
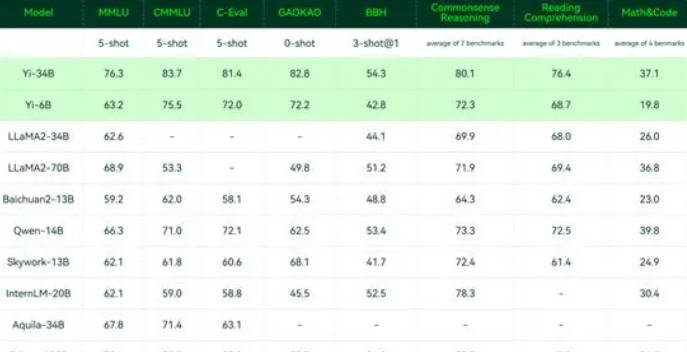
What is Yi-VL-34B?
Yi-, un modèle de langage multimodal innovant de Zero-One Things, marque une ère nouvelle dans l'IA multimodale. C’est un modèle de langage puissance 34 et 6 Milliards de milliards, et qui excelle dans le test MMMU. Son architecture innovante, un mélange de Vision Transfo Rmer (ViT) et de module de Projection, permet d'aligner les fonctions image et texte, avec les capacités linguistique du modèle.
Caractéristiques principales :
? Image : Yi- comprend les informations visuelles grâce à ViT, en extrayant des détails cruciaux et des concepts de haut niveau.
? Multimodal : Le module De Projection alignement de façons transparentes les fonctions d'image et de texte, ce qui facilite leur interaction efficace.
? Génération linguistique : Yi- exploite ses capacités linguistique à génér des réactions textuelles et à dialoguer avec du texte, ce qui enrichit sa communication multimodale.
Utilisation :
? Éducation : La capacité de Yi- à interpréter des instruction orales et écrites en font un outil précieux pour un apprentissage interactif.
? Santé : Yi- peut analyser des images médicales et les dossiers patients, ce qui aide les soignants dans les décisions de diagnostic et de traitements.
? Jeu vidéo : Les capacités de génération d'image et de langue de Yi- offrent des perspectives enchanteresses d'expériences de jeux immersifs.
Conclusion :
Yi- se profile en modèle linguistique multimodal remarquable qui ouvre de Nouveaux frontières dans la compréhension et la génération d’informations par l'IA. Son potentiel s'étend à travers différent secteur et sa nature open source est promise à accél l' invention dans l'IA multimodale. Yi- marque un instant crucial dans l'histoire de l'IA, nous rapprochant un peau plus loin de son général potentiel et révolution des secteurs.
More information on Yi-VL-34B
Launched
2024
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Yi-VL-34B was manually vetted by our editorial team and was first featured on 2024-01-23.
Related Searches
Yi-VL-34B Alternatives
Plus Alternatives-

-

C4AI Aya Vision 8B : IA de vision multilingue open source pour la compréhension d'images. ROC, légende, raisonnement en 23 langues.
-

-

-
