
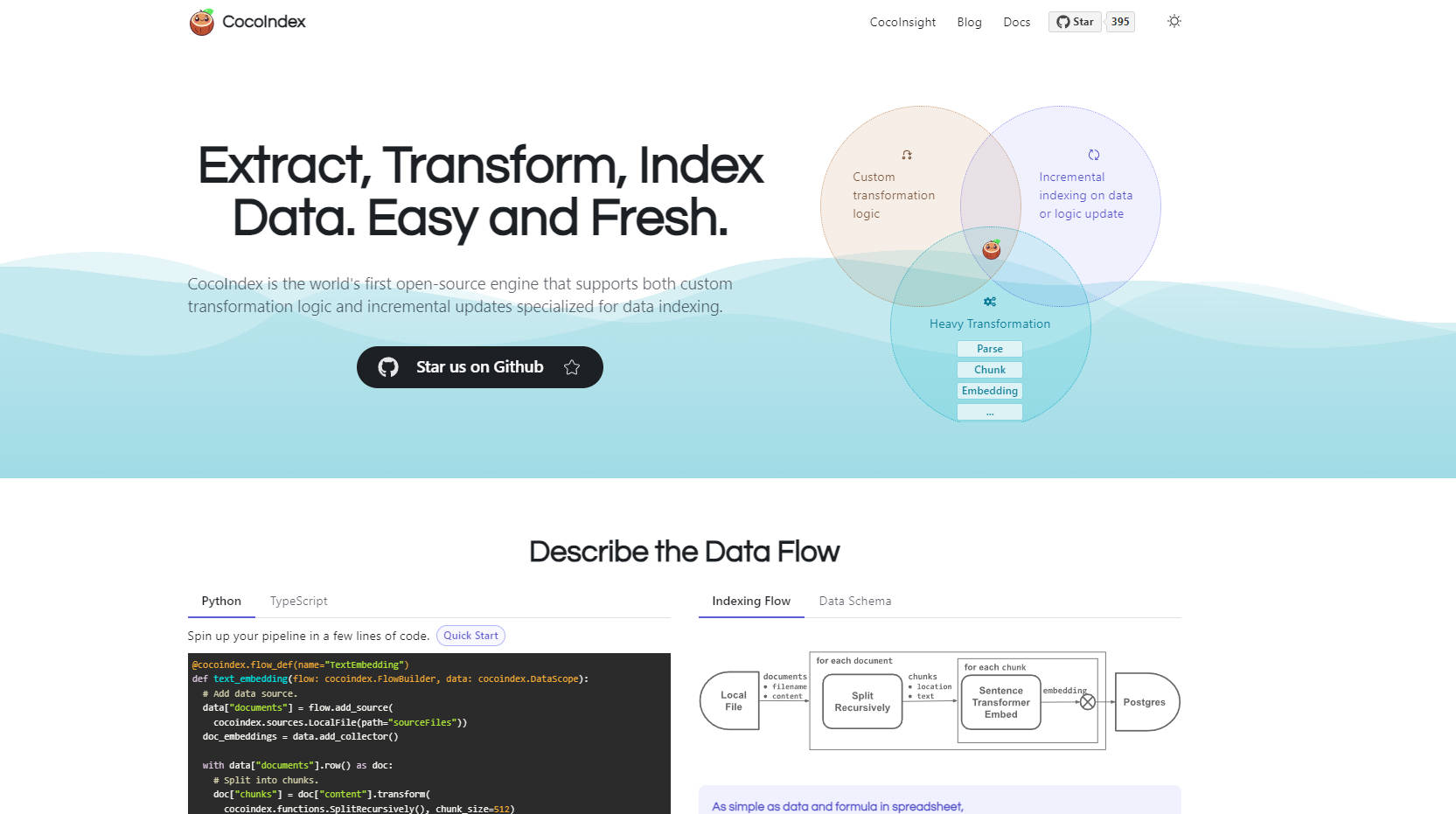
What is Cocoindex?
Создание мощных AI-приложений, таких как системы Retrieval-Augmented Generation (RAG), требует высококачественных, легкодоступных и постоянно обновляемых данных. Однако построение и поддержание необходимых конвейеров данных — извлечение из различных источников, преобразование сложной информации и эффективная индексация — часто является сложной, подверженной ошибкам и трудоемкой задачей. Поддержание синхронизации этих индексированных данных с постоянно меняющимися источниками добавляет еще один уровень сложности.
CocoIndex выступает в качестве фреймворка с открытым исходным кодом, специально разработанного для упрощения всего этого процесса. Он предоставляет надежный, декларативный подход к определению конвейеров индексации данных для AI, уникальным образом сочетая поддержку логики пользовательских преобразований с инкрементными обновлениями в реальном времени. Представьте себе, что вы определяете поток данных как формулу в электронной таблице — вы объявляете источники данных и преобразования, а CocoIndex обрабатывает сложное исполнение, гарантируя, что ваши AI-приложения всегда работают с самой свежей информацией.
Основные возможности:
⚙️ Определение пользовательской ETL-логики: Легко реализуйте свои специфические потребности в обработке данных — разбор различных типов файлов (PDF, HTML, Docs), разделение текста на фрагменты с использованием различных стратегий, создание эмбеддингов с использованием выбранных моделей, извлечение триплетов графа знаний и многое другое — с использованием гибкого определения на основе Python.
🔄 Автоматизация инкрементных обновлений: CocoIndex автоматически отслеживает ваши источники данных и логику преобразования. При внесении изменений он интеллектуально переобрабатывает только необходимые части, повторно используя кеши, где это возможно, и очищая устаревшие данные, гарантируя, что ваш индекс остается постоянно свежим с низкой задержкой.
🏗️ Упрощение управления конвейером: Забудьте о борьбе с ручной настройкой схемы, сложной логикой переобработки или возобновлением неудачных заданий. CocoIndex берет на себя основную часть операционной работы: управление схемами таблиц, отслеживание версий данных/логики, обеспечение актуальности данных и обеспечение надежного восстановления после прерываний.
📊 Использование встроенной наблюдаемости: Поймите, как именно ваши данные передаются и преобразуются. Благодаря интегрированному отслеживанию происхождения и таким инструментам, как CocoInsight для визуализации (например, сравнение стратегий разделения на фрагменты), вы получаете ясность для отладки, оптимизации и доверия к своим конвейерам данных.
🚀 Беспрепятственное масштабирование: Определите свой конвейер один раз и запускайте его в различных сценариях. CocoIndex поддерживает быстрые предварительные запуски для разработки, крупномасштабную пакетную обработку для начальной индексации и непрерывные обновления с низкой задержкой для производственных сред.
🔌 Подключение разнообразных экосистем: Легко интегрируйтесь с различными источниками данных (веб-страницы, документы, базы данных, облачные хранилища, API) и целевыми хранилищами индексов (Vector Stores, Graph Stores, Relational Stores, Object Stores).
Как CocoIndex работает для вас: Варианты использования
Поддержка динамических RAG-систем: Представьте себе создание RAG-приложения, которое отвечает на вопросы на основе внутренней документации вашей компании, которая постоянно обновляется. С помощью CocoIndex вы определяете конвейер один раз для приема документов, правильного разделения их на фрагменты, создания эмбеддингов и хранения их в векторной базе данных. По мере добавления или изменения документов CocoIndex автоматически обновляет индекс инкрементно, гарантируя, что ваша RAG-система всегда предоставляет ответы на основе самой последней информации без ручного вмешательства или полной повторной индексации.
Создание сложного семантического поиска: Вам необходимо включить семантический поиск по нескольким хранилищам данных — руководствам по продуктам (PDF-файлы), заявкам в службу поддержки (база данных) и маркетинговому контенту (веб-страницы). CocoIndex позволяет вам определять отдельные шаги приема и преобразования для каждого источника, потенциально используя различные стратегии разделения на фрагменты или эмбеддинга, и консолидировать результаты в единый векторный индекс. Его инкрементные обновления поддерживают актуальность поиска изо дня в день.
Создание AI с расширенными графами знаний: Для AI-агента, которому требуются структурированные знания, вы можете использовать CocoIndex для извлечения сущностей и связей из неструктурированных текстовых документов, преобразования их в триплеты и загрузки их в базу данных графов вместе с векторными эмбеддингами в другом хранилище. CocoIndex управляет зависимостями и обновляет оба индекса при изменении исходных документов.
CocoIndex предлагает сфокусированное решение для критически важной проблемы AI-инфраструктуры: подготовка и поддержание свежих, высококачественных индексов данных. Сочетая удобный для разработчиков декларативный подход, мощные возможности пользовательских преобразований и автоматизированные инкрементные обновления, он значительно снижает сложность и операционную нагрузку при построении надежных конвейеров данных для RAG, семантического поиска и других AI-приложений. Его открытый исходный код и растущая экосистема делают его доступной и адаптируемой основой для ваших AI-проектов.
More information on Cocoindex
Launched
2024-12
Pricing Model
Starting Price
Global Rank
1012746
Follow
Month Visit
28.2K
Tech used
Fastly,Next.js,GitHub Pages,Gzip,Varnish,Webpack
Top 5 Countries
56.41%
16.16%
8.43%
4.8%
4.02%
Turkey
Vietnam
United States
India
United Kingdom
Traffic Sources
7.83%
0.55%
0.05%
22.74%
32.08%
36.71%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Cocoindex was manually vetted by our editorial team and was first featured on 2025-03-29.
Related Searches
Cocoindex Альтернативи
Больше Альтернативи-
-

-

Ragdoll AI упрощает процесс генерации с дополненным поиском для no-code и low-code команд. Подключите свои данные, настройте параметры и быстро разверните мощные RAG API.
-
-

CapybaraDB упрощает управление данными для приложений на базе ИИ. Построенная на основе MongoDB и Pinecone, она предлагает такие функции, как EmbJSON для семантического поиска, асинхронную обработку и встроенную поддержку различных типов данных. Оптимизируйте разработку ИИ, сократите расходы и с легкостью управляйте разнообразными данными.