
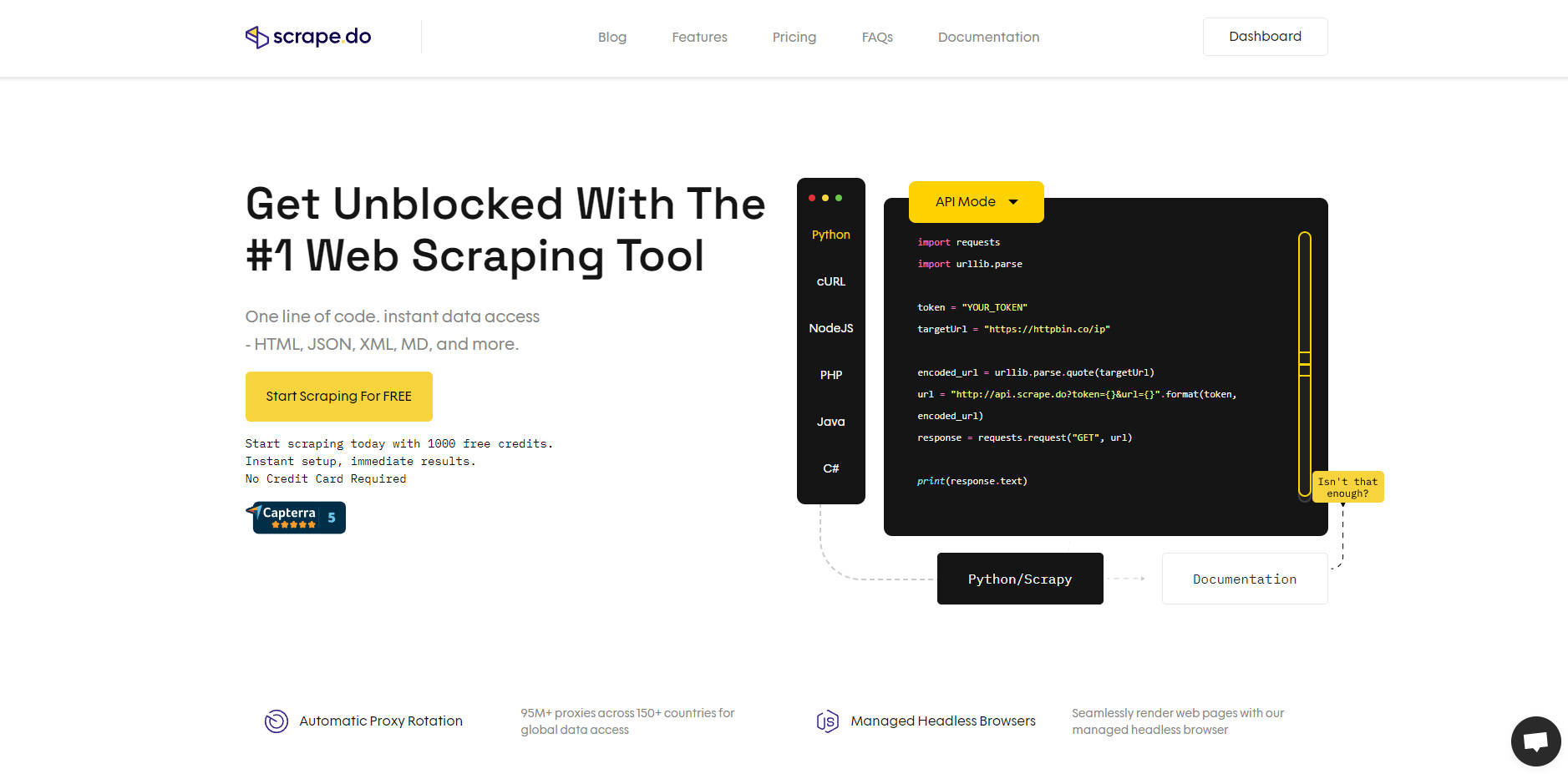
What is Scrape.do?
Scrape.do 是一款强大的网页抓取 API 和轮换代理解决方案,旨在简化数据收集,同时绕过反爬虫系统。无论您是进行市场调研、训练 AI 模型还是自动化工作流程,Scrape.do 都能处理代理、无头浏览器和 CAPTCHA 验证等复杂问题,让您专注于最重要的事情——您的数据。
为何选择 Scrape.do?
Scrape.do 通过提供以下功能,消除了网页抓取中的常见障碍:
自动代理轮换:访问 150 多个国家/地区的 9500 万多个代理,实现不间断的全球数据访问。
托管式无头浏览器:像真实用户一样渲染页面,自动化交互,并确保完整的数据加载。
反爬虫绕过技术:抓取任何网站而不会被阻止,即使是具有严格反爬虫措施的网站。
极速网关:体验行业领先的速度,获得即时结果。
只需一行代码,您就可以将 Scrape.do 集成到您的工作流程中,并在几秒钟内开始收集数据。
主要特性
跨 150 多个国家/地区的轮换代理
自动为每个请求轮换 IP,确保匿名性并避免被阻止。非常适合从特定地区进行地理定位数据。无头浏览器自动化
模拟真实用户交互,例如单击按钮、滚动页面以及等待动态内容加载。支持多种数据格式
根据目标网站的响应,以 HTML、JSON、XML、MD 等格式检索数据。可定制的请求
微调标头、cookie、JavaScript 渲染和地理目标定位,以满足您的特定需求。LLM 就绪的数据收集
使用单个参数以 Markdown 格式抓取整个网站,非常适合训练大型语言模型 (LLM)。通过 Webhooks 实时通知
通过在数据处理完毕后接收即时更新来自动化工作流程。
用例
市场调研
一家营销机构需要监控多个电子商务平台上的竞争对手定价。借助 Scrape.do,他们可以实时抓取产品列表,使用住宅代理来避免检测,并收集准确的数据而不会中断。AI 模型训练
一家科技创业公司希望训练一个 AI 模型来分析客户评论。通过利用 Scrape.do 以 Markdown 格式提取数据的能力,他们可以有效地从各种网站收集评论数据集,从而节省时间和资源。全球电子商务扩张
一家在线零售商计划扩展到新市场,但需要有关消费者偏好的本地化数据。使用 Scrape.do 的地理定位代理,他们抓取区域电子商务网站以识别趋势产品并优化其库存策略。
为什么开发者喜欢 Scrape.do
快速集成:只需极少的编码即可在 30 秒内完成设置。
仅为成功付费:仅为成功的请求消耗积分,确保成本效益。
可靠的性能:以 99.9% 的正常运行时间保证和全天候专家支持为后盾。
可扩展的解决方案:无论您是小型企业还是大型企业,Scrape.do 都能适应您的需求。
立即开始
立即注册并获得 1,000 个免费积分,以探索 Scrape.do 的功能。无需信用卡。
More information on Scrape.do
Launched
2020-04
Pricing Model
Free Trial
Starting Price
$29/mo
Global Rank
351452
Follow
Month Visit
98.3K
Tech used
Cloudflare Analytics,Google Tag Manager,Cloudflare CDN,JSDelivr,Hugo,Google Fonts,Bootstrap,Clipboard.js,Popper.js,Gzip,OpenGraph,HSTS
Top 5 Countries
17.09%
13.23%
7.28%
5.18%
4.68%
United Kingdom
United States
Canada
India
Pakistan
Traffic Sources
3.79%
0.8%
0.12%
8.66%
50.88%
35.77%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Scrape.do was manually vetted by our editorial team and was first featured on 2025-02-17.
Related Searches
Scrape.do 替代方案
更多 替代方案-

-

告别与反爬机制的苦战。ScrapingAnt API 助您轻松实现可靠数据提取,它能自动处理代理、验证码和JavaScript等技术难题,让您迅速获取纯净、高质量的数据。
-

需要网络数据吗?MrScraper融合AI技术,为您提供便捷的无代码网页抓取方案。无论何种网站,都能助您轻松提取纯净数据,并凭借强大的代理服务器,有效突破各类反爬虫限制。
-

ScrapingBee 是您的一站式网页抓取API解决方案。我们为您全面管理浏览器、代理服务器及各类反爬阻碍,确保您无需投入繁琐的基建精力,也能轻松获得准确可靠的数据。
-
