What is Annoy?
Annoy (Approximate Nearest Neighbors Oh Yeah)は、効率的で高速な近似最近傍検索のために設計された、Pythonバインディング付きのC++ライブラリです。大規模データセットに最適で、メモリ効率と高速なクエリ時間を提供し、静的および動的インデックス操作の両方をサポートします。Annoyはカスタム距離メトリックを備えており、Spotifyで高次元ベクトル空間分析を通じて音楽推薦に使用されています。
主な機能:
? 静的および動的インデックス付け- Annoyは、静的および動的データセットの両方をサポートし、データのニーズに適応します。
プロセス間で共有できるインデックスを作成し、メモリ使用量を最適化します。
? 速度とメモリ効率- 最小のメモリフットプリントで高速なクエリ時間を実現するように設計されています。
メモリマップドファイルを使用してインデックスを共有し、マルチプロセス環境でのパフォーマンスを向上させます。
? カスタム距離メトリック- ユークリッド、マンハッタン、アングラー、ハミング、ドット積など、さまざまな距離メトリックを提供します。
さまざまな種類のベクトル空間分析に柔軟に対応し、さまざまなデータセットに適しています。
? 言語バインディング- Python、C++、その他の言語で利用可能で、幅広いアクセシビリティと統合の容易さを実現します。
?️ 簡単なインストールと使用- pipによる迅速なインストールと、使用の容易さを目的とした例とチュートリアルを含む直感的なPython API。
ユースケース:
? 音楽推薦システム- Annoyは、高次元空間で類似するユーザー/アイテムを効率的に見つけることができ、パーソナライズされた音楽推薦に不可欠です。
? 大規模情報検索- 従来の検索方法が役に立たない大規模データセットに適したAnnoyは、大規模な最近傍検索を迅速に処理できます。
? 分散コンピューティング- Hadoopジョブなどの環境に最適で、インデックスを複数のプロセス間で共有することで、冗長な計算を最小限に抑えることができます。
結論:
Annoyは、速度、メモリ効率、柔軟性のバランスにより、最近傍検索の世界で際立っており、大規模で複雑なデータセットを処理するための貴重なツールとなっています。推薦を通じてユーザーエクスペリエンスを向上させるか、大規模データ分析の効率を向上させるかにかかわらず、Annoyは迅速かつ正確な結果を提供するように設計されています。
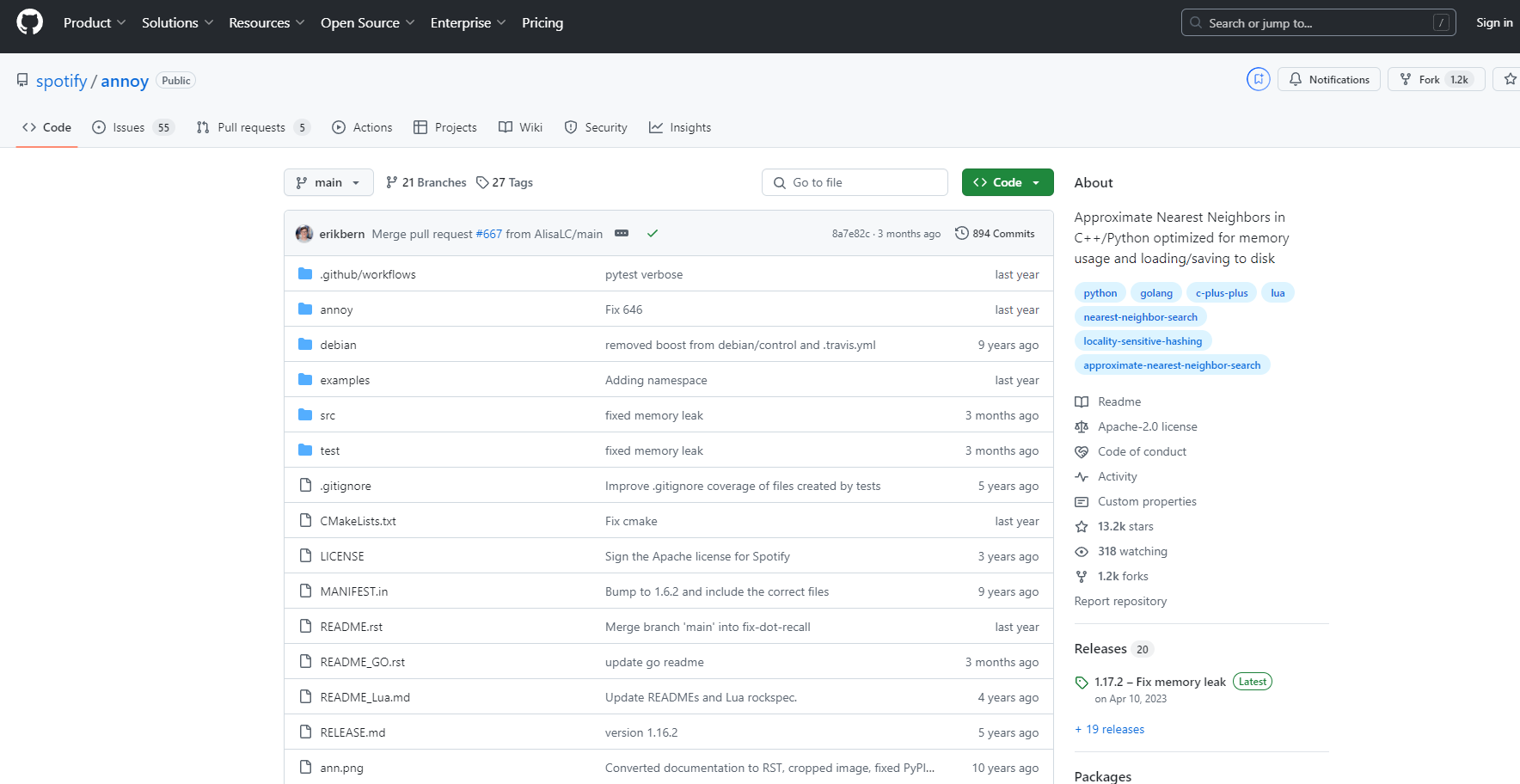
More information on Annoy
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Annoy was manually vetted by our editorial team and was first featured on 2024-10-07.
Related Searches