
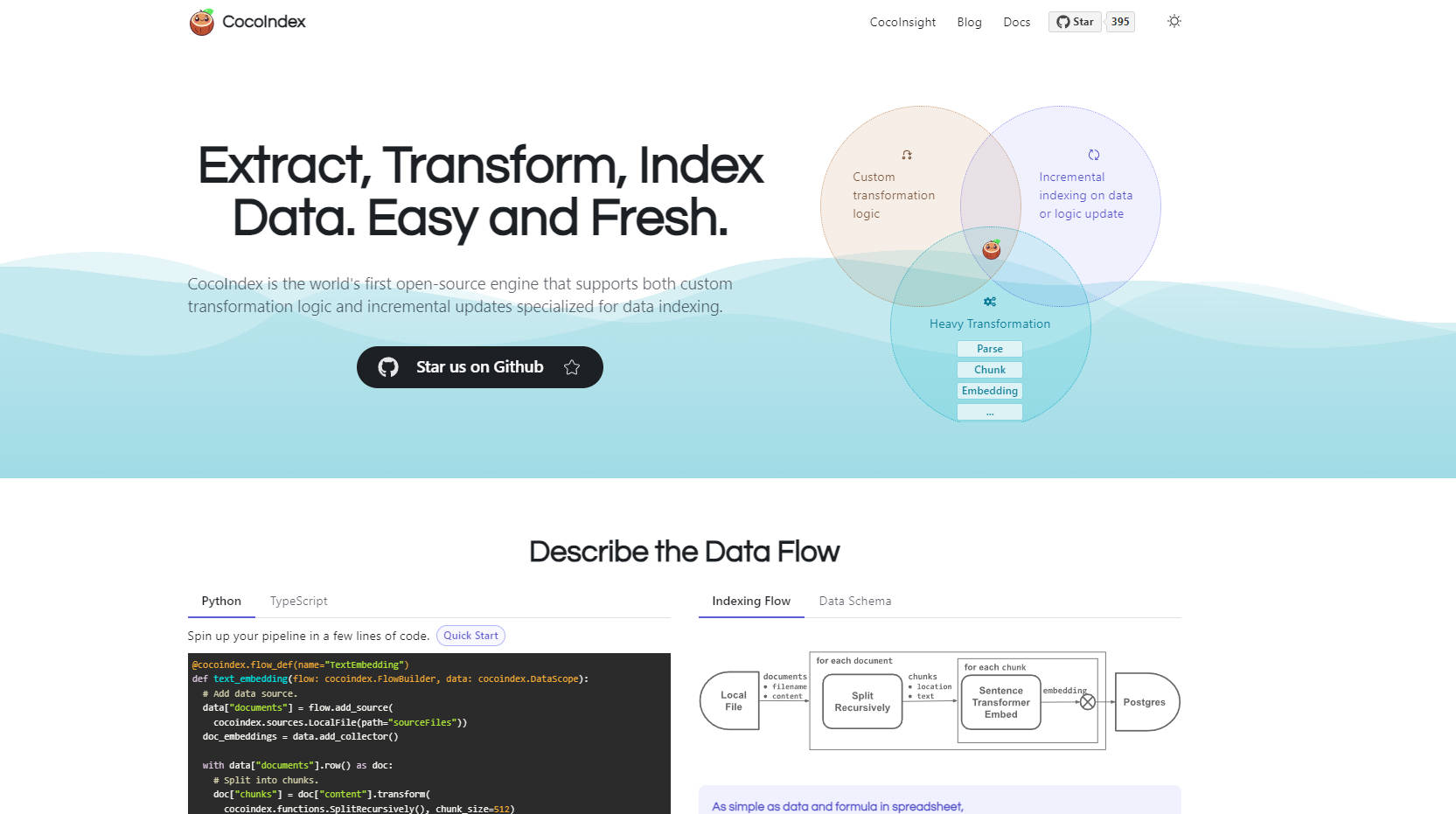
What is Cocoindex?
构建如检索增强生成(RAG)系统这样强大的 AI 应用,需要高质量、易于访问且始终保持最新状态的数据。然而,构建和维护必要的数据管道——从各种来源提取数据、转换复杂信息并有效地进行索引——通常是一项复杂、容易出错且耗时的挑战。让这些索引数据与不断变化的来源保持同步,又增加了另一层难度。
CocoIndex 作为一个开源框架应运而生,专门用于简化整个流程。它为 AI 提供了一种强大且声明式的数据索引管道定义方法,独特地结合了对自定义转换逻辑和实时增量更新的支持。您可以将其视为像定义电子表格公式一样定义数据流——您声明数据源和转换,而 CocoIndex 处理复杂的执行过程,确保您的 AI 应用始终使用最新鲜的信息。
主要功能:
⚙️ 定义自定义 ETL 逻辑:使用灵活的、基于 Python 的定义,轻松实现您特定的数据处理需求——解析各种文件类型(PDF、HTML、Docs),使用不同的策略对文本进行分块,使用您选择的模型生成嵌入,提取知识图谱三元组等等。
🔄 自动化增量更新:CocoIndex 自动监控您的数据源和转换逻辑。当发生更改时,它会智能地仅重新处理必要的局部,尽可能重用缓存并清除陈旧数据,从而确保您的索引始终保持最新状态,并且延迟较低。
🏗️ 简化管道管理:无需再费力处理手动模式设置、复杂的重新处理逻辑或恢复失败的作业。CocoIndex 处理繁重的运营工作:管理表模式、跟踪数据/逻辑版本、确保数据新鲜度以及实现从中断中的稳健恢复。
📊 利用内置的可观察性:准确了解您的数据如何流动和转换。通过集成的沿袭跟踪和用于可视化的工具(如 CocoInsight,例如比较分块策略),您可以清楚地了解如何调试、优化和信任您的数据管道。
🚀 无缝扩展:定义一次管道,并在不同的场景中运行它。CocoIndex 支持用于开发的快速预览运行、用于初始索引的大规模批处理以及用于生产环境的连续低延迟更新。
🔌 连接多样化的生态系统:轻松与各种数据源(网页、文档、数据库、云存储、API)和目标索引存储(Vector Stores、Graph Stores、Relational Stores、Object Stores)集成。
CocoIndex 如何为您服务:用例
为动态 RAG 系统提供支持:想象一下构建一个 RAG 应用程序,该应用程序根据您公司不断更新的内部文档来回答问题。使用 CocoIndex,您可以定义一次管道来提取文档、适当地对它们进行分块、生成嵌入并将它们存储在向量数据库中。当添加或修改文档时,CocoIndex 会自动以增量方式更新索引,从而确保您的 RAG 系统始终根据最新信息提供答案,而无需手动干预或完全重新索引。
创建复杂的语义搜索:您需要在多个数据孤岛(产品手册(PDF)、支持票证(数据库)和营销内容(网页))上启用语义搜索。CocoIndex 允许您为每个源定义不同的提取和转换步骤,可以采用不同的分块或嵌入策略,并将结果整合到统一的向量索引中。它的增量更新使搜索每天都保持相关性。
构建知识图谱增强的 AI:对于需要结构化知识的 AI 代理,您可以使用 CocoIndex 从非结构化文本文档中提取实体和关系,将它们转换为三元组,并将它们加载到图数据库中,同时将向量嵌入存储在另一个存储中。CocoIndex 管理依赖项并在源文档更改时更新两个索引。
CocoIndex 为关键的 AI 基础设施挑战提供了一个重点明确的解决方案:准备和维护新鲜、高质量的数据索引。通过结合对开发者友好的声明式方法、强大的自定义转换能力和自动化的增量更新,它大大降低了为 RAG、语义搜索和其他 AI 应用构建稳健数据管道的复杂性和运营负担。它的开源性质和不断增长的生态系统使其成为您 AI 项目的可访问且适应性强的基础。
More information on Cocoindex
Launched
2024-12
Pricing Model
Starting Price
Global Rank
1012746
Follow
Month Visit
28.2K
Tech used
Fastly,Next.js,GitHub Pages,Gzip,Varnish,Webpack
Top 5 Countries
56.41%
16.16%
8.43%
4.8%
4.02%
Turkey
Vietnam
United States
India
United Kingdom
Traffic Sources
7.83%
0.55%
0.05%
22.74%
32.08%
36.71%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Cocoindex was manually vetted by our editorial team and was first featured on 2025-03-29.
Related Searches
Cocoindex 替代方案
更多 替代方案-
-

-

Ragdoll AI 赋能无代码和低代码团队,大幅简化了检索增强生成(RAG)的过程。您只需轻松接入数据、完成各项配置,即可迅速部署功能强大的 RAG API。
-
-

CapybaraDB 简化了人工智能应用的数据管理。它基于 MongoDB 和 Pinecone 构建,提供诸如 EmbJSON 用于语义搜索、异步处理以及原生多模态支持等功能。CapybaraDB 助您简化人工智能开发流程,降低成本,并轻松管理多样化的数据。