What is Annoy?
Annoy (Approximate Nearest Neighbors Oh Yeah)는 효율적이고 빠른 근사 최근접 이웃 검색을 위해 설계된 Python 바인딩을 포함한 C++ 라이브러리입니다. 대규모 데이터 세트에 이상적이며, 정적 및 동적 인덱스 작업을 모두 지원하여 메모리 효율성과 빠른 쿼리 시간을 제공합니다. Annoy는 사용자 지정 거리 지표를 갖추고 있으며 Spotify에서 고차원 벡터 공간 분석을 통한 음악 추천에 사용됩니다.
주요 기능:
? 정적 및 동적 인덱싱- Annoy는 데이터 요구 사항에 맞게 정적 및 동적 데이터 세트를 모두 지원합니다.
프로세스 간에 공유할 수 있는 인덱스를 생성하여 메모리 사용량을 최적화합니다.
? 속도 및 메모리 효율성- 최소한의 메모리 공간으로 빠른 쿼리 시간을 위해 설계되었습니다.
멀티 프로세스 환경에서 성능을 향상시키기 위해 메모리 매핑 파일을 사용하여 인덱스를 공유합니다.
? 사용자 지정 거리 지표- 유클리드, 맨해튼, 각도, 해밍 및 점곱과 같은 다양한 거리 지표를 제공합니다.
다양한 유형의 벡터 공간 분석에 유연하며 다양한 데이터 세트에 적합합니다.
? 언어 바인딩- Python, C++ 및 기타 언어에서 사용할 수 있어 광범위한 접근성과 통합 용이성을 보장합니다.
?️ 쉬운 설치 및 사용- pip를 통한 빠른 설치 및 사용 편의성을 위한 예제와 튜토리얼이 포함된 직관적인 Python API.
사용 사례:
? 음악 추천 시스템- Annoy는 고차원 공간에서 유사한 사용자/항목을 효율적으로 찾을 수 있으며, 개인 맞춤형 음악 추천에 필수적입니다.
? 대규모 정보 검색- 기존 검색 방법이 부족한 대규모 데이터 세트에 적합하며 Annoy는 대규모 최근접 이웃 검색을 신속하게 처리할 수 있습니다.
? 분산 컴퓨팅- 인덱스를 여러 프로세스 간에 공유하여 중복 계산을 최소화할 수 있는 Hadoop 작업과 같은 환경에 이상적입니다.
결론:
Annoy는 속도, 메모리 효율성 및 유연성의 균형 덕분에 근사 최근접 이웃 검색 분야에서 돋보이며, 대규모 복잡한 데이터 세트를 처리하는 데 귀중한 도구입니다. 추천을 통한 사용자 경험 향상이나 대규모 데이터 분석 효율성 향상 여부에 관계없이 Annoy는 정확한 결과를 빠르게 제공하도록 설계되었습니다.
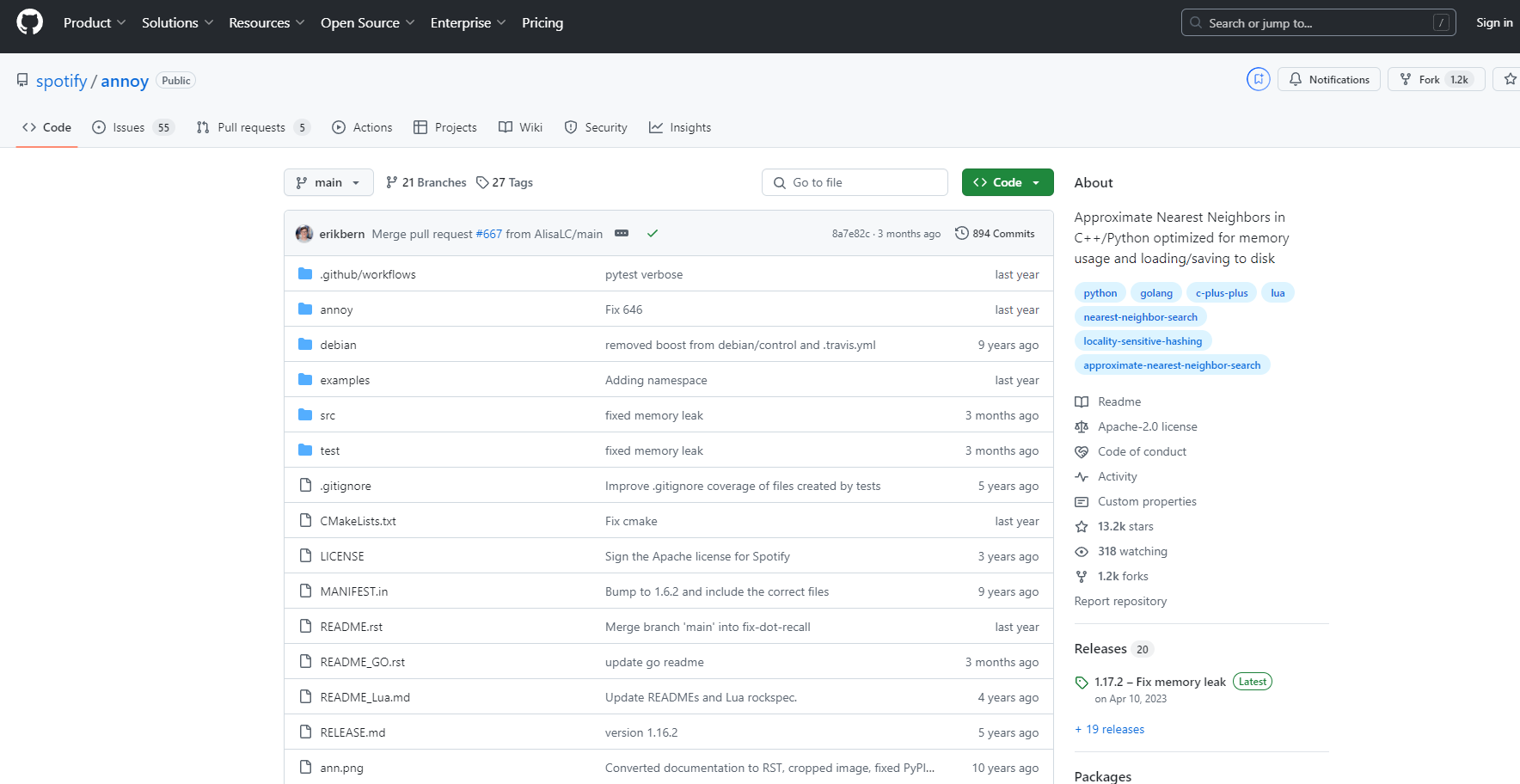
More information on Annoy
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Annoy was manually vetted by our editorial team and was first featured on 2024-10-07.
Related Searches