
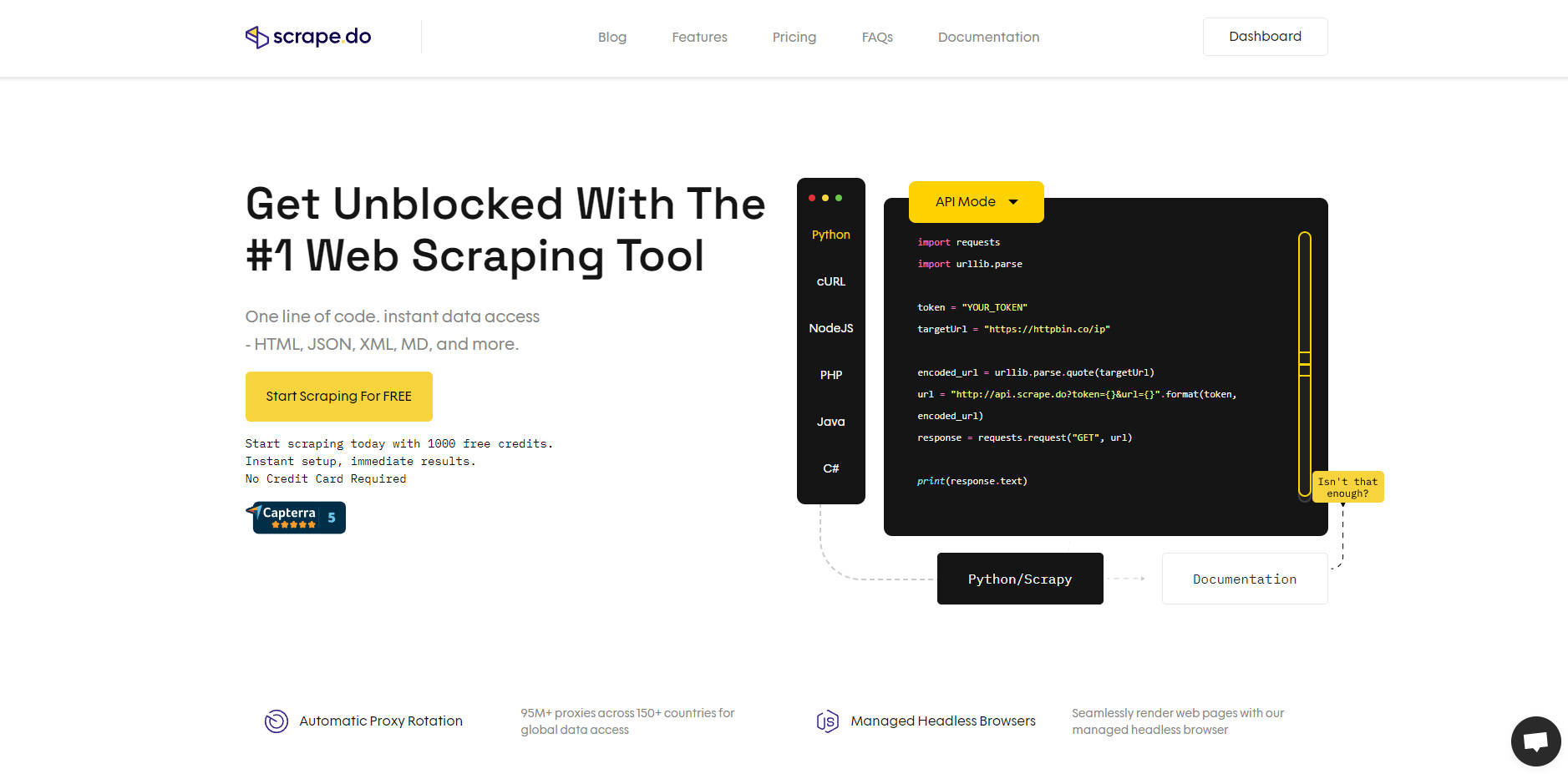
What is Scrape.do?
Scrape.do est une API d'extraction web puissante et une solution de proxy rotatif conçue pour simplifier la collecte de données tout en contournant les systèmes anti-robots. Que vous réalisiez des études de marché, entraîniez des modèles d'IA ou automatisiez des flux de travail, Scrape.do gère les complexités des proxies, des navigateurs headless et de la résolution CAPTCHA afin que vous puissiez vous concentrer sur l'essentiel : vos données.
Pourquoi choisir Scrape.do ?
Scrape.do élimine les obstacles courants de l'extraction web en offrant :
Rotation automatique des proxies : Accédez à plus de 95 millions de proxies dans plus de 150 pays pour un accès mondial aux données sans interruption.
Navigateurs headless gérés : Affichez les pages comme un utilisateur réel, automatisez les interactions et assurez-vous du chargement complet des données.
Technologie de contournement anti-robots : Extrayez des données de n'importe quel site web sans être bloqué, même sur les sites dotés de mesures anti-scraping strictes.
Passerelle ultra-rapide : Bénéficiez d'une vitesse inégalée pour des résultats instantanés.
Avec une seule ligne de code, vous pouvez intégrer Scrape.do à votre flux de travail et commencer à collecter des données en quelques secondes.
Fonctionnalités clés
Proxies rotatifs dans plus de 150 pays
Faites pivoter automatiquement les adresses IP pour chaque requête, garantissant ainsi l'anonymat et évitant les blocages. Idéal pour le géociblage des données provenant de régions spécifiques.Automatisation du navigateur headless
Simulez les interactions réelles des utilisateurs, telles que cliquer sur des boutons, faire défiler des pages et attendre le chargement du contenu dynamique.Prise en charge de plusieurs formats de données
Récupérez des données aux formats HTML, JSON, XML, MD, etc., en fonction de la réponse du site web cible.Requêtes personnalisables
Ajustez les en-têtes, les cookies, le rendu JavaScript et le ciblage géographique en fonction de vos besoins spécifiques.Collecte de données prête pour les LLM
Extrayez des sites web entiers au format Markdown avec un seul paramètre, idéal pour l'entraînement de grands modèles linguistiques (LLM).Notifications en temps réel via des webhooks
Automatisez les flux de travail en recevant des mises à jour instantanées lorsque vos données sont traitées.
Cas d'utilisation
Étude de marché
Une agence de marketing doit surveiller les prix des concurrents sur plusieurs plateformes de commerce électronique. Avec Scrape.do, elle peut extraire les listes de produits en temps réel, en utilisant des proxies résidentiels pour éviter la détection et recueillir des données précises sans interruption.Entraînement de modèles d'IA
Une startup technologique souhaite entraîner un modèle d'IA pour analyser les avis des clients. En tirant parti de la capacité de Scrape.do à extraire des données au format Markdown, elle collecte efficacement des ensembles de données d'avis provenant de divers sites web, ce qui permet d'économiser du temps et des ressources.Expansion mondiale du commerce électronique
Un détaillant en ligne prévoit de s'étendre à de nouveaux marchés, mais a besoin de données localisées sur les préférences des consommateurs. En utilisant les proxies géociblés de Scrape.do, il extrait les sites de commerce électronique régionaux pour identifier les produits à la mode et optimiser sa stratégie d'inventaire.
Pourquoi les développeurs adorent Scrape.do
Intégration rapide : Configurez en moins de 30 secondes avec un minimum de code requis.
Ne payez que pour le succès : Les crédits ne sont consommés que pour les requêtes réussies, ce qui garantit la rentabilité.
Performance fiable : Bénéficiez d'une garantie de disponibilité de 99,9 % et d'une assistance d'experts 24h/24 et 7j/7.
Solutions évolutives : Que vous soyez une petite entreprise ou une grande entreprise, Scrape.do s'adapte à vos besoins.
Démarrez dès aujourd'hui
Inscrivez-vous maintenant et recevez 1 000 crédits gratuits pour explorer les capacités de Scrape.do. Aucune carte de crédit n'est requise.
More information on Scrape.do
Launched
2020-04
Pricing Model
Free Trial
Starting Price
$29/mo
Global Rank
351452
Follow
Month Visit
98.3K
Tech used
Cloudflare Analytics,Google Tag Manager,Cloudflare CDN,JSDelivr,Hugo,Google Fonts,Bootstrap,Clipboard.js,Popper.js,Gzip,OpenGraph,HSTS
Top 5 Countries
17.09%
13.23%
7.28%
5.18%
4.68%
United Kingdom
United States
Canada
India
Pakistan
Traffic Sources
3.79%
0.8%
0.12%
8.66%
50.88%
35.77%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Scrape.do was manually vetted by our editorial team and was first featured on 2025-02-17.
Related Searches
Scrape.do Alternatives
Plus Alternatives-

Scrapeless : La boîte à outils d'extraction de données web, optimisée par l'IA, pour une extraction sans tracas. Contournez les blocages, résolvez les CAPTCHA et évoluez sans effort.
-

Ne luttez plus contre les bloqueurs de web scraping. ScrapingAnt API assure une extraction de données fiable, gérant les proxys, les CAPTCHA et le JS. Obtenez rapidement des données épurées.
-

Vous avez besoin de données web ? MrScraper utilise l'IA pour un web scraping facile et sans code. Extrayez des données propres de n'importe quel site, en contournant les blocages anti-bot grâce à de puissants proxies.
-

ScrapingBee est l'API de web scraping tout-en-un. Nous prenons en charge la gestion des navigateurs, des proxies et des blocages, vous assurant ainsi d'obtenir des données fiables sans la moindre contrainte d'infrastructure.
-

UseScraper est une puissante API de web crawler et de scraping permettant une extraction de données efficace. Extrayez des données, affichez JavaScript et choisissez facilement des formats de sortie.