
What is ModelRed?
ModelRedは、大規模言語モデル(LLM)における影響の大きい脆弱性をプロアクティブに特定し、軽減するために設計された、AIセキュリティ&レッドチーミング特化型プラットフォームです。これにより、エンジニアリング、セキュリティ、プラットフォームチームは、真の自信を持ってAIシステムを構築・展開でき、デプロイ前からランタイムに至るまで、進化する脅威に対して堅牢な保護を保証します。
主要機能
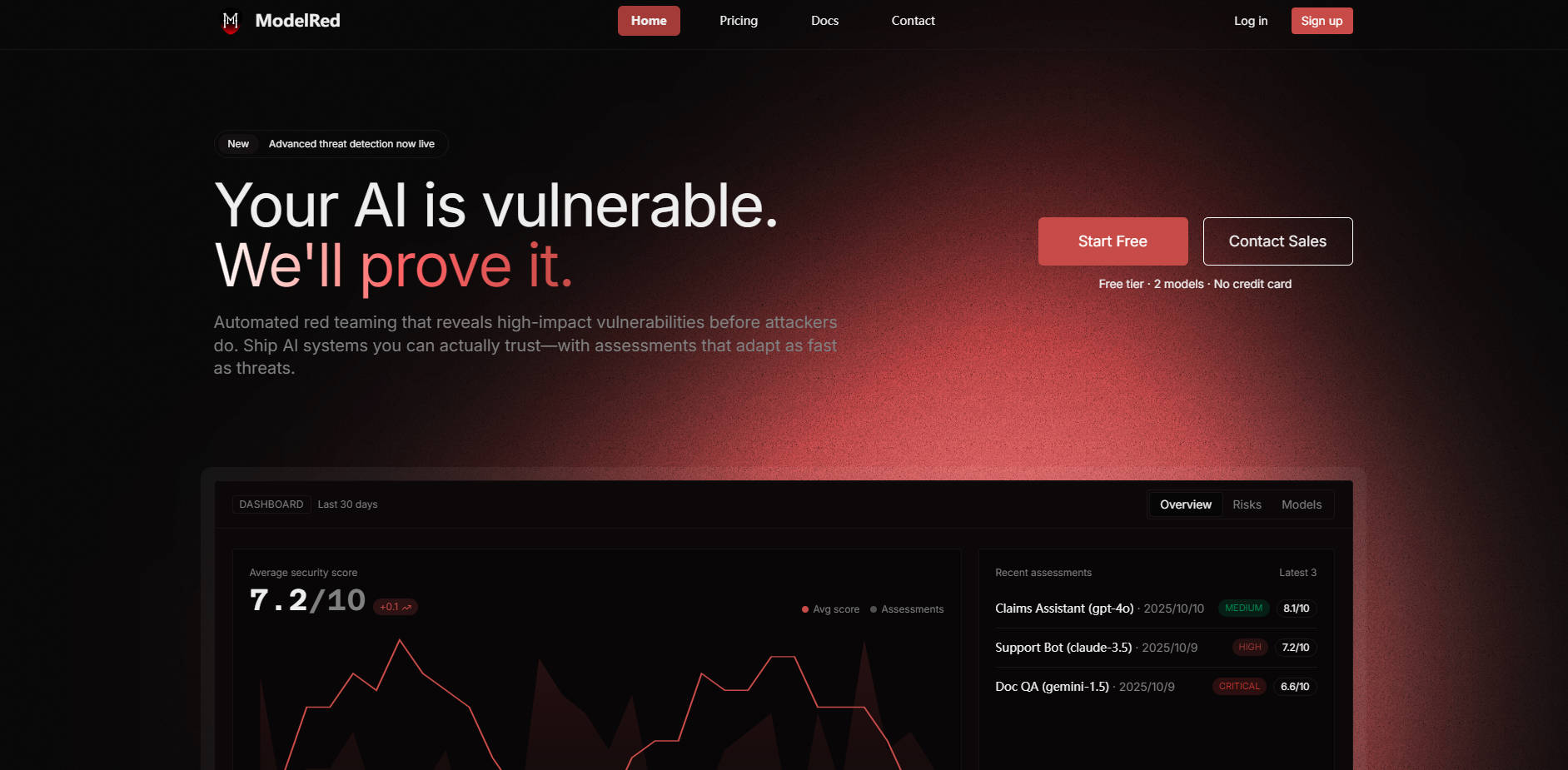
🛡️ アダプティブ・レッドチーム・プローブ: モデルの応答に合わせて進化する10,000以上の攻撃ベクターライブラリを活用できます。この動的なアプローチは、隠れた脆弱性を明らかにし、OWASP LLMのリスクを包括的にカバーします。また、効果的な修復のために再現可能な証拠を提供します。
🚫 プロンプトインジェクション検出: モデルが侵害される前に、操作パターンやコンテキストハイジャックの試みを99.2%の精度で検出します。ModelRedは、高度なパターンおよびセマンティックヒューリスティクスを活用し、デプロイ前と稼働中の両方でリアルタイム保護を提供します。
🔒 ジェイルブレイク防止: 洗練されたバイパス試行やガードレールドリフトに対して、応答時間の中央値わずか2.3ミリ秒でAIシステムをストレステストします。この機能は、攻撃連鎖と自動生成されるバリアントを利用して、モデルの防御をプロアクティブに強化します。
🔄 大規模な継続的セキュリティ: 毎月10,000を超える新しい攻撃ベクターを検出するシステムにより、AI防御が進化する脅威よりも迅速に自動的に進化・適応することを保証します。
ユースケース
ModelRedは、堅牢なAIセキュリティを運用にシームレスに統合できるよう支援します。
デプロイ前脆弱性発見: ModelRedをCI/CDパイプラインに統合することで、すべてのコード変更に対してセキュリティプローブを自動実行できます。これにより、脆弱性の悪用経路が早期に明らかになり、リスクのあるマージを阻止し、脆弱性が本番環境に到達するのを防ぐための明確で再現可能な証拠が提供されます。
リアルタイムランタイム保護: ModelRedをデプロイし、稼働中のAIアプリケーションを継続的に監視することで、特定された脅威の99.8%を自動的に検出しブロックします。これにより、手動介入なしに、継続的な敵対的攻撃からAIシステムが安全に保護され続けます。
業界固有のコンプライアンス: 規制の厳しい業界向けに調整された専門プローブを活用します。例えば、ヘルスケア分野では、ModelRedは患者データのクエリをHIPAA準拠でスクリーニングします。金融サービス分野では、取引アルゴリズムを保護し、データ漏洩をブロックし、SOC 2 Type IIへの対応を支援します。
ModelRedを選ぶ理由
ModelRedは、その有効性と運用効率において際立つ、AIセキュリティに対する統合的かつ包括的なアプローチを提供します。
比類ない適応性: 静的テスト手法とは異なり、ModelRedのアダプティブ・レッドチーミングは継続的に進化し、毎月10,000を超える新しい攻撃ベクターを検出します。これにより、防御が常に最新の脅威の一歩先を行き、真に敵よりも速く適応するセキュリティを提供します。
実証済みの精度と速度: プロンプトインジェクション検出における99.2%の精度と、ジェイルブレイク防止における2.3ミリ秒の応答時間により、ModelRedは正確かつ迅速な脅威軽減を提供します。検出された脅威の99.8%を自動的にブロックし、リスクエクスポージャーを大幅に削減します。
ベンダー非依存性&統合性: ModelRedは、OpenAI、Anthropic、Azure、Googleを含む10以上の主要なAIプロバイダーをサポートし、既存のCI/CDワークフローにシームレスに統合されます。この柔軟性により、多様なモデルや環境でセキュリティを一貫して検証できます。
定量化可能なリスク削減: ModelRedを利用するチームは、手動セキュリティレビュー時間の30%削減や90日間でのリスクエクスポージャーの25%減少といった具体的なメリットを報告しており、リーダーシップ層に明確で測定可能な成果を提供しています。
結論
ModelRedは、信頼性の高いAIシステムを構築・展開するために不可欠なセキュリティインフラを提供し、安全性を損なうことなくイノベーションを推進する自信をもたらします。レッドチーミングを自動化し、継続的かつ適応的な保護を提供することで、脆弱性にプロアクティブに対処し、AIの安全性を確保できます。
More information on ModelRed
Launched
2025-06
Pricing Model
Freemium
Starting Price
$79 / month
Global Rank
Follow
Month Visit
<5k
Tech used
ModelRed was manually vetted by our editorial team and was first featured on 2025-10-10.
ModelRed 代替ソフト
もっと見る 代替ソフト-

-

-

大規模言語モデルのためのオープンソースフレームワーク、Superagentを用いて、独自のAI駆動型エージェントを構築しましょう。今日からエージェントを本番環境にデプロイし、お客様に価値を提供してください!
-
-
