
What is Relace?
複雑なタスクや大規模なコードベースに対応する、堅牢なAIコーディングシステムを構築する際、予期せぬボトルネックが生じることがよくあります。ユーザーがその限界を押し広げるにつれて、膨大なコードコンテキストを効率的に管理したり、時間とコストのかかるファイル全体の書き換えを、よりアジャイルな手法に置き換えたりといった課題に直面します。検索やコードのマージといった補助機能を含め、あらゆるステップで高性能な汎用モデルだけに頼ると、コストが急速に膨らみ、特に迅速な改善を期待する非技術系のユーザーにとっては、イライラの種となる遅延が発生する可能性があります。
Relaceは、AIコーディングワークフローにおける、こうした重要な補助タスクに対処するために特化して設計されたAIモデルを提供します。これらの特定の機能に焦点を当てることで、Relaceのモデルは、より大規模で高価なモデルを使用するよりも、速度とコスト効率の両面で大幅な改善を実現し、同時に精度を維持または向上させます。Relaceを統合して、AIコード生成プロダクトのパフォーマンスと信頼性を高めてください。
主な機能:
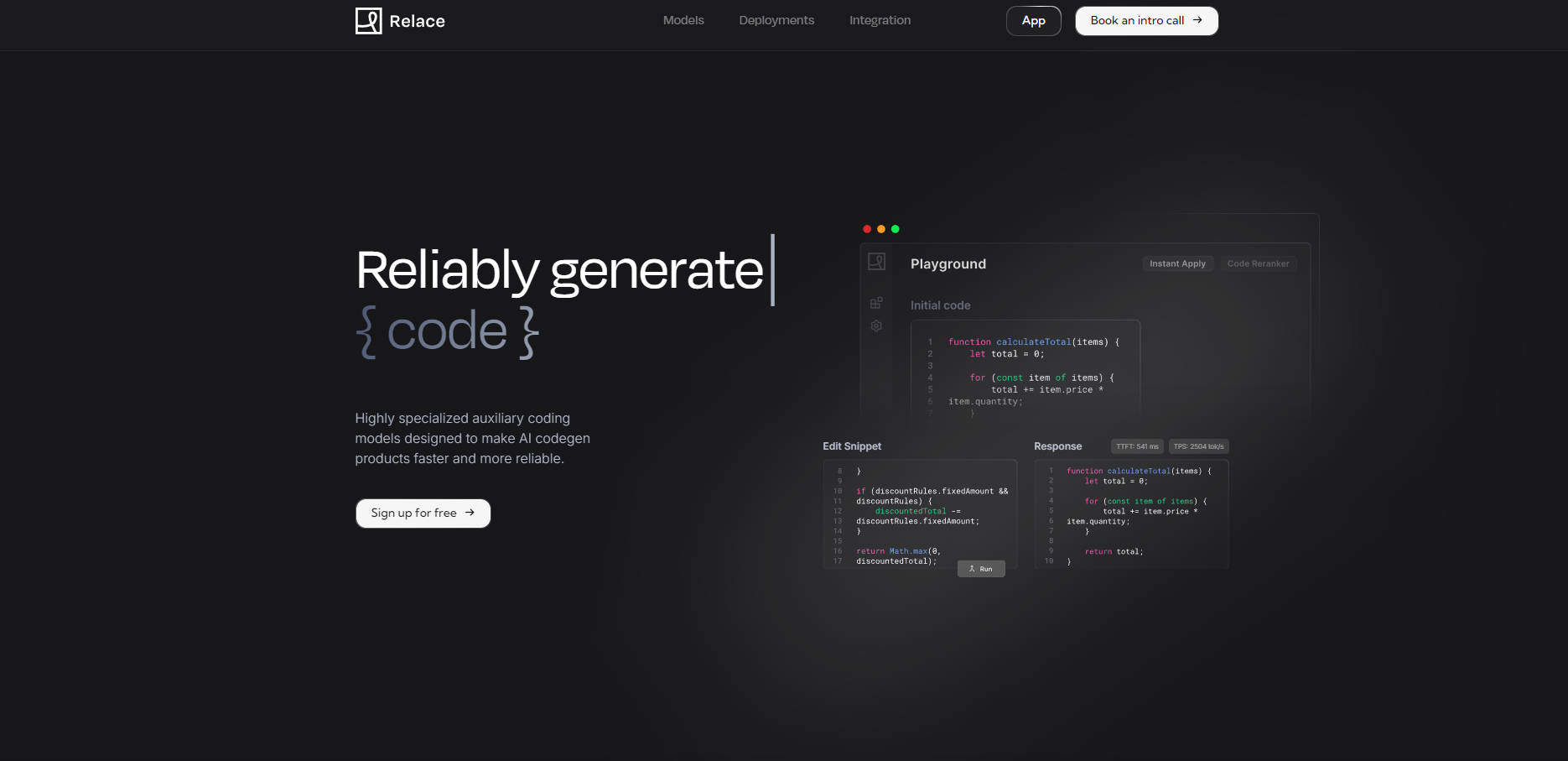
⚡️ コードマージの高速化: Instant Applyモデルは、セマンティックコードスニペットを、平均エンドツーエンドレイテンシ約900msで、毎秒2,500トークン以上でマージします。これにより、時間のかかるファイル全体の書き換えを置き換え、プロダクト内で直接、迅速かつ正確なコード修正が可能になります。
🔍 効率的なコンテキスト管理: EmbeddingsモデルとCode Rerankerモデルは、100万行規模のコードベースの中から、約1~2秒で関連性を迅速に判断します。無関係なファイルを効果的にフィルタリングすることで、入力トークンの使用量を大幅に(50%以上)削減し、コンテキストウィンドウを整理し、その後のAI生成の品質を向上させます。
📈 運用コストの削減: リソースを大量に消費する補助タスクを、高価な最先端モデルではなく、特化してコスト最適化されたモデルで処理することで、RelaceはユーザーアクションごとのAPI費用を大幅に削減します。
🎯 最先端の精度を実現: Relaceのモデルは、多様な言語にわたる数十万件のコードマージおよびクエリ-コードペアを網羅する、広範なデータセットでトレーニングされており、特定の機能において最高の精度を発揮します。
ユースケース:
大規模コードベースへの対応: EmbeddingsとRerankerを統合することで、AIエージェントが、コンテキストウィンドウの制限を超えたり、法外なコストをかけたりすることなく、大規模な数百万行規模のコードリポジトリから、関連するコンテキストを確実にナビゲートし、取得できるようにします。
迅速なコード修正の実現: Instant Applyモデルを活用して、ユーザーがAIエージェントによって生成された、小規模で的を絞ったコード編集を迅速に適用できるようにします。これにより、ファイル全体の再生成に伴う遅延とコストを回避し、反復的な変更において、コーディング体験がより軽快で応答性が高いものになります。
エージェントワークフローのコスト最適化: エージェントのループにおける検索とマージのステップにRelaceモデルを導入します。これにより、頻繁で大量のタスクを、高価な最先端モデルからオフロードし、全体的なエージェントの実行速度と信頼性を維持または向上させながら、大幅なコスト削減につながります。
結論:
Relaceは、AIコード生成における一般的なボトルネックに対する、焦点を絞った高性能なソリューションを提供します。コンテキスト検索とコードマージのための専用モデルを提供することで、Relaceは、より高速で、よりコスト効率が高く、より信頼性の高いAIコーディングプロダクトを構築できるようにします。実績のある当社のモデルを統合して、プロダクトの機能を強化し、ユーザーに優れた体験を提供してください。
More information on Relace
Launched
2024-10
Pricing Model
Free Trial
Starting Price
Global Rank
14065166
Follow
Month Visit
<5k
Tech used
Webflow,Amazon AWS CloudFront,cdnjs,Cloudflare CDN,JSDelivr,unpkg,jQuery,Gzip,HTTP/3,OpenGraph,HSTS
Top 5 Countries
74.41%
25.59%
United States
India
Traffic Sources
9.65%
1.03%
0.05%
3.95%
17.86%
67.45%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Relace was manually vetted by our editorial team and was first featured on 2025-05-16.
Related Searches
Relace 代替ソフト
もっと見る 代替ソフト-

-

-

-

-
完全な状況把握、強固なインテグレーション(連携)、そして本番運用可能な成果を携え、計画、構築、レビューを遂行するコードエージェントを展開します。 エンタープライズグレードのサポート体制も万全です。 Codegen を活用して、より迅速なリリースを実現しましょう。