: Understand exactly how your data flows and transforms. With integrated lineage tracking and tools like CocoInsight for visualization (e.g., comparing chunking strategies), you gain clarity to debug, optimize, and trust your data pipelines.
🚀 Scale Seamlessly: Define your pipeline once and run it across different scenarios. CocoIndex supports rapid preview runs for development, large-scale batch processing for initial indexing, and continuous low-latency updates for production environments.
🔌 Connect Diverse Ecosystems: Integrate effortlessly with various data sources (web pages, documents, databases, cloud storage, APIs) and target index stores (Vector Stores, Graph Stores, Relational Stores, Object Stores).
How CocoIndex Works for You: Use Cases
Powering Dynamic RAG Systems: Imagine building a RAG application that answers questions based on your company's internal documentation, which is constantly updated. With CocoIndex, you define the pipeline once to ingest docs, chunk them appropriately, generate embeddings, and store them in a vector database. As documents are added or modified, CocoIndex automatically updates the index incrementally, ensuring your RAG system always provides answers based on the latest information without manual intervention or full re-indexing.
Creating Sophisticated Semantic Search: You need to enable semantic search across multiple data silos—product manuals (PDFs), support tickets (database), and marketing content (web pages). CocoIndex allows you to define distinct ingestion and transformation steps for each source, potentially using different chunking or embedding strategies, and consolidate the results into a unified vector index. Its incremental updates keep the search relevant day-to-day.
Building Knowledge Graph-Enhanced AI: For an AI agent requiring structured knowledge, you can use CocoIndex to extract entities and relationships from unstructured text documents, transform them into triples, and load them into a graph database alongside vector embeddings in another store. CocoIndex manages the dependencies and updates both indices as source documents change.
CocoIndex offers a focused solution for a critical AI infrastructure challenge: preparing and maintaining fresh, high-quality data indices. By combining a developer-friendly declarative approach, powerful custom transformation capabilities, and automated incremental updates, it significantly reduces the complexity and operational burden of building robust data pipelines for RAG, semantic search, and other AI applications. Its open-source nature and growing ecosystem make it an accessible and adaptable foundation for your AI projects.
More information on Cocoindex
Launched
2024-12
Pricing Model
Starting Price
Global Rank
1012746
Follow
Month Visit
28.2K
Tech used
Fastly,Next.js,GitHub Pages,Gzip,Varnish,Webpack
Top 5 Countries
56.41%
16.16%
8.43%
4.8%
4.02%
Turkey
Vietnam
United States
India
United Kingdom
Traffic Sources
7.83%
0.55%
0.05%
22.74%
32.08%
36.71%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Cocoindex was manually vetted by our editorial team and was first featured on 2025-03-29.
Related Searches
Cocoindex Alternatives
Load more Alternatives-
-

-

Ragdoll AI simplifies retrieval augmented generation for no-code and low-code teams. Connect your data, configure settings, and deploy powerful RAG APIs quickly.
-
-

CapybaraDB streamlines data management for AI apps. Built on MongoDB and Pinecone, it offers features like EmbJSON for semantic search, async processing, and native multi - modal support. Simplify AI development, reduce costs, and manage diverse data easily.