
What is Relace?
Создание надежных AI-систем для кодинга, особенно предназначенных для сложных задач или крупных кодовых баз, часто приводит к возникновению неожиданных "узких мест". По мере того, как ваши пользователи расширяют границы возможного, вы сталкиваетесь с проблемами, такими как эффективное управление огромными объемами контекста кода или замена медленных и дорогостоящих полных перезаписей файлов более гибкими методами. Использование исключительно мощных моделей общего назначения на каждом этапе, включая вспомогательные функции, такие как поиск и объединение кода, может быстро увеличить затраты и привести к неприятной задержке, особенно для нетехнических пользователей, ожидающих быстрой доработки.
Relace предоставляет узкоспециализированные AI-модели, разработанные специально для решения этих важнейших вспомогательных задач в рабочем процессе AI-кодинга. Сосредоточившись на этих конкретных функциях, модели Relace обеспечивают значительное повышение как скорости, так и экономической эффективности по сравнению с использованием более крупных и дорогих моделей, при этом поддерживая или улучшая точность. Интегрируйте Relace, чтобы повысить производительность и надежность вашего продукта AI codegen.
Ключевые особенности:
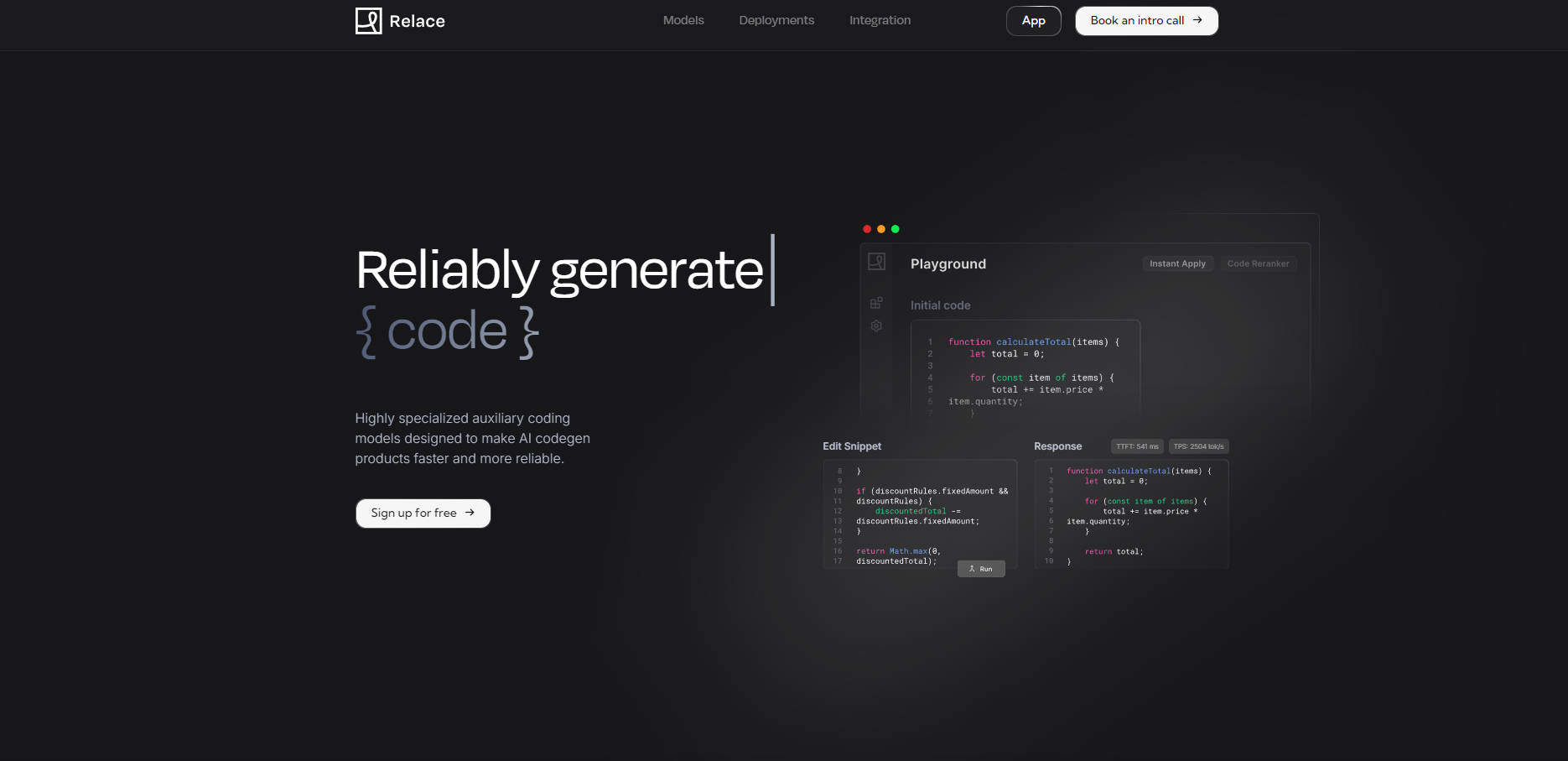
⚡️ Ускоренное объединение кода: Модель Instant Apply объединяет семантические фрагменты кода со скоростью более 2500 токенов в секунду со средней сквозной задержкой около 900 мс. Это заменяет медленные полные перезаписи файлов, позволяя быстро и точно изменять код непосредственно в вашем продукте.
🔍 Эффективное управление контекстом: Модели Embeddings и Code Reranker быстро определяют релевантность в кодовых базах, содержащих миллионы строк кода, примерно за 1-2 секунды. Эффективно фильтруя нерелевантные файлы, это значительно сокращает использование входных токенов (более чем на 50%) и очищает окно контекста, улучшая качество последующих AI-генераций.
📈 Сокращение операционных расходов: Обрабатывая ресурсоемкие вспомогательные задачи с помощью специализированных, экономически оптимизированных моделей вместо дорогостоящих моделей, Relace помогает значительно снизить расходы на API для каждого действия пользователя.
🎯 Достижение передовой точности: Обученные на обширных наборах данных, охватывающих сотни тысяч объединений кода и пар "запрос-код" на разных языках, модели Relace обеспечивают ведущую точность для своих конкретных функций.
Примеры использования:
Масштабирование для больших кодовых баз: Интегрируйте Embeddings и Reranker, чтобы ваш AI-агент мог надежно перемещаться и извлекать релевантный контекст из обширных кодовых репозиториев, содержащих миллионы строк кода, не превышая лимиты окна контекста и не неся непомерных затрат.
Обеспечение быстрой доработки кода: Используйте модель Instant Apply, чтобы позволить пользователям быстро применять небольшие, целевые изменения кода, сгенерированные вашим AI-агентом. Это позволяет избежать задержек и затрат, связанных с повторной генерацией целых файлов, что делает процесс кодирования более быстрым и отзывчивым для итеративных изменений.
Оптимизация затрат на агентский рабочий процесс: Разверните модели Relace для этапов поиска и объединения в цикле вашего агента. Это разгружает эти частые, объемные задачи с дорогостоящих моделей, что приводит к существенной экономии затрат при сохранении или улучшении скорости и надежности общего выполнения агента.
Заключение:
Relace предлагает сфокусированное, производительное решение для общих "узких мест" в AI-генерации кода. Предоставляя специализированные модели для поиска контекста и объединения кода, Relace позволяет создавать более быстрые, экономичные и надежные продукты AI-кодинга. Интегрируйте наши проверенные модели, чтобы расширить возможности вашего продукта и обеспечить превосходный опыт для ваших пользователей.
More information on Relace
Launched
2024-10
Pricing Model
Free Trial
Starting Price
Global Rank
14065166
Follow
Month Visit
<5k
Tech used
Webflow,Amazon AWS CloudFront,cdnjs,Cloudflare CDN,JSDelivr,unpkg,jQuery,Gzip,HTTP/3,OpenGraph,HSTS
Top 5 Countries
74.41%
25.59%
United States
India
Traffic Sources
9.65%
1.03%
0.05%
3.95%
17.86%
67.45%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Relace was manually vetted by our editorial team and was first featured on 2025-05-16.
Related Searches
Relace Альтернативи
Больше Альтернативи-

-

-

-

-
Развертывайте кодовых агентов, которые планируют, разрабатывают и проводят ревью, располагая полным контекстом, надежными интеграциями и выдавая готовые к внедрению результаты. При поддержке корпоративного уровня. Ускорьте выпуск продуктов с Codegen.