
What is Yi-VL-34B?
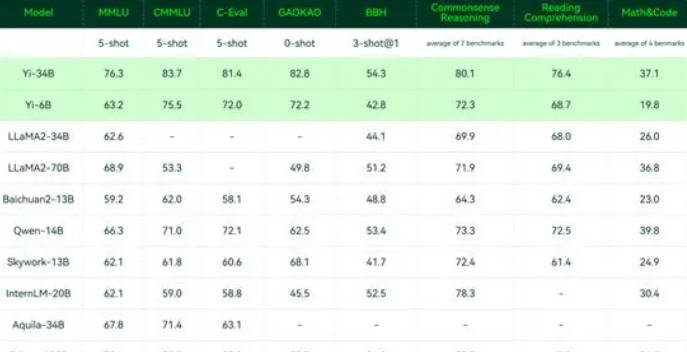
Yi-VL, un innovador modelo de lenguaje multimodal de Zero-One Things, marca una nueva era en la IA multimodal. Se basa en el modelo de lenguaje Yi y presenta las versiones Yi-VL-34B y Yi-VL-6B, que destacan en el novedoso banco de pruebas MMMU. Su arquitectura innovadora, una combinación de Vision Transformer (ViT) y el módulo Projection, alinea de manera eficiente las características de la imagen y el texto, junto con las capacidades lingüísticas de Yi.
Características clave:
-
? Comprensión de imágenes: Yi-VL comprende la información visual a través de ViT, extrayendo detalles cruciales y conceptos de alto nivel.
-
? Fusión multimodal: El módulo Projection alinea a la perfección las características de la imagen y el texto, lo que facilita su interacción efectiva.
-
? Generación de lenguaje: Yi-VL aprovecha sus capacidades lingüísticas para generar respuestas de texto coherentes e informativas, lo que mejora su comunicación multimodal.
Casos de uso:
-
? Educación: La capacidad de Yi-VL para interpretar diagramas e instrucciones escritas lo convierte en una herramienta valiosa para el aprendizaje interactivo.
-
? Salud: Yi-VL puede analizar imágenes médicas y registros de pacientes, lo que ayuda a los profesionales de la salud en las decisiones de diagnóstico y tratamiento.
-
? Entretenimiento: Las capacidades de generación de imágenes y lenguaje de Yi-VL ofrecen posibilidades emocionantes para experiencias de juego inmersivas.
Conclusión:
Yi-VL se destaca como un extraordinario modelo de lenguaje multimodal que abre nuevas fronteras en la comprensión y generación de información compleja por parte de la IA. Su potencial se extiende a varios dominios, y su naturaleza de código abierto promete acelerar la innovación en la IA multimodal. El viaje de Yi-VL marca un momento crucial en el avance de la IA, acercándonos a la realización de su vasto potencial y transformando las industrias.
More information on Yi-VL-34B
Launched
2024
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Yi-VL-34B was manually vetted by our editorial team and was first featured on 2024-01-23.
Related Searches
Yi-VL-34B Alternativas
Más Alternativas-

-

C4AI Aya Vision 8B: IA de visión multilingüe de código abierto para la comprensión de imágenes. Reconocimiento óptico de caracteres (OCR), subtitulado y razonamiento en 23 idiomas.
-

-

-
